📔문제
예전에는 운영체제에서 크로아티아 알파벳을 입력할 수가 없었다. 따라서, 다음과 같이 크로아티아 알파벳을 변경해서 입력했다.
| 크로아티아 알파벳 | 변경 |
|---|---|
| č | c= |
| ć | c- |
| dž | dz= |
| đ | d- |
| lj | lj |
| nj | nj |
| š | s= |
| ž | z= |
예를 들어, ljes=njak은 크로아티아 알파벳 6개(lj, e, š, nj, a, k)로 이루어져 있다. 단어가 주어졌을 때, 몇 개의 크로아티아 알파벳으로 이루어져 있는지 출력한다.
dž는 무조건 하나의 알파벳으로 쓰이고, d와 ž가 분리된 것으로 보지 않는다. lj와 nj도 마찬가지이다. 위 목록에 없는 알파벳은 한 글자씩 센다.
📝입력
첫째 줄에 최대 100글자의 단어가 주어진다. 알파벳 소문자와 '-', '='로만 이루어져 있다.
단어는 크로아티아 알파벳으로 이루어져 있다. 문제 설명의 표에 나와있는 알파벳은 변경된 형태로 입력된다.
📺출력
입력으로 주어진 단어가 몇 개의 크로아티아 알파벳으로 이루어져 있는지 출력한다.
📝예제 입력 1
ljes=njak📺예제 출력 1
6📝예제 입력 2
ddz=z=📺예제 출력 2
3📝예제 입력 3
nljj📺예제 출력 3
3📝예제 입력 4
c=c=📺예제 출력 4
2📝예제 입력 5
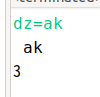
dz=ak📺예제 출력 5
3🔍출처
Contest > Croatian Open Competition in Informatics > COCI 2008/2009 > Contest #5 1번
-문제를 번역한 사람: baekjoon
-데이터를 추가한 사람: cake_monotone, evenharder, handong, jh05013, veydpz, zzangho
-문제의 오타를 찾은 사람: jh05013
-어색한 표현을 찾은 사람: jh05013
🧮알고리즘 분류
- 구현
- 문자열
📃소스 코드
import java.util.Scanner;
public class Code2941 {
public static void main(String[] args) {
// TODO Auto-generated method stub
Scanner scanner=new Scanner(System.in);
String word="";
word=scanner.next();
int count=0;
int index=0;
String[] alpha= {"c=","c-","dz=","d-","lj","nj","s=","z="};
for(int i=0;i<alpha.length;i++) {
while(word.contains(alpha[i])) {
word=word.replaceFirst(alpha[i], " ");
count++;
}
}
word=word.replace(" ", "");
for(int i=0;i<word.length();i++) {
count++;
}
System.out.println(count);
}
}📰출력 결과
📂고찰
먼저 크로아티아 어를 다 string 배열에 넣었다.
그 다음 word에 크로아티아 어가 없을 때 까지 계속해서 크로아티아어랑 비교했다.
ex) c=c= 일때,
while문안에서 2번돌고 탈출하겠지.
word.contains(alpha[0])에 true로 걸리니까..
