지난 글에서는 동시성 문제가 발생하는 원인에 대해서 분석했었습니다.
이번 글에서는 동시성 문제를 해결하는 방법 에는 어떤 것들이 있을지와
각 방법의 장단점, 한계점에 대해 정리해보겠습니다.
1. Transaction Isolation Level 설정
트랜잭션 격리수준 中 가장 높은 레벨인 Serializable을 적용한다면 동시성 문제를 해결할 수 있을까요?
Serializable 격리수준이 적용된 트랜잭션에서 Select 쿼리로 조회를 해 올 경우
해당 레코드에 공유락(Shared Lock)을 획득하게 됩니다.
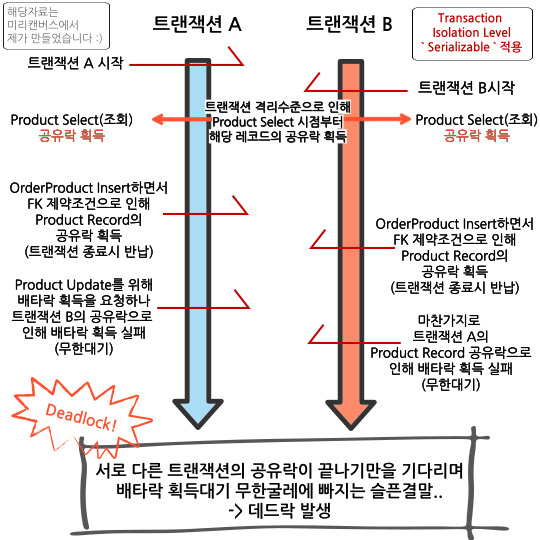
- 기존의 로직보다 더 빠른 시점(Product Select하는)부터 해당 Product Record의 공유락을 획득하게되고, 마찬가지로 데드락을 피할 수 없습니다.
따라서 Transaction Isolation Level로는 동시성문제를 해결할 수 없습니다.
2. 비관적 락(Pessimistic Lock)
비관적 락은 말 그대로
충돌이 무조건 발생한다라는 비관적인 전제에서 출발합니다.
- 비관적 락은 대표적으로
SELECT ... FOR UPDATE 문을 통해 조회시점에 배타 락(Exclusive Lock)을 획득하고, Transaction Commit(혹은Rollback)되는 시점에 반납하는 방식으로 작동합니다. - @Lock 어노테이션을 활용하면 더 다양한 방식으로 비관적 락을 구현할 수 있습니다.(
SELECT ... FOR UPDATE 문과 같은 배타락 활용방식
->@Lock(value = LockModeType.PESSIMISTIC_WRITE)
2-1. 비관적 락의 작동방식 [SELECT ... FOR UPDATE(배타락) 기준]
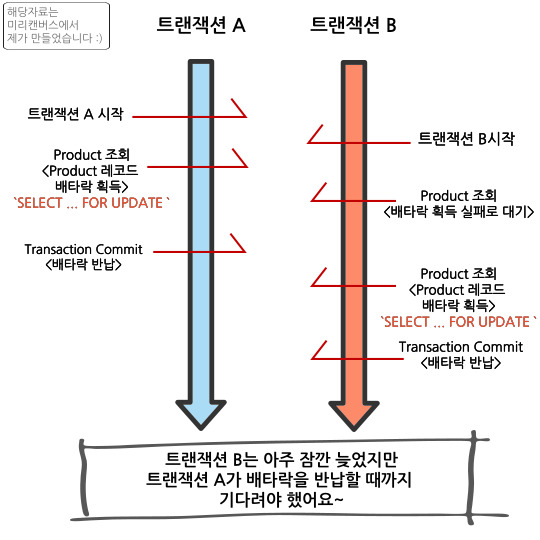
2-2. 비관적 락의 장점
-
데드락 이슈에서 벗어날 수 있다.
(API-A의 로직상에서 A,B 객체의 레코드를 조회하여 배타락을 획득하고,API-B에서는 B,A 객체의 레코드를 조회하여 배타락을 획득하려하는 최악의 경우를 전제한다면데드락이 가능할 것 같다.) -
갱신손실(Lost Update) 이슈도 해결할 수 있으므로데이터 정합성을 유지할 수 있다.InnoDB 스토리지 엔진을 사용하는 Maria DB, MySQL DB에 경우
단순 select 조회는 공유락을 요청하지 않기에 단순 조회는 병렬적으로 가능하다.
2-3 비관적 락의 단점
- 동시에 접근하는 트랜잭션이 많아지면 많아질수록 API 콜의 대기 시간은 늘어나게 된다.
(위 사진처럼 다른 트랜잭션들은 기다려야한다.) - 레코드를 배타락으로 점유하는 시간자체가 길다.
(Product를 조회해오는 시점부터 트랜잭션 종료시점까지 점유한다.) - 해당 레코드에 공유락을 요청하는 API들까지도 기다려야한다.
(다른 API에도 영향을 미친다.)
단순 select 조회에도 공유락을 요청하는 DB의 경우
단순 조회까지도 불가능하게 된다.
3. 낙관적 락(Optimistic Lock)
낙관적 락은 말 그대로
충돌이 거의 발생하지 않을 것이라는 낙관적인 전제가 성립될 때 사용할만한 방법입니다.
- 낙관적 락은 사실 이름과 다르게, 어떤 데이터에도 Lock을 걸지 않습니다.
- 그렇기에 데드락 문제가 발생하지 않고, 위의 두가지 방법과 달리
다수의 트랜잭션이 동시에 동일한 데이터에 접근할 수 있으므로 효율적인 읽기 작업을 가능하게 합니다. - @Version, @Lock 어노테이션을 통해 낙관적락을 구현할 수 있습니다. 테이블 내부에
버전관리만을 위한 필드가 추가된다는 단점이 있습니다.
3-1. 낙관적 락의 작동방식 (버전 방식 기준)
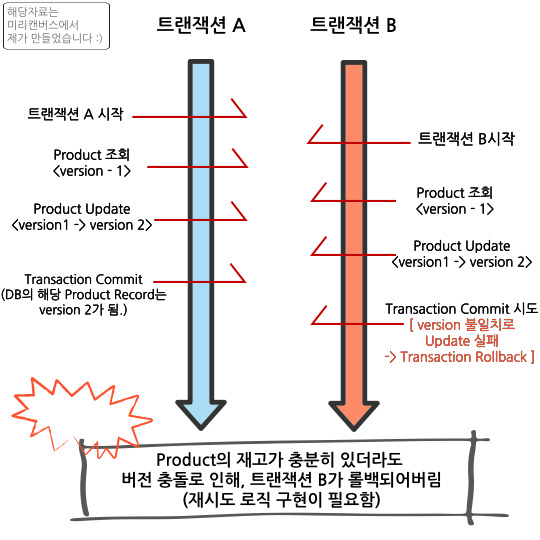
낙관적 락은 기본적으로
버전 충돌이 발생할 경우 해당 트랜잭션을 롤백합니다.
이를 해결하기 위해서는 재시도 로직을 추가해줌으로써, 요청이 유실되는 것을 막아야 합니다.
그러나, 버전 충돌이 자주 발생하는 경우 여러 단점에 직면하게 됩니다.
- 재시도가 또 다시 실패할 수 있습니다.
- 다시 조회해와서 version을 맞추고 Update 요청을 보내더라도, 그 사이에 다른 트랜잭션이 커밋하여 version이 올라간다면?
->재재시도해야됨 + 그정도 상황이라면점점 재시도하는 케이스들이 늘어날 수 있다.라는 딜레마에 빠지게 됩니다.
- 재시도를 위한 로직이 추가되면서 유지보수 및 코드이해의 난이도가 올라갑니다.
해당 테이블에 Update 쿼리를 보내는 API가 여러개라면 (사진에선 Product)
-> 여러개의 API의 접근이 모두 충돌을 염두해두고 개발해야합니다.현재 프로젝트의 테스트는
동시성 이슈가 매우 많이 발생하는 상황을 가정하여 진행되고 있기에, 낙관적 락으로는 문제를 해결할 수 없습니다.
4. [Named Query] @Query로 직접 Update Query 작성하기
이전 글에서 분석한 데드락 발생 이유를 기억해보자
1.Product.Id를 FK로 가지는OrderProduct Insert 쿼리가 커밋되면서해당 Product 레코드에 공유락을 획득한다.
2. Product Update를 위해배타락(Exclusive Lock)을 요청한다.
3. 그러나 다른 트랜잭션들이 공유락을 걸어둔 상태이므로, 배타락을 획득하지 못하고 데드락에 걸린다.
4-1. 배타락을 먼저 획득한다면 데드락을 피할 수 있다.
-
공유락은 다른 트랜잭션이 보유하고 있더라도 획득할 수 있다.
-> 그렇기에 여러 트랜잭션들이 공유락을 보유하게 되고, 배타락 획득 요청이 다른 트랜잭션의 공유락으로 인해 거절당하면서 데드락이 발생하게 된다. -
공유락보다 배타락이 먼저 획득되도록 한다면?
-> 배타락을 다른 트랜잭션에서 보유하고 있다면 대기상태에 들어가게 된다.
-> 당연히 이후 로직들이 실행되지 않기에Product 레코드의 공유락 획득도 밀리게 되면서
-> 배타락을 획득한 트랜잭션은 무사히 모든 작업을 수행하게 된다. -
비관적 락에 비해 상대적으로 배타락 점유시간이 짧다.
-> 비관적 락은Product Select 시점부터 배타락을 점유하지만, 이 방법은Product Update 시점부터 배타락을 점유하는 것이므로 더 짧게 보유한다.
4-2. Dirty Checking이 아닌 DB 레코드의 값을 기준으로 재고를 차감하여 갱신손실(Lost Update)을 방지한다.
- 갱신손실은 조회 시점과 update 시점의 데이터 정합성이 일치하지 않기에 발생한다.
- Update 쿼리를 직접 작성하여 DB 레코드의 값을 기준으로 재고차감을 진행한다면 갱신손실을 막을 수 있다.
4-3. 재고부족으로 인한 예외처리는 어떻게 하는가?
- Update 쿼리에 where 조건을 붙여서 재고가 없음에도 차감하는 것을 예방하고, 쿼리를 통해 수정된 레코드 수를 int로 받아 예외처리를 진행한다.
[Named Query] @Query로 직접 Update Query 작성하기을 직접 적용해보는 과정은 [링크]에 정리하였습니다.
++ DB락과 분산락의 차이점
-
지금까지 설명한 1~4의 방법들은
공유락, 배타락을 활용하여테이블, 레코드와 같은공유자원에 락을 거는DB락방식이었습니다. -
이제부터 설명할
분산락은 공유자원 자체에 락을 거는 것이 아니라,
어떤 행위가 발생하는임계구역(Critical Section)에 락을 거는 방식이라고 설명할 수 있습니다.
분산락이란 이름이 낯설다..
- 저는 처음
분산락이라는 이름을 들었을 때, 몰리는 트래픽을 분산시켜서 해결하는 방법인가? 라고 생각했었습니다.
이번 동시성 시리즈를 연재하면서 분산락에 대해 조금이나마 제대로 이해할 수 있었는데요. 개인적으로 이해한 바를 정리해보자면.분산락은 서버, DB등이 분산되어 있는 환경에서
임계구역(Critical Section)에 대한 접근을 관리함으로써동시성 문제를 해결하는 방법입니다.
분산락 구현시 공통적인 주의사항
-
트랜잭션 내부에서 분산락을 반납하지 않도록 주의해야합니다.
로직 마지막에서 분산락을 반납했다 하더라도 실제로 쿼리가 DB로 보내지는 시점은 로직이 모두 종료된 이후인
트랜잭션 커밋시점입니다.( 트랜잭션 커밋시
공유자원001에 대한 배타락이 필요한 상황이라고 전제)- 트랜잭션A의 커밋이 이루어지기 전에 분산락을 반납했다.
-> 트랜잭션B가 분산락을 획득하고,공유자원001의 공유락을 획득했다.
-> 트랜잭션 A는공유자원001의 배타락을 획득할 수 없기에 커밋이 실패하고 - 데드락이 발생하게 된다.
- 트랜잭션A의 커밋이 이루어지기 전에 분산락을 반납했다.
-
트랜잭션 외부(바깥)에서 분산락을 반납할 수 있도록 설계합시다
5. [분산락] MySQL의 네임드락 방식
- 네임드락 방식으로 동시성을 해결하고자 하는 분들을 위한 [Ref 링크]
- [우아한형제들 - MySQL을 이용한 분산락으로 여러 서버에 걸친 동시성 관리]
MySQL 의 네임드 락(Named Lock) 은 테이블이나 레코드, 데이터베이스 객체가 아닌 사용자가 지정한 문자열(String)에 대해 락을 획득하고 반납하는 잠금 기법입니다.
5-1. 네임드락 장점
- MySQL DB를 사용중이라면 추가로 인프라를 세팅하지 않고도 구현할 수 있습니다.
- MySQL 자체적으로 제공하는 기능이기에 구현이 간단하고 쉽습니다.
5-2. 네임드락 단점
-
일단 프로젝트에서 MySQL DB를 쓰지 않는다면 장점들이 사라집니다.
-
분산락 획득, 반납에 따른 트래픽도 DB가 감당해야됩니다.
-> 동시성 문제 발생시 DB에 많은 부하를 주게되고, 성능에도 영향을 미칩니다. -
데이터베이스가 분산되어 있거나, MSA 환경에서 서비스별로 DB를 분리하여 운영하는 경우에는
네임드락의 정보를 공유하고 동기화하는 문제의 난이도가 매우 높아집니다.
현재 프로젝트 구조에서는 네임드락으로도 동시성문제를 해결할 수 있을 것 같습니다.
그러나이미 JWT 토큰저장소로 레디스를 사용하고 있다는 점,범용적인 활용성이 더 좋다는 점을 근거로 레디스를 활용하여 분산락을 구현해보기로 하였습니다
6. [분산락] Redis를 활용한 분산락
6-1. Lettuce가 아니라 Redisson을 사용하는 이유(Spin Lock / pub-sub)
레디스로 분산락을 구현하고자 할 때, 먼저 어떤 클라이언트를 사용할 것인지 골라야합니다.
6-1-1. Lettuce
-
일반적으로 Lettuce를 사용해본 경험이 더 많다보니 익숙한 Lettuce로 분산락을 구현한다면 더 편하겠지만,
Lettuce에서는Setnx 명령어를 활용하여 분산락을 구현해야합니다. (Set if not Exist - key:value를 Set 할 떄. 기존의 값이 없을 때만 Set 하는 명령어) -
문제는 이 Setnx 명령어를 사용하기 위해서는
반복문을 통해 Spin Lock 방식으로 구현해야하기 때문에, 레디스에 많은 부하를 주게 됩니다.
Thread.sleep()을 통해 부하를 줄여주는 방법이 있긴하지만, 그것으로 충분하지 않습니다. -
Spin Lock 방식 간단설명
- Lock을 획득할 때까지 Redis에게 "Lock 획득할 수 있니?"라고 계~속 물어보는 것.
6-1-2. Redisson
-
레디스는 메세지에 대한
publish & subscribe, 줄여서 pub/sub 기능을 지원합니다. (메세지 브로커 역할) -
Redisson은 이 메세지 기능을 활용하여 분산락을 구현하였기 때문에,
락이 해제되는 시점에 구독중인 스레드들에게 메세지를 보냅니다.
스레드가 계속해서 락 획득을 위한 요청을 보내지 않아도 되니Spin Lock방식에 비해서 레디스에 부하가 덜합니다. -
또한 Redisson은
락 획득 대기시간, 락 획득 후 점유시간에 대한 타임아웃 기능을 이미 구현해놨기 때문에 훨씬 간편하고 효율적으로 분산락 운영을 할 수 있습니다.
6-2. Redis 분산락 장점
-
기본적으로 Redis는 인메모리DB이기에 더 빠르게 락을 획득 및 해제할 수 있다.
-
분산락에 대한 부하를 레디스에서 감당해준다 -> DB 과부하 위험이 줄어든다. -
분산락 관리자 역할을 하나의 DB가 아니라 레디스에서 맡음으로써, 데이터베이스가 분산되어 있거나, MSA 환경에서 서비스별로 DB를 분리하여 운영하는 경우에도 문제없이동시성 이슈 제어가 가능하다.
6-3. Redis 분산락 단점
- 레디스 서버가 다운되거나 문제가 발생하면 해당 레디스 서버에 접근하는 모든 클라이언트가 영향을 받을 수 있기에, 레디스 서버가
단일 장애 지점이 될 위험이 있습니다.
Redis - Redisson 으로 분산락을 구현하는 과정과 그 외에 해결방안에 대한 고민들은 [링크] 해당 글에 정리하였습니다.
7. 기업에서는 어떤 방식을 활용하고 있는가?
재고관리 동시성 관련 Ref정리 - [링크]
- 이번 시리즈를 연재하고 동시성 해결을 하는 과정에서 참고한 기업, 개인의 블로그들을 위 글에 정리해두었습니다. (배민, 야놀자, 마켓컬리, 토스)
8. 글을 마치며(개인적인 배움 & 생각)
동시성 문제를 학습하면서 개발의 재미를 많이 느낄 수 있었습니다.
여러 상황을 전제하여 테스트를 돌려보면서"왜 이렇게 되지?"라는 질문들이 끝도 없이 쏟아졌고, 이를 명확히 이해하기 위해 공식문서들을 들여다보면서 자연스럽게DB와 관련된 CS지식들을 학습할 수 있어서 더욱 좋았던 것 같습니다.
(개인적으로는 이 학습방식을꼬리물기 학습이라고 부릅니다.)
이어지는 글들에 기술하겠지만, 동시성 문제에 대해 공부하면 할수록
정답은 없다.라는 배움을 얻게 됩니다.
확실한 것은여러 해결방법의 원리와 장단점등을 알고 있어야 상황에 맞는 해결책을 판단하고 적용할 수 있기에 앞으로도 계속해서 고민하고 탐구해야겠다는 다짐을 해봅니다.



개발자로서 배울 점이 많은 글이었습니다. 감사합니다.