오늘의 목표 : 프로젝트 진행은 어느정도 해야하지 않을까..? 아 동아리 발표에서 주제 겹치는 것 때문에 프로젝트 순서를 어떻게 할지 고민이 많다ㅠㅠ.. 그래도 해야지..어쩌겠어ㅓ~
5장. 분류의 군집화
5-2. 군집화(Clustering) 알고리즘
비지도 학습의 일종으로, 컴퓨터가 카테고리를 모르는 상태에서 데이터만으로 유사한 패턴을 가진 군집을 찾아내는 방식
= 결과가 매우 불안정하며, 군집을 찾아내는 방식에 따라 결과 또한 다양하게 나타난다.
군집화 알고리즘 유형
- 연결성 기반 : 데이터 사이의 거리 연결성을 중심으로 군집화 (hierarchical 클러스터링)
- 중심 기반 : 평균 벡터를 기준으로 군집화 (K-means 클러스터링)
- 분포 기반 : 확률 분포를 기반으로 군집화 (EM 알고리즘, multivariate 정규 분포)
- 밀도 기반 : 데이터 공간 내의 연결된 밀집 영역을 기준으로 군집화 (DBSCAN)
- 그래프 기반 : 데이터를 그래프로 표현한 후 서로 연결된 가까운 노드를 군집화 (HCS 클러스터링)
5-2. K-Means 클러스터링
주어진 데이터를 K개의 클러스터로 만들어준다.
- 임의의 점을 K개 할당한다 (분석가가 직접 개수를 지정)
- 각 점을 기준으로 가장 가까이 있는 점들을 군집에 포함
- 분류된 군집에 속한 모든 점들의 평균점으로 중심점을 이동
- 재조정 후에도 군집이 변하지 않는다면(최적) 반복을 중지, 아닐 경우 2번째 단계로 돌아감
장점
- 구현이 쉽다
- 속도가 빠르다
단점
- 최적의 K 값을 결정하기 어렵다
- 학습 결과가 항상 동일한 결과를 보장하지 않는다
- 이상치에 민감하다
5-3. DBSCAN
확률 밀도 기반 클러스터링 알고리즘으로, 데이터가 몰려있는 밀도가 높은 부분을 군집화하는 방식
= 반경 x거리 내에 점이 n개 이상 있으면 하나의 군집으로 인식
장점
- 어떠한 형태의 데이터 분포도 높은 정확도로 군집을 잘 형성한다
- 군집의 개수를 임의로 지정하지 않아도 기하학적인 모양의 클러스터도 높은 정확도로 분류
- 밀도를 기준으로 군집을 형성해 이상치에 강하다
단점
- 최적의 ε와 minPts 값을 찾아야한다
- 데이터들이 충분한 수준의 밀도를 형성하지 않는 경우 정확도가 낮게 나올 수 있다
5-4. 주성분 분석(Principal Component Analysis)
특징 공간에서 주성분이 되는 축을 찾아 이 축을 기준으로 데이터를 변환해 특징의 개수를 줄여주는(차원 축소) 알고리즘
카테고리 정보 없이 데이터 자체만으로 핵심이 되는 성분을 파악한다
차원을 축소할 경우, 특징의 개수는 줄이면서 특징이 담고 있던 정보의 양은 최대화할 수 있다. 또한, 주성분을 중심으로 변환한 각 특징ㅇ은 서로 간의 상관성이 제거되는 효과도 있다.
주성분 : 직선을 그은 후 모든 점을 해당 직선에 붙일 때, 그 거리가 최소가 되는 직선
= 정보의 손실이 가장 작은 축
두 번째 주성분은 첫번째 주성분과 직교하는 직선
기능을 초기화한 후, 데이터에서 주성분을 찾는 학습을 수행하고(fit), 차원 축소를 원할 경우 축소 함수(fit_transform)를 호출해 축소된 특징 데이터를 얻을 수 있다.
5-3. 딥러닝과 보안 1 - 보안 분야 적용 방안과 CNN
1) 활용 관점에서 이해하는 딥러닝
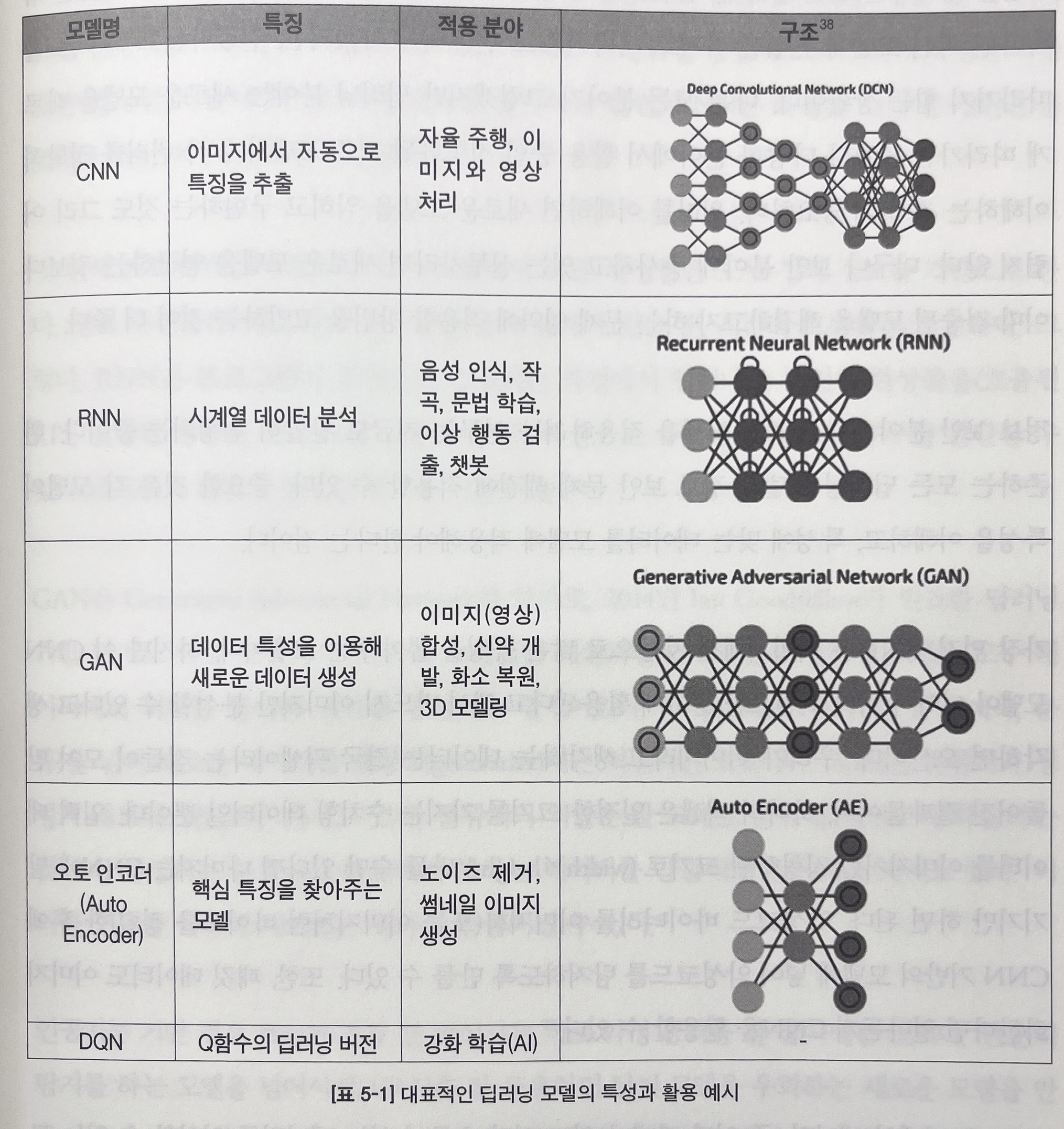
- CNN
- 이미지에서 자동으로 많은 특징을 뽑아주는 모델
- 악성코드 바이너리를 이미지화(또는 이미지처럼 바이트를 정렬)한 후에 CNN 기반의 모델에 넣어 악성코드를 탐지하도록 만들 수 있다.
- RNN
- 시계열 데이터 (인과 관계가 있고 시간의 흐름이 있는 데이터)를 처리할 수 있는 모델
- 네트워크 안에 위치한 노드들이 다양한 방향으로 연결되어 있다.
- GAN
- 단순 판단(예측, 분류)을 넘어 새로운 데이터를 생성해내는 모델
- 분류기, 생성기 네트워크를 모두 가지고 있다.
- 분류기 : 분류를 잘하도록 학습
- 생성기 : 분류하지 못하는 데이터를 만들어내는 목적
- 오토 인코더
- 데이터를 인코딩(정보를 압축 = 차원을 축소)하고, 디코딩(축소한 차원 복구)하는 역할
- 축소 시 데이터가 가지고 있던 정보에 손실이 발생해 완전히 동일한 데이터로 복원되지는 않는다
2) CNN 이해하기
이미지 '인식', 즉 분류 기능을 수행하는 역할로 가장 많이 활용되고 있다.
이미지를 잘 분류해주는 단순한 모델이라기보다 복잡하고 많은 정보를 담고 있는 이미지에서 인간이 놓치기 쉬운 많은 부분을 특징화 해준다
특징을 추출하는 부분과 추출한 특징을 사용해 판단을 내리는 부분으로 나뉘어진다.
특징을 추출하는 부분은 다양한 필터를 사용해 이미지 전체를 스캔하듯이 사진을 찍는 방식을 사용한다.
여러개의 특징추출 레이어를 통해 이미지 특징을 추출한 후, 마지막으로 Fully Connected 레이어에서 분류 작업을 한다.
반드시 이미지에만 적용할 수 있는 것이 아닌, 어떠한 데이터에도 적용이 가능하지만! 모든 데이터의 크기를 동일하게 맞춰줘야 한다는 전제 조건이 있다.
6장. PJ1_악성코드 탐지 모델(프로젝트 개요)
첫 번째 프로젝트는 악성코드 탐지 모델 구축.
32비트 윈도우 실행 파일 형식인 PE 형식을 가지는 악성코드 탐지 모델 구축에 초점.
탐지 모델 구축에 있어 가장 중요한 부분은 악성코드의 특징을 정확하게 이해하는 것!
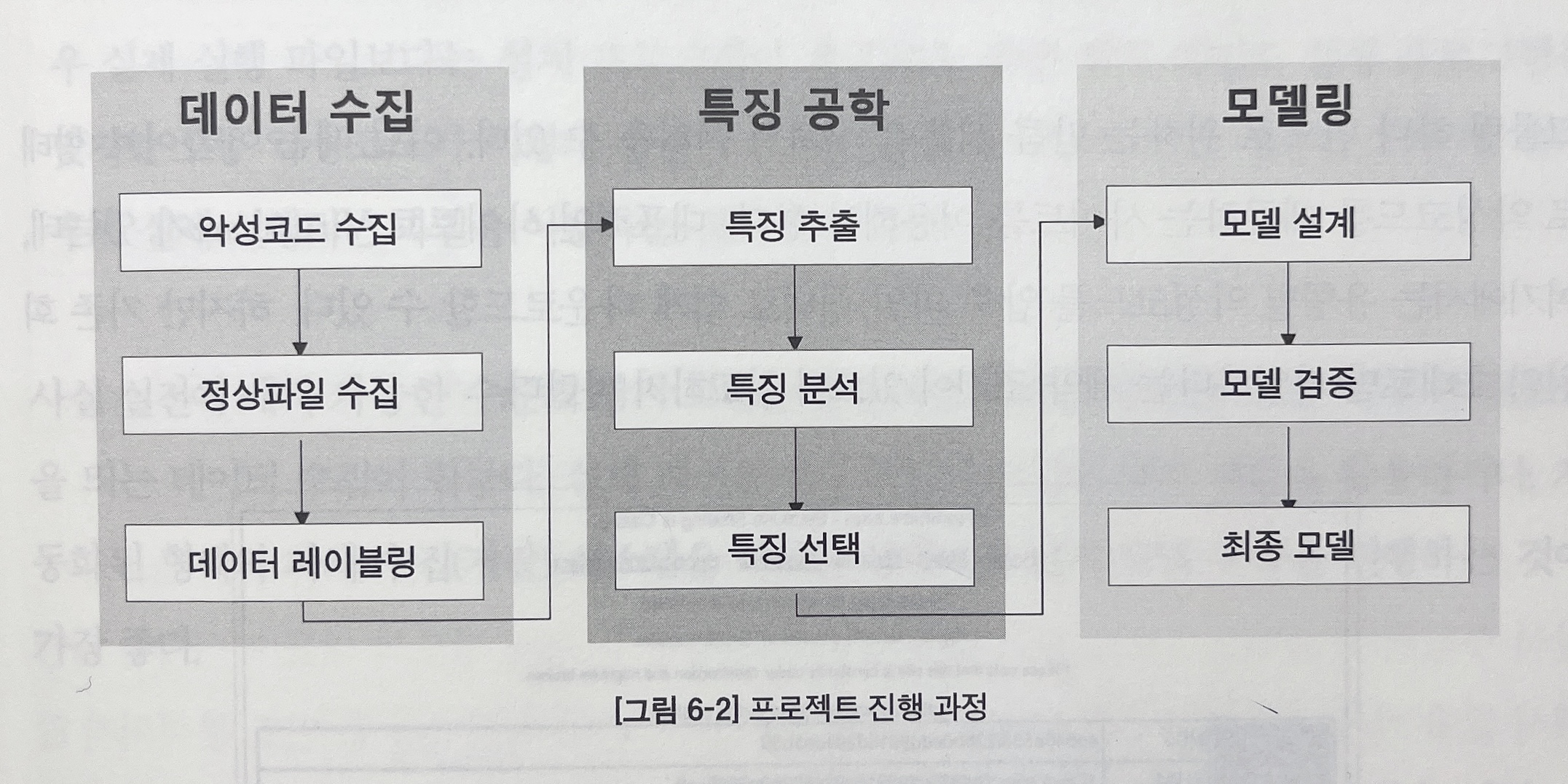
프로젝트 진행 과정을 간략하게 설명해본다.
(1) 데이터 수집
- 악성코드 수집 : 웹 크롤링과 아카이브 다운로드를 이용한다.
- 정상파일 수집 : 공개 소프트웨어 다운로드 사이트를 이용한다.
- 데이터 레이블링 : 바이러스 토탈 사이트에서 제공하는 서비스를 이용해 레이블링 진행한다.
(2) 특징 공학
- 특징 추출 : 각 특징이 가지는 장단점을 정확히 이해하고 이를 토대로 최적의 특징을 선택해야 한다
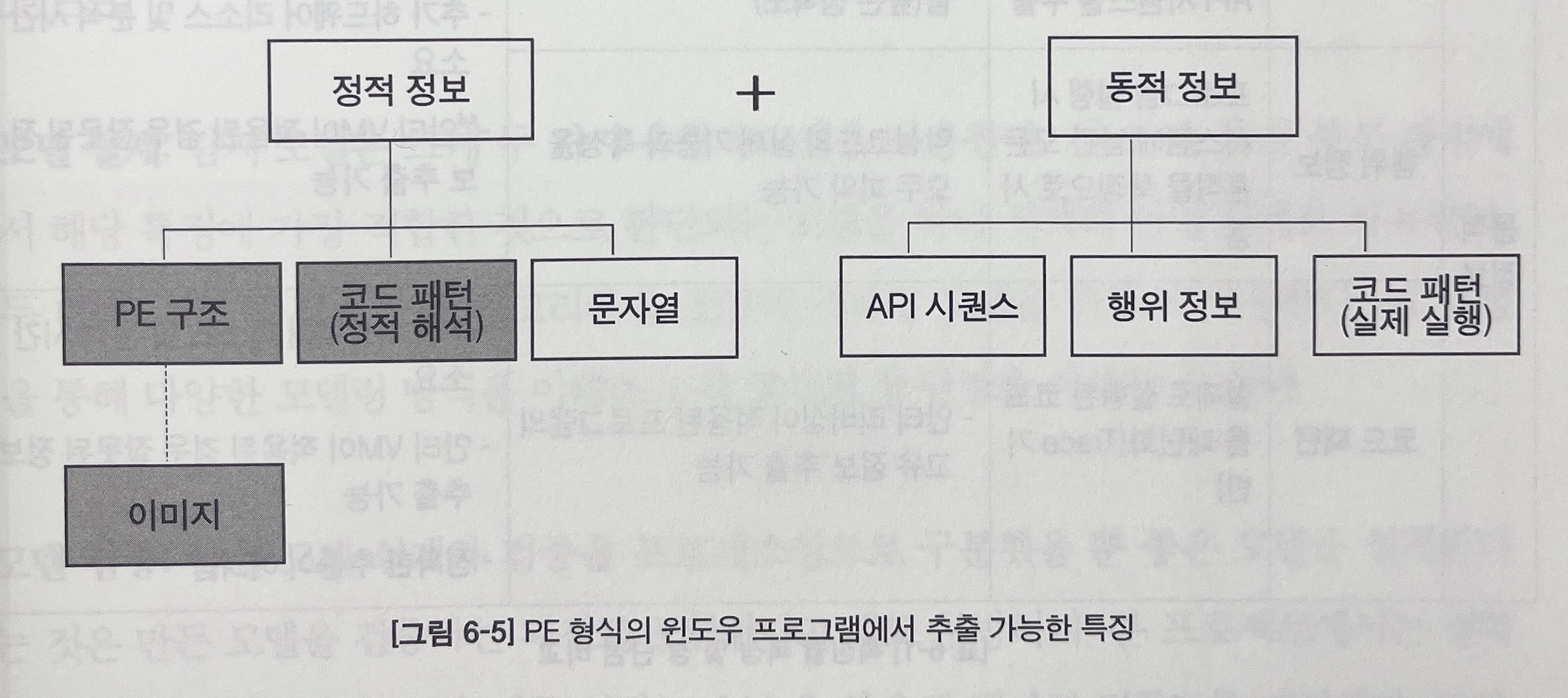
- 정적 정보 : 비교적 추출이 간단하나 실제 실행 시 의미를 가지는 정보를 확인 할 수 없다(프로그램에서 사용하는 주요 문자열이 암호화된 경우)
- 동적 정보 : 악성코드에 대한 더 정확한 정보 추출에는 용이하나 추가 리소스가 필요하고, 판단에 시간이 소요된다
- 특징 분석과 선택
- 앞서 추출한 세 가지 특징들 중 어떠한 특징이 가장 좋은 모델을 보장해주는 지 분석한 후 한 가지 유형을 선택한다
- 선택한 특징을 한번 더 분석해 최소의 개수로 최대의 성능을 보장하는 특징 조합을 찾아낸다
(3) 모델링
- 모델 설계 : 다양한 모델링 방식을 이해하고 각 방식의 장단점을 이해할 수 있다
- 특징 분석 과정에서 해당 특징에 가장 적합한 것으로 판단되는 모델을 하나 선택해 단일 모델로 사용한다
- 여러 특징과 모델 알고리즘을 조합해 스태킹 모델을 만들어 사용한다
- 모델 검증 : 본 프로젝트에서는 정확도를 지표로 사용하되, 교차 검증 기법(10-fold)을 사용해 평가의 정확도를 개선했다. 또한, 최적의 모델 지표 선택에 GridSearchCV 기능을 적용했다
환경구축
conda activate mlsec_27
pip install pefile yara seaborn image bs4 html5lib keras psutil tensorflow^ 필수 패키지 설치

^ 필수 디스어셈블 라이브러리 설치

오늘 공부는 끝났다. 진도를 더 나가지는 않고 이전 개념들을 복습하려고 한다.
내일부터 데이터 수집, 특징 공학, 모델링 순서로 프로젝트를 진행할 예정이다.
아는 개념들이 많이 나와서 재밌기도 하고, 시험공부해야하는데 프로젝트에 빠져서 살고 있어서 걱정이 살짝 되기도 한다. 그래도 열심히 해야징!
