📔설명
NL 조인, 소트 머지 조인, 해시 조인, 스칼라 서브 쿼리, 고급 조인 기법에 대해 알아보자
🍥NL 조인
1. 기본 메커니즘
중첩 루프문(Nested Loop)의 수행구조와 동일
begin
for outer in (select deptno, empno, rpad(ename,10) ename from emp)
loop -- outer 루프
for inner in (select dname from dept where deptno=outer.deptno)
loop -- inner 루프
dbms_output.put_line(outer.empno||' : '||outer.ename||' : '||inner.dname);
end loop;
end loop;
end;위의 PL/SQL 문은 아래 쿼리와 100% 같은 순서로 데이터를 액세스하고, 데이터 출력 순서도 같다.
=> 내부적으로 쿼리를 Recursive 하게 반복 수행하지 않는다는 점만 다름
--oracle
select /*+ ordered use_nl(d) */ e.empno, e.ename, d.dname
from emp e, dept d
where d.deptno=e.deptno;
select /*+ leading(e) use_nl(d) */ e.empno, e.ename, d.dname
from emp e, dept d
where d.deptno=e.deptno;
--sql server
select e.empno, e.ename, d.dname
from emp e inner loop join dept d on d.deptno=e.deptno
option (force order)
select e.empno, e.ename, d.dname
from emp e, dept d
where d.deptno=e.deptno
option (force order, loop join)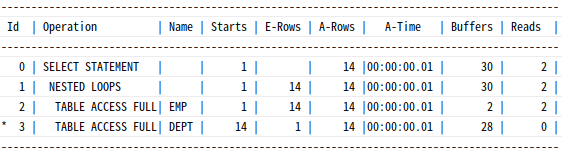
소트 머지 조인과 해시 조인도 각각 소트 영역과 해시 영역에 가공해 둔 데이터를 이용한다는 점만 다르고, 기본적인 조인 프로세싱은 동일
2. NL 조인 수행 과정 분석
select /*+ ordered use_nl(d) */
e.empno, e.ename, d.dname, e.job, e.sal
from dept d, emp e
where d.deptno=e.deptno --1
and d.loc='SEOUL' --2
and d.gb='2' --3
and e.sal>=1500 --4
order by sal desc;
--인덱스
#pk_dept : dept.deptno
#dept_loc_idx : dept.loc
#pk_emp : emp.empno
#emp_deptno_idx : emp.deptno
#emp_sal_idx : emp.salExecution Plan
---------------------------------------------------
0 SELECT STATEMENT
1 0 SORT ORDER BY
2 1 NESTED LOOPS
3 2 TABLE ACCESS BY INDEX ROWID DEPT
4 3 INDEX RANGE SCAN DEPT_LOC_IDX
5 2 TABLE ACCESS BY INDEX ROWID EMP
6 5 INDEX RANGE SCAN EMP_DEPTNO_IDX사용된 인덱스 : dept_loc_idx와 emp_deptno_idx
조건비교 순서 : 2->3->1->4
dept_loc_idx인덱스 범위 스캔 (ID=4)- 인덱스 rowid로
dept 테이블 액세스(ID=3) emp_deptno_idx인덱스 범위 스캔 (ID=6)- 인덱스 rowid로
emp 테이블 액세스(ID=5) - sal 기준
내림차순정렬 (ID=1)
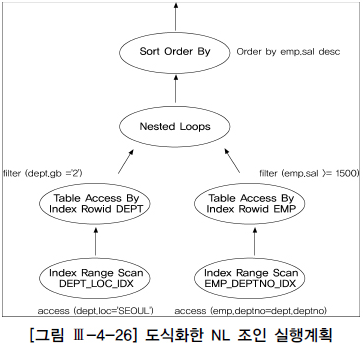
각 단계를 완료하고 나서 다음 단계로 넘어가는 것이 아니라 한 레코드씩 순차적으로 진행
=> order by 는 전체 집합을 대상으로 정렬하기 때문에 작업을 모두 완료하고서 다음 오퍼레이션 진행
StmtText
-------------------------------------------------------------
|--Sort(ORDER BY:([e].[sal] DESC))
|--Filter(WHERE:([emp].[sal] as [e].[sal]>=(1500)))
|--Nested Loops(Inner Join, OUTER REFERENCES:([Bmk1003]))
|--Nested Loops(Inner Join, OUTER REFERENCES:([d].[deptno]))
| |--Filter(WHERE:([dept].[gb] as [d].[gb]='2'))
| | |--Nested Loops(Inner Join, OUTER REFERENCES:([Bmk1000]))
| | |--Index Seek(OBJECT:([dept].[dept_loc_idx] AS [d]), SEEK:([loc]='CHICAGO') )
| | |--RID Lookup(OBJECT:([dept] AS [d]), SEEK:([Bmk1000]=[Bmk1000]) )
| |--Index Seek(OBJECT:([emp].[emp_deptno_idx]), SEEK:([e].[deptno]=[dept].[deptno]))
|--RID Lookup(OBJECT:([emp] AS [e]), SEEK:([Bmk1003]=[Bmk1003]) LOOKUP ORDERED FORWARD)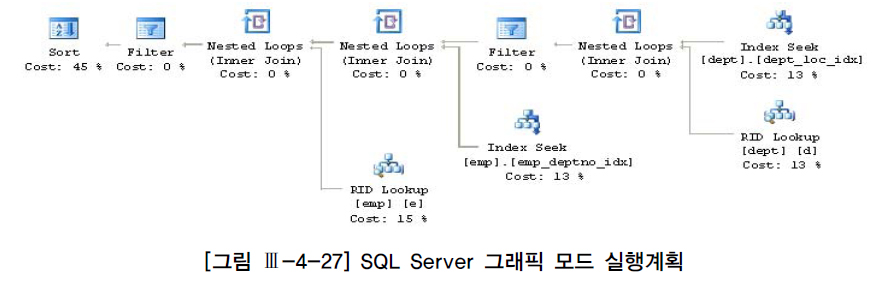
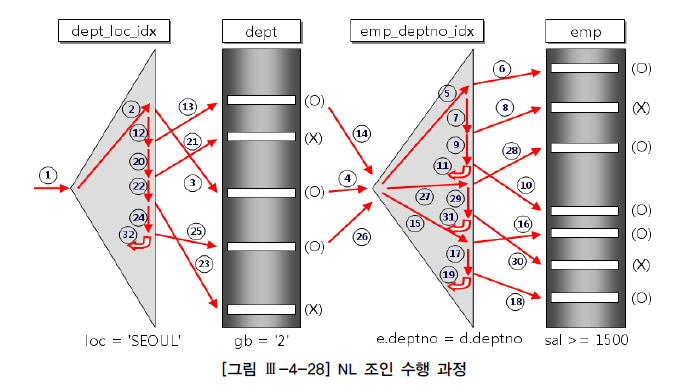
- 11, 19, 31, 32는
스캔할 데이터가 더 있는지 확인하는one-plus 스캔표시 dept_loc_idx를스캔하는 양에 따라전체 일량 좌우- 첫 번째 부하지점 : 인덱스를 통해
dept 테이블 랜덤 액세스 - 두 번째 부하지점 :
emp_deptno_idx 인덱스탐색하는 부분 (조인 액세스),랜덤 액세스 - 세 번째 부하지점 : 인덱스를 통해
emp 테이블 랜덤 액세스
3. NL 조인의 특징
랜덤 액세스 위주의 조인 방식
=> 인덱스 구성이 아무리 완벽하더라도대량의 데이터조인시 매우 비효율적- 조인을
한 레코드씩 순차적으로 진행
=> 아무리대용량 집합이라도부분범위처리가 가능한 상황에서 매우극적인 응답 속도낼 수 있음
=>먼저 액세스되는 테이블의 처리 범위에 의해전체 일량이 결정 - 다른 조인 방식과 비교했을 때
인덱스 구성 전략이 특히 중요
NL 조인은 소량의 데이터를 주로 처리하거나 부분범위처리가 가능한 온라인 트랜잭션 환경에 적합
4. NL 조인 확장 메커니즘
NL 조인의 성능을 높이기 위해 테이블 Prefetch, 배치 I/O 기능 도입
=> 테이블 Prefetch : 인덱스를 이용해 테이블을 액세스하다가 디스크 I/O가 필요해지면, 이어서 곧 읽게 될 블록까지 미리 읽어서 버퍼 캐시에 적재하는 기능
=> 배치 I/O : 디스크 I/O Call을 미뤘다가 읽을 블록이 일정량 쌓이면 한꺼번에 처리하는 기능
두 기능 모두 건건이 I/O Call을 발생시키는 비효율을 줄이기 위해 고안
전통적인 실행계획
Rows Row Source Operation
---------------------------------
5 NESTED LOOPS
3 TABLE ACCESS BY INDEX ROWID OF 사원
5 INDEX RANGE SCAN OF 사원_x1
5 TABLE ACCESS BY INDEX ROWID OF 고객
8 INDEX RANGE SCAN OF 고객_X1테이블 Prefetch 실행계획
Rows Row Source Operation
---------------------------------
5 TABLE ACCESS BY INDEX ROWID OF 고객
12 NESTED LOOPS
3 TABLE ACCESS BY INDEX ROWID OF 사원
3 INDEX RANGE SCAN OF 사원X_1
8 INDEX RANGE SCAN OF 고객_X1배치 I/O 실행계획
Rows Row Source Operation
---------------------------------
5 NESTED LOOPS
8 NESTED LOOPS
3 TABLE ACCESS BY INDEX ROWID OF 사원
3 INDEX RANGE SCAN OF 사원_x1
8 INDEX RANGE SCAN OF 고객_X1
5 TABLE ACCESS BY INDEX ROWID OF 고객 🥮소트 머지 조인
NL 조인은 조인 칼럼을 선두로 갖는 인덱스가 있는지가 매우 중요
=> 없으면 Outer 테이블에서 읽히는 건마다 Inner 테이블 전체를 스캔하기 때문
소트 머지 조인(Sort Merge Join) : 두 테이블을 각각 정렬한 다음 두 집합을 머지(Merge)하면서 조인 수행
소트 단계: 양쪽 집합을조인 칼럼 기준으로정렬머지 단계: 정렬된 양쪽 집합을서로 머지(merge)
조인 칼럼에 인덱스가 있으면(Oracle은 Outer 테이블만 해당), 1번 소트 단계를 거치지 않고 곧바로 조인 가능
SQL Server는 조인 연산자가 =일 때만 소트 머지 조인 수행
1. 기본 메커니즘
--oracle
select /*+ ordered use_merge(e) */ d.deptno, d.dname, e.empno, e.ename
from dept d, emp e
where d.deptno = e.deptno;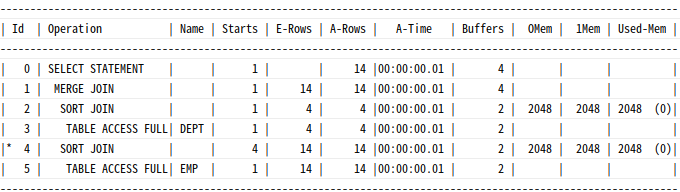
--sql server
select d.deptno, d.dname, e.empno, e.ename
from dept d, emp e
where d.deptno = e.deptno
option (force order, merge join)StmtText
-------------------------------------------------------------
|--Merge Join(Inner Join, MANY-TO-MANY MERGE:([d].[deptno])=([e].[deptno]))
|--Sort(ORDER BY:([d].[deptno] ASC))
| |--Table Scan(OBJECT:([SQLPRO].[dbo].[dept] AS [d]))
|--Sort(ORDER BY:([e].[deptno] ASC))
|--Table Scan(OBJECT:([SQLPRO].[dbo].[emp] AS [e]))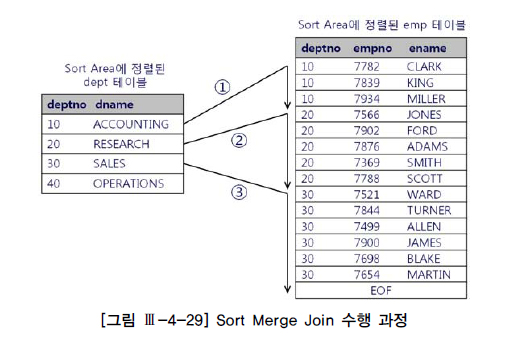
Inner 집합인 emp 테이블이 정렬돼 있기 때문에 조인에 실패하는 레코드를 만나는 순간 멈출 수 있음
=> deptno=10인 레코드를 찾기 위해 1번 스캔을 하다가 20을 만나는 순간 멈춤
=> 스캔 시작점을 찾으려고 매번 탐색X, deptno=20인 레코드를 찾는 2번 스캔은 1번 스캔에서 멈춘 지점을 기억했다가 거기서 부터 시작하면 됨
=> Outer 집합인 dept 테이블도 같은 순서로 정렬돼 있으므로 가능
Outer 집합(정렬된 dept)에서 첫 번째 로우 o를 가져온다.
Inner 집합(정렬된 emp)에서 첫 번째 로우 i를 가져온다.
loop
양쪽 집합 중 어느 것이든 끝에 도달하면 loop를 빠져나간다.
if o = i 이면
조인에 성공한 로우를 리턴한다.
inner 집합에서 다음 로우 i를 가져온다.
else if o < i 이면
outer 집합에서 다음 로우 o를 가져온다.
else (즉, o > i 이면)
inner 집합에서 다음 로우 i를 가져온다.
end if
end loop2. 소트 머지 조인의 특징
-
조인 하기 전에
양쪽 집합을정렬
=>NL 조인은 정렬 없이Outer 집합을 한 건씩 차례대로 조인을 진행하지만,소트 머지 조인은 양쪽 집합을 조인 칼럼 기준으로정렬한 후에 조인 시작 -
부분적으로부분범위처리가 가능
=>Outer 집합이조인 칼럼 순으로미리 정렬된 상태에서 사용자가일부 로우만 fetch하다가멈춘다면Outer 집합은끝까지 읽지 않아도 됨 -
테이블별
검색 조건에 의해전체 일량이 좌우
=>NL 조인은Outer 집합의 건마다Inner 집합을 탐색하지만,소트 머지 조인은 두 집합을각각 정렬한 후에 조인함으로각 집합의 크기, 즉테이블별 검색 조건에 의해 전체 일량 좌우 -
스캔 위주의 조인 방식
=>NL 조인이랜덤 액세스 위주의 조인 방식이라면,소트 머지 조인은스캔 위주의 조인 방식이다.Inner 테이블을반복 액세스하지 않으므로머지 과정에서랜덤 액세스 발생X
=>각 테이블 검색 조건에 해당하는대상 집합을 찾을 때인덱스를 이용한랜덤 액세스 방식으로 처리될 수 있고, 이때 발생량이 많다면 소트 머지 조인 이점 사라짐
🍢해시 조인
1. 기본 메커니즘
해시 조인(Hash Join) : NL 조인이나 소트 머지 조인이 효과적이지 못한 상황 해결하고자 나온 방식
--oracle
select /*+ ordered use_hash(e) */ d.deptno, d.dname, e.empno, e.ename
from dept d, emp e
where d.deptno = e.deptno 
--SQL Server
select d.deptno, d.dname, e.empno, e.ename
from dept d, emp e
where d.deptno = e.deptno
option (force order, hash join)
StmtText
-------------------------------------------------------------
|--Hash Match(Inner Join, HASH:([d].[deptno])=([e].[deptno]))
|--Table Scan(OBJECT:([SQLPRO].[dbo].[dept] AS [d]))
|--Table Scan(OBJECT:([SQLPRO].[dbo].[emp] AS [e]))해시 조인은 둘 중 작은 집합(Build Input)을 읽어 해시 영역(Hash Area)에 해시 테이블(=해시 맵)을 생성하고, 반대쪽 큰 집합(Probe Input)을 읽어 해시 테이블 탐색하며 조인
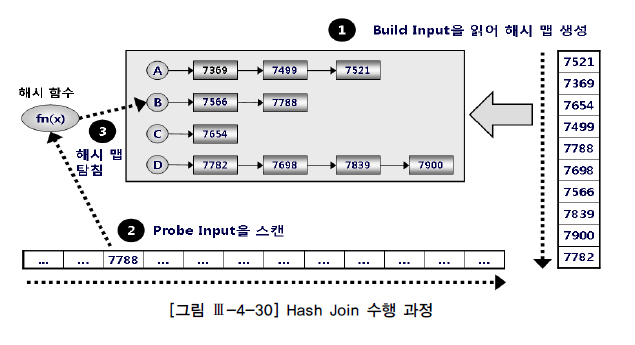
- 1단계 :
해시 테이블생성.집합중작다고 판단되는집합을 읽어해시 테이블만듦.해시 테이블만들 때해시 함수사용.해시 함수에서 리턴받은해시 값이같은 데이터를 같은해시 버킷에체인(연결 리스트)으로 연결 - 2단계 :
Probe Input을 스캔. 해시 테이블 생성을 위해 선택되지 않은 나머지데이터 집합(Probe Input)을 스캔 - 3단계 :
해시 테이블탐색.Probe Input에서 읽은 데이터로 해시 테이블 탐색 시에도해시 함수사용.해시 함수에서 리턴받은버킷 주소로 찾아가해시 체인을 스캔하면서 데이터 찾음
해시 조인은 NL조인처럼 조인 과정에서 발생하는 랜덤 액세스 부하가 없고, 소트 머지 조인처럼 조인 전에 미리 양쪽 집합을 정렬하는 부담 X
=> 해시 테이블 생성하는 비용 수반
=> Build Input이 작을 때 효과적
=> Hash Build를 위해 가용 한 메모리 공간을 초과할 정도로 Build Input이 대용량 테이블이면 디스크에 썼다가 다시 읽어들이는 과정을 거쳐 성능 저하
해시 키 값으로 사용되는 칼럼에 중복 값이 거의 없을 때 효과적
해시 테이블을 만드는 단계는 전체범위처리가 불가피하지만, 반대쪽 Probe Input을 스캔하는 단계는 NL조인 처럼 부분범위처리 가능
2. Build Input이 가용 메모리 공간을 초과할 때 처리 방식
만약 In-Memory 해시 조인이 불가능할 때 DBMS는 Grace 해시 조인이라고 알려진 조인 알고리즘 사용
=> 두 단계로 나눠 진행
파티션 단계
조인되는 양쪽 집합(조인 이외 조건절 만족하는 레코드) 모두 조인 칼럼에 해시 함수를 적용하고, 반환된 해시 값에 따라 동적 파티셔닝 실시.
독립적으로 처리할 수 있는 여러 개의 작은 서브 집합으로 분할함으로써 파티션 짝(Pair)을 생성하는 단계
파티션 단계에서 양쪽 집합을 모두 읽어 디스크 상의 Temp 공간에 저장해야 하므로 In-Memory 해시 조인보다 성능 크게 떨어짐
조인 단계
각 파티션 짝(Pari)에 대해 하나씩 조인 수행. 이때 각각에 대한 Build Input과 Probe Input은 독립적으로 결정, 즉 파티션하기 전 어느 쪽이 작은 테이블이었는지에 상관없이 각 파티션 짝(pair)별로 작은 쪽 파티션을 Build Input으로 선택해 해시 테이블 생성
해시 테이블 생성 후, 반대 쪽 파티션 로우를 하나씩 읽으며 해시 테이블 탐색, 모든 파티션 짝에 대한 처리가 완료될 때까지 반복
Grace 해시 조인은 한마디로 분할/정복(Divide & Conquer) 방식
Recursive 해시 조인(=Nested-loops 해시 조인)
Recursive 해시 조인 : 디스크에 기록된 파티션 짝끼리 조인을 수행하려고 작은 파티션을 메모리에 로드하는 과정에서 또다시 가용 메모리를 초과하는 경우, 추가적인 파티셔닝 단계를 거치는 것
3. Build Input 해시 키 값에 중복이 많을 때 발생하는 비효율
해시 알고리즘의 성능은 해시 충돌(다른 입력값에 대한 출력값이 같은 것)을 얼마나 최소화할 수 있느냐에 달림
=> 방지하기 위해선 많은 해시 버킷을 할당해야 함
=> DBMS는 가능하면 충분히 많은 개수의 버킷을 할당함으로써 버킷 하나당 하나의 키 값만 갖게 하려고 노력
해시 버킷을 아무리 많이 할당하더라도 해시 테이블에 저장할 키 칼럼에 중복 값이 많다면 하나의 버킷에 많은 엔트리가 달릴 수 밖에 없음
=> 해시 버킷을 아무리 빨리 찾아도 해시 버킷을 스캔하는 단계에서 많은 시간 허비하므로 탐색 속도 저하
4. 해시 조인 사용기준
해시 조인 성능을 좌우하는 두 가지 포인트
한 쪽 테이블이 가용 메모리에 담길 정도로충분히 작아야 함Build Input 해시 키 칼럼에중복 값이 거의 없어야 함
해시 조인을 언제 사용하는 것이 효과적인가
조인 칼럼에 적당한인덱스가 없어NL 조인이 비효율적일 때- 조인 칼럼에 인덱스가 있더라도
NL 조인 드라이빙 집합에서Inner 쪽 집합으로의조인 액세스량이 많아랜덤 액세스 부하가 심할 때 소트 머지 조인하기에는두 테이블이 너무 커소트 부하가 심할 때수행빈도가낮고쿼리 수행 시간이오래 걸리는대용량 테이블을 조인할 때
=>OLAP,DW,배치 프로그램
수행시간이 짧으면서 수행빈도가 매우 높은 쿼리 (OLTP)를 해시 조인으로 처리한다면, NL 조인에 사용되는 인덱스는 영구적으로 유지되면서 다양한 쿼리를 위해 공유 및 재사용되지만, 해시 테이블은 단 하나의 쿼리를 위해 생성하고 조인이 끝나면 바로 소멸함
=> CPU와 메모리 사용률을 크게 증가시킴은 물론, 메모리 자원 확보를 위해 각종 래치 경합이 발생해 시스템 동시성 저하 가능
🧆스칼라 서브 쿼리
서브쿼리 : 쿼리에 내장된 또 다른 쿼리 블록
스칼라 서브 쿼리(Scalar Subquery) : 함수처럼 한 레코드당 정확히 하나의 값만을 리턴하는 서브쿼리
=> 주로 Select 절에 사용
=> 칼럼이 올 수 있는 대부분의 위치에서 사용 가능
select empno, ename, sal, hiredate ,
(select d.dname from dept d where d.deptno = e.deptno) dname
from emp e
where sal >= 2000
--동일
-- dept와 조인에 실패하는 emp 레코드가 있을 경우 dname으로 null값이 출력
select /*+ ordered use_nl(d) */ e.empno, e.ename, e.sal, e.hiredate, d.dname
from emp e right outer join dept d
on d.deptno = e.deptno
where e.sal >= 20001. 스칼라 서브 쿼리의 캐싱 효과
스칼라 서브 쿼리를 사용하면 내부적으로 캐시를 생성하고, 여기에 서브쿼리에 대한 입력 값과 출력 값을 저장
=> 메인쿼리로부터 같은 입력 값이 들어오면 서브쿼리를 실행하는 대신 캐시된 출력 값을 리턴
=> 캐시에서 찾지 못할 때만 쿼리 수행, 결과는 버리지 않고 캐시에 저장
select empno, ename, sal, hiredate
, (select d.dname --출력 값 : d.dname
from dept d
where d.deptno=e.empno --입력 값 : e.empno)
from emp e
where sal >= 2000;해싱 알고리즘을 사용하므로 입력 값 종류가 소수여서 해시 충돌 가능성이 적은 때여야 캐싱 효과 얻을 수 있음
=> 반대면 캐시 확인 비용 때문에 오히려 성능 저하
2. 두 개 이상의 값을 리턴하고 싶을 때
-- 사원 테이블 전체를 읽어야 하는 비효율이 있음 (11g 이후로 조인 조건 Pushdown 기능 작동시 괜찮음)
select d.deptno, d.dname, avg_sal, min_sal, max_sal
from dept d right outer join
(select deptno, avg(sal) avg_sal, min(sal) min_sal, max(sal) max_sal
from emp group by deptno) e
on e.deptno=d.deptno
where d.loc='CHICAGO';구하고자 하는 값들을 모두 결합하고, 바깥에서 substr 함수로 분리
--oracle
select deptno, dname
, to_number(substr(sal,1,7)) as avg_sal
, to_number(substr(sal,8,7)) as min_sal
, to_number(substr(sal,15)) as max_sal
from (
select d.deptno, d.dname
,(select lpad(avg(sal),7) || lpad(min(sal),7) || max(sal)
from emp where deptno=d.deptno) sal
from dept d
where d.loc='CHICAGO'
)
--sql server
select deptno, dname
, cast(substring(sal, 1, 7) as float) avg_sal
, cast(substring(sal, 8, 7) as int) min_sal
, cast(substring(sal, 15, 7) as int) max_sal
from ( select d.deptno, d.dname
,(select str(avg(sal), 7, 2) + str(min(sal), 7) + str(max(sal), 7)
from emp where deptno = d.deptno) sal
from dept d
where d.loc = 'CHICAGO'
) x3. 스칼라 서브 쿼리 Unnesting
오라클 12c부터 스칼라 서브 쿼리도 Unnesting 가능
=> 옵티마이저가 사용자 대신 자동으로 쿼리 변환
=> NL 조인이 아닌 해시 조인으로 실행될 수 있는 이유는 Unnesting됐기 때문
select c.고객번호, c.고객명
,(select /*+unnest*/ round(avg(거래금액),2) 평균거래금액
from 거래
where 거래일시 >= trunc(sysdate,'mm')
and 고객번호 = c.고객번호)
from 고객 x
where c.가입일시 >= trunc(add_months(sysdate,-1),'mm');
------------------------------------
Execution Plan
------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS
1 0 HASH JOIN (OUTER)
2 1 TABLE ACCESS(FULL) OF '고객' (TABLE)
3 1 VIEW OF 'SYS.VW_SSQ_1' (VIEW) (Cost=4)
4 3 HASH (GROUP BY)
5 4 TABLE ACCESS(FULL) OF '거래' (TABLE) -- unnest와 merge 힌트를 같이 사용했을 때
------------------------------------
Execution Plan
------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=7 Card=15 Bytes=405)
1 0 HASH (GROUP BY) (Cost=7 Card=15 Bytes=405)
2 1 HASH JOIN (OUTER) (Cost=6 Card=15 Bytes=405)
3 2 TABLE ACCESS(FULL) OF '고객' (TABLE) (Cost=3 Card=4 Bytes=80)
4 2 TABLE ACCESS(FULL) OF '거래' (TABLE) (Cost=3 Card=14 Bytes=98)🥘고급 조인 기법
1. 인라인 뷰 활용
1:M 관계인 테이블 끼리 조인하면, 조인 결과는 M쪽 집합과 같은 단위
=> 1쪽 집합 단위로 그룹핑해야 한다면, M쪽 집합을 먼저 1쪽 단위로 그룹핑하고 나서 조인하는 것이 유리
=> 조인 횟수를 줄여주기 때문인데, 이 처리를 위해 인라인 뷰 사용
-- 상품별 판매수량과 판매금액 집계(2009)
select min(t2.상품명) 상품명, sum(t1.판매수량) 판매수량, sum(t1.판매금액) 판매금액
from 일별상품판매 t1, 상품 t2
where t1.판매일자 between '20090101' and '20091231'
and t1.상품코드=t2.상품코드
group by t2.상품코드
Call Count CPU Time Elapsed Time Disk Query Current Rows
---- ---- ------- --------- ---- ---- ---- ----
Parse 1 0.000 0.000 0 0 0 0
Execute 1 0.000 0.000 0 0 0 0
Fetch 101 5.109 13.805 52744 782160 0 1000
---- ---- ------- --------- ---- ---- ---- ----
Total 103 5.109 13.805 52744 782160 0 1000
-----------------------------------------------------------------------------
Rows Row Source Operation
-----------------------------------------------------------------------------
1000 SORT GROUP BY (cr=782160 pr=52744 pw=0 time=13804391 us)
365000 NESTED LOOPS (cr=782160 pr=52744 pw=0 time=2734163731004 us)
365000 TABLE ACCESS FULL 일별상품판매 (cr=52158 pr=51800 pw=0 time=456175026878 us)
365000 TABLE ACCESS BY INDEX ROWID 상품 (cr=730002 pr=944 pw=0 time=872397482545 us)
365000 INDEX UNIQUE SCAN 상품_PK (cr=365002 pr=4 pw=0 time=416615350685 us)일별상품판매 테이블로부터 읽힌 36만5천개 레코드 마다 상품테이블과 조인 시도
=> 조인 과정에서 73만개의 블록 I/O 가 발생했고 총 소요시간은 13초
-- 상품코드별로 먼저 집계하고서 조인
select t2.상품명, t1.판매수량, t1.판매금액
from (
select 상품코드, sum(판매수량) 판매수량, sum(판매금액) 판매금액
from 일별상품판매
where 판매일자 between '20090101' and '20091231'
group by 상품코드
) t1, 상품 t2
where t1.상품코드=t2.상품코드;
Call Count CPU Time Elapsed Time Disk Query Current Rows
--- ----- -------- --------- ---- ---- ----- ----
Parse 1 0.000 0.000 0 0 0 0
Execute 1 0.000 0.000 0 0 0 0
Fetch 101 1.422 5.540 51339 54259 0 1000
--- ----- -------- --------- ---- ---- ----- ----
Total 103 1.422 5.540 51339 54259 0 1000
-----------------------------------------------------------------------------
Rows Row Source Operation
-----------------------------------------------------------------------------
1000 SORT GROUP BY (cr=54259 pr=51339 pw=0 time=5540320 us)
1000 VIEW (cr=52158 pr=51339 pw=0 time=5531294 us)
1000 SORT GROUP BY (cr=52158 pr=51339 pw=0 time=5531293 us)
365000 TABLE ACCESS FULL 일별상품판매 (cr=52158 pr=51339 pw=0 time=2920041 us)
1000 TABLE ACCESS BY INDEX ROWID 상품 (cr=2101 pr=0 pw=0 time=8337 us)
1000 INDEX UNIQUE SCAN 상품_PK (cr=1101 pr=0 pw=0 time=3747 us)상품코드별로 집계한 결과건수가 1000건 이므로 상품 테이블과의 조인도 1000번만 발생했으며, 발생한 블록I/O는 2101개이며 수행 시간도 5초이다.
2. 배타적 관계의 조인
상호배타적(Exclusive OR) 관계 : 엔터티가 두 개 이상의 다른 엔터티의 합집합과 관계를 갖는 것
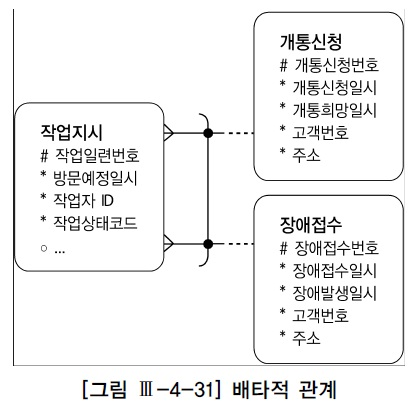
작업지시 테이블은 두 가지 방법 중 하나를 사용
개통신청번호와장애접수번호두 칼럼을 따로 두고, 레코드별로 둘 중 하나의 칼럼에만 값 입력작업구분과접수번호칼럼을 두고 작업구분이 1일때는 개통신청번호를 입력하고, 2일 때는 장애접수번호를 입력
--1번 방법
select /*+ orderd use_nl(b) use_nl(c) */ *
a.작업일련번호, a.작업자ID, a.작업상태코드
,nvl(b.고객번호,c.고객번호) 고객번호
,nvl(b.주소,c.주소) 주소
from 작업지시 a, 개통신청 b, 장애접수 c
where a.방문예정일시 between :방문예정일시1 and :방문예정일시2
and b.개통신청번호(+) = a.개통신청번호
and c.장애접수번호(+) = a.장애접수번호;--2번 방법
select x.작업일련번호, x.작업자id, x.작업상태코드, y.고객번호, y.주소
from 작업지시 x, 개통신청 y
where x.방문예정일시 between :방문예정일시1 and :방문예정일시2
and x.작업구분='1'
and y.개통신청번호 = x.접수번호
union all
select x.작업일련번호, x.작업자id, x.작업상태코드, y.고객번호, y.주소
from 작업지시 x, 장애접수 y
where x.방문예정일시 between :방문예정일시1 and :방문예정일시2
and x.작업구분='2'
and y.장애접수번호 = x.접수번호작업구분+방문예정일시로 인덱스를 구성하면 범위에 중복은 없다. 그러나 방문예정일시+작업구분으로 인덱스를 구성한다면, 스캔 범위에 중복이 생긴다.
--비효율 제거
select /*+ordered use_nl(b) use_nl(c)*/
a.작업일련번호, a.작업자id, a.작업상태코드
,nvl(b.고객번호, c.고객번호) 고객번호
,nvl(b.주소, c.주소) 주소
from 작업지시 a, 개통신청 b, 장애접수 c
where a.방문예정일시 between :방문예정일시1 and :방문예정일시2
and b.개통신청번호(+) = decode(a.작업구분,'1',a.접수번호)
and c.장애접수번호(+) = decode(a.작업구분,'2',a.접수번호);3. 부등호 조인
누적매출(running total)을 구할 땐 between, like, 부등호 같은 연산자로 조인
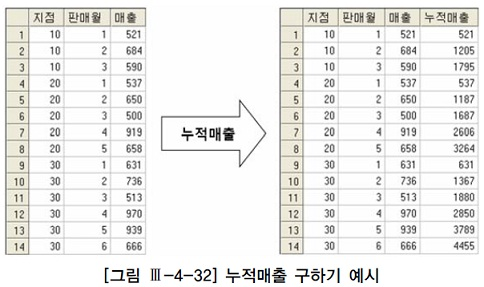
--윈도우 함수 이용
select 지점, 판매월, 매출,
sum(매출) over (partition by 지점 order by 판매월
range between unbounded preceding and current row)매출
from 월별지점매출;--윈도우 함수 지원X시
select t1.지점, t1.판매월, min(t1.매출) 매출, sum(t2.매출) 누적매출
from 월별지점매출 t1, 월별지점매출 t2
where t2.지점 = t1.지점
and t2.판매월 <= t1.판매월
group by t1.지점, t1.판매월
order by t1.지점, t1.판매월;4. Between 조인
선분이력이란?
점이력 : 고객별연체금액 변경이력을 관리할 때 이력의 시작시점만 관리하는 것
선분이력 : 시작시점과 종료시점을 함께 관리
=> 가장 마지막 이력의 종료일자는 항상 99991231로 입력해두어야 함
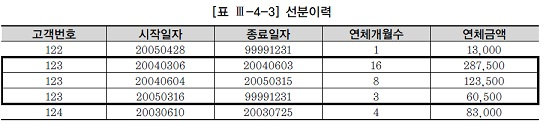

이력을 선분형태로 관리하면 쿼리가 간단해지는 것이 장점
-- 123번의 2004년 8월 15일 시점 이력 조회
select 고객번호, 연체금액, 연체개월수
from 고객별연체금액
where 고객번호='123'
and '20040815' between b.시작일자 and b.종료일자;점이력으로 관리할 때 쿼리
select 고객번호, 연체금액, 연체개월수
from 고객별연체금액 a
where 고객번호='123'
and 연체변경일자 = (select max(연체변경일자)
from 고객별연체금액
where 고객번호=a.고객번호
and 변경일자 <= '20040815');선분이력은 이력이 추가될 때마다 기존 최종 이력의 종료일자(종료일시)도 같이 변경해 주어야 하는 불편함과, 이 때문에 생기는 DML 부하 고려해야 함
일반적으로 PK를 마스터 키+종료일자+시작일자로 구성하는데, 이력을 변경할 때마다 PK 값을 변경하는 셈이어서 설계상 맞지 않는다는 지적 받음
개체 무결성을 완벽히 보장하기 어려움
선분이력 기본 조회 패턴
과거, 현재, 미래 임의 시점을 모두 조회
select 연체개월수, 연체금액
from 고객별연체금액
where 고객번호 = :cust_num
and :dt between 시작일자 and 종료일자현재 시점 조회
select 연체개월수, 연체금액
from 고객별연체금액
where 고객번호 = :cust_num
and 종료일자 = '99991231'선분이력 테이블에 정보를 미리 입력해 두는 경우가 종종 있고, 그럴 땐 현재 시점을 위처럼 조회해선 안된다.
=> ex. 고객별 연체변경이력을 지금 등록하지만, 그 정보의 유효 시작일자가 내일일 수 있음
select 연체개월수, 연체금액
from 고객별연체금액
where 고객번호 = :cust_num
and to_char(sysdate,'yyyymmdd') between 시작일자 and 종료일자
--sql server
and convert(varchar(8), getdate(), 112) between 시작일자 and 종료일자선분이력 조인
과거, 현재, 미래의임의 시점 조회
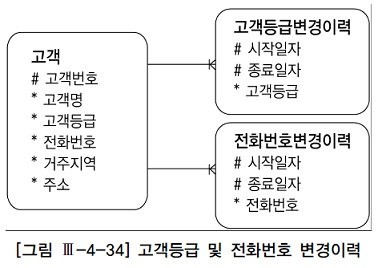
-- 특정 시점 데이터 조회
select c.고객번호, c.고객명, c1.고객등급, c2.전화번호
from 고객 c, 고객등급변경이력 c1, 전화번호변경이력 c2
where c.고객번호 =:cust_num
and c1.고객번호=c.고객번호
and c2.고객번호=c.고객번호
and :dt between c1.시작일자 and c1.종료일자
and :dt between c2.시작일자 and c2.종료일자현재 시점 조회
select c.고객번호, c.고객명, c1.고객등급, c2.전화번호
from 고객 c, 고객등급변경이력 c1, 전화번호변경이력 c2
where c.고객번호 =:cust_num
and c1.고객번호=c.고객번호
and c2.고객번호=c.고객번호
and c1.종료일자='99991231'
and c2.종료일자='99991231'
-- 미래 시점 데이터를 미리 입력하는 예약 기능이 있다면..
select c.고객번호, c.고객명, c1.고객등급, c2.전화번호
from 고객 c, 고객등급변경이력 c1, 전화번호변경이력 c2
where c.고객번호 =:cust_num
and c1.고객번호=c.고객번호
and c2.고객번호=c.고객번호
and to_char(sysdate,'yyyymmdd') between c1.시작일자 and c1.종료일자
and to_char(sysdate,'yyyymmdd') between c2.시작일자 and c2.종료일자Between 조인
지금까진 선분이력 조건이 상수였다. 즉, 조회 시점이 정해져 있었다.
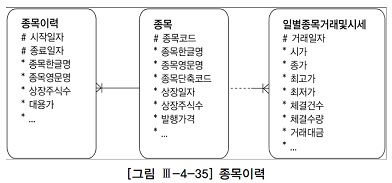
일별종목거래및시세와 같은 일별 거래 테이블로부터 읽히는 미지의 거래일자 시점으로 선분이력(종목이력)을 조회할 경우 between 조인 이용
-- 주식시장에서 과거 20년동안 당일 최고가로 장을 마친 종목 조회
select a.거래일자, a.종목코드, b.종목한글명, b.종목영문명, b.상장주식수
,a.시가, a.종가, a.체결건수, a.체결수량, a.거래대금
from 일별종목거래및시세 a, 종목이력 b
where a.거래일자 between to_char(add_month(sysdate,-20*12),'yyyymmdd')
and to_char(sysdate-1,'yyyymmdd')
and a.종가 = a.최고가
and b.종목코드 = a.종목코드
and a.거래일자 between b.시작일자 and b.종료일자;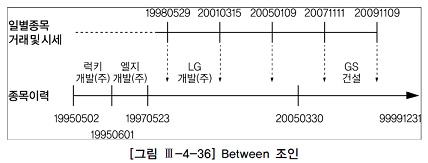
위처럼 조회시 현재 시점의 종목명이 아니라, 거래가 일어난 바로 그 시점의 종목명을 읽게 됨
--거래 시점이 아니라 현재 시점의 종목명과 상장주식수 출력
select a.거래일자, a.종목코드, b.종목한글명, b.종목영문명, b.상장주식수
,a.시가, a.종가, a.체결건수, a.체결수량, a.거래대금
from 일별종목거래및시세 a, 종목이력 b
where a.거래일자 between to_char(add_month(sysdate,-20*12),'yyyymmdd')
and to_char(sysdate-1,'yyyymmdd')
and a.종가 = a.최고가
and b.종목코드 = a.종목코드
and to_char(sysdate,'yyyymmdd') between b.시작일자 and b.종료일자;
5. ROWID 활용
점이력 : 선분이력과 대비해, 데이터 변경이 발생할 때마다 변경일자와 함께 새로운 이력 레코드 쌓는 방식
-- 점이력에선 찾고자 하는 시점보다 앞선 변경일자 중 가장 마지막 레코드 찾음
select a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액, b.연체개월수
from 고객 a, 고객별연체이력 b
where a.가입회사='C70'
and b.고객번호=a.고객번호
and b.변경일자 = (select max(변경일자)
from 고객별연체이력
where 고객번=a.고객번호
and 변경일자 <= a.서비스만료일);
-----------------------------------------------
Execution Plan
-----------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE (Cost=845 Card=10 Bytes=600)
1 0 TABLE ACCESS (BY INDEX ROWID) OF '고객별연체이력' (Cost=2 Card=1 Bytes=19)
2 1 NESTED LOOPS (Cost=845 Card=10 Bytes=600)
3 2 TABLE ACCESS (BY INDEX ROWID)OF '고객' (Cost=825 Card=10 Bytes=410)
4 3 INDEX (RANGE SCAN) OF '고객_IDX01'(NON-UNIQUE) (Cost=25 Card=10)
5 2 INDEX (RANGE SCAN) OF '고객별연체이력_IDX01' (NON-UNIQUE) (Cost=1 Card=1)
6 5 SORT (AGGREGATE) (Cost=1 Bytes=13)
7 6 FIRST ROW (Cost=2 Card=5K Bytes=63K)
8 7 INDEX (RANGE SCAN (MIN/MAX)) OF '고객별연체이력_IDX01' (NON-UNIQUE)(..)위 쿼리는 고객별연체이력을 2 번 액세스 하고 있다. 다행히 옵티마이저가 서브쿼리 내 서비스 만료일보다 작은 레코드를 모두 스캔하지 않고, 인덱스를 거꾸로 스캔하면서 가장 큰 값 하나만을 찾았다.
위 쿼리가 빈번하게 수행되어 액세스를 줄여야 하는 상황이라면 ROWID를 이용해 조인
select /*+ordered use_nl(b) rowid(b) */
a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액, b.연체개월수
from 고객 a, 고객별연체이력 b
where a.가입회사='C70'
and b.rowid=(select /*+ index(c 고객별연체이력_idx01)*/ rowid
from 고객별연체이력 c
where c.고객번호 = a.고객번호
and c.변경일자 <= a.서비스만료일
and rownum <=1
);
-----------------------------------------------
Execution Plan
-----------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE (Cost=835 Card=100K Bytes=5M)
1 0 NESTED LOOPS (Cost=835 Card=100K Bytes=5M)
2 1 TABLE ACCESS (BY INDEX ROWID) OF '고객' (Cost=825 Card=10 Bytes=410)
3 2 INDEX (RANGE SCAN) OF '고객_IDX01'(NON-UNIQUE) (Cost=25 Card=10)
4 1 TABLE ACCESS (BY USER ROWID) OF '고객별연체이력' (Cost=1 Card=10K Bytes=137K)
5 4 COUNT (STOPKEY)
6 5 INDEX (RANGE SCAN) OF '고객별연체이력_IDX01' (NON-UNIQUE)(..)위 쿼리가 제대로 작동하려면 고객번호+변경일자순으로 구성돼야 한다.
