Collection & Map - 3-1. Hash기반 Set & Map
- 이번 시리즈에서는 Java의 Collection과 Map에 대해 소개합니다.
- 프레임워크의 기반이 되는 자료구조에 대한 개념은 따로 시리즈로 작성할 것이고, 본 시리즈에서는 Java에서 제공하는 자료구조들과 그에 따른 메서드들을 정리할 것입니다.
0. Java의 Collection Framework와 Map Interface
- Java에서는 데이터 구조와 알고리즘을 지원하는 강력한 표준 라이브러리를 제공하며, 이 중 Collection Framework와 Map은 데이터 관리와 처리의 핵심적인 역할을 합니다.
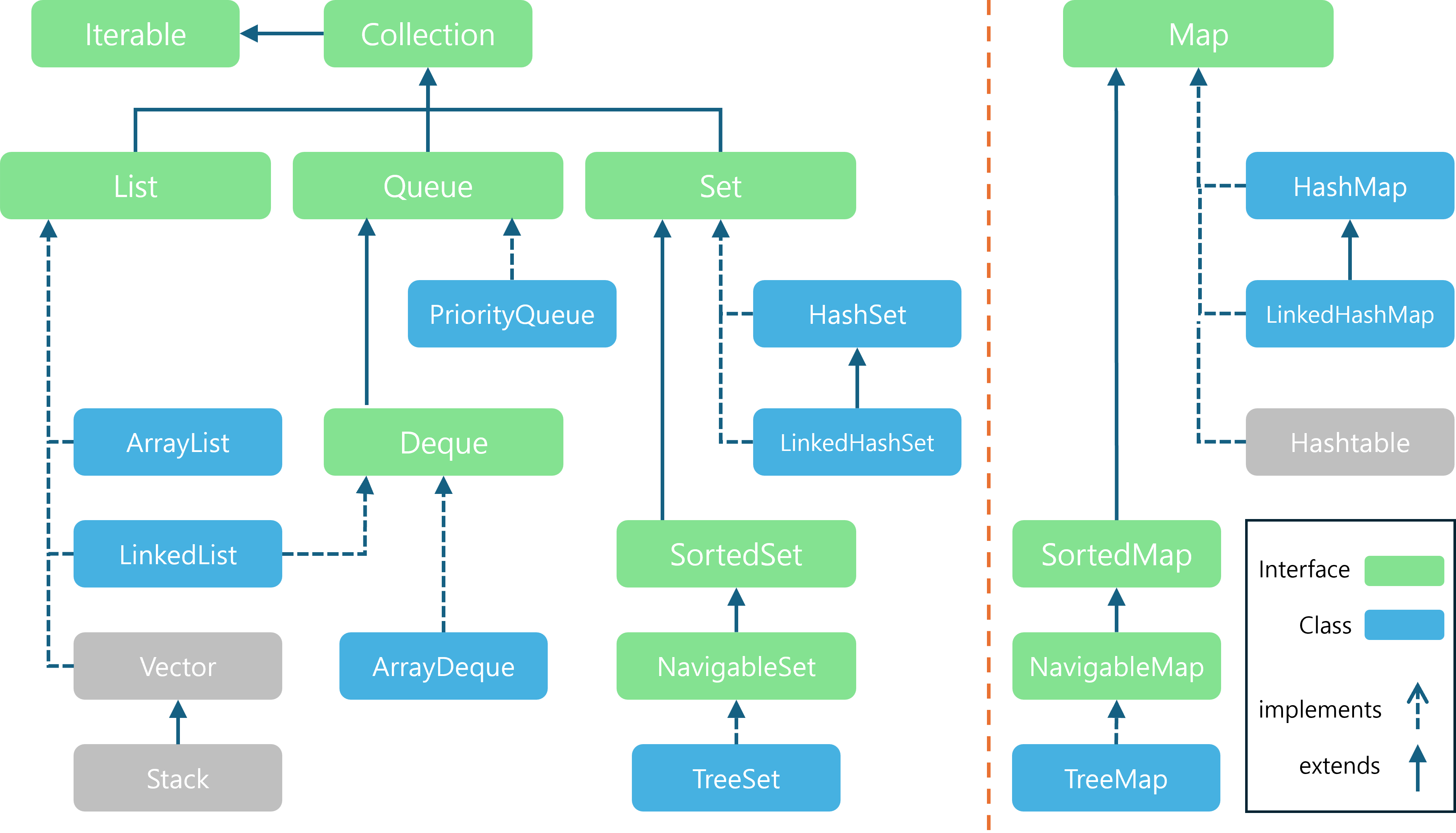
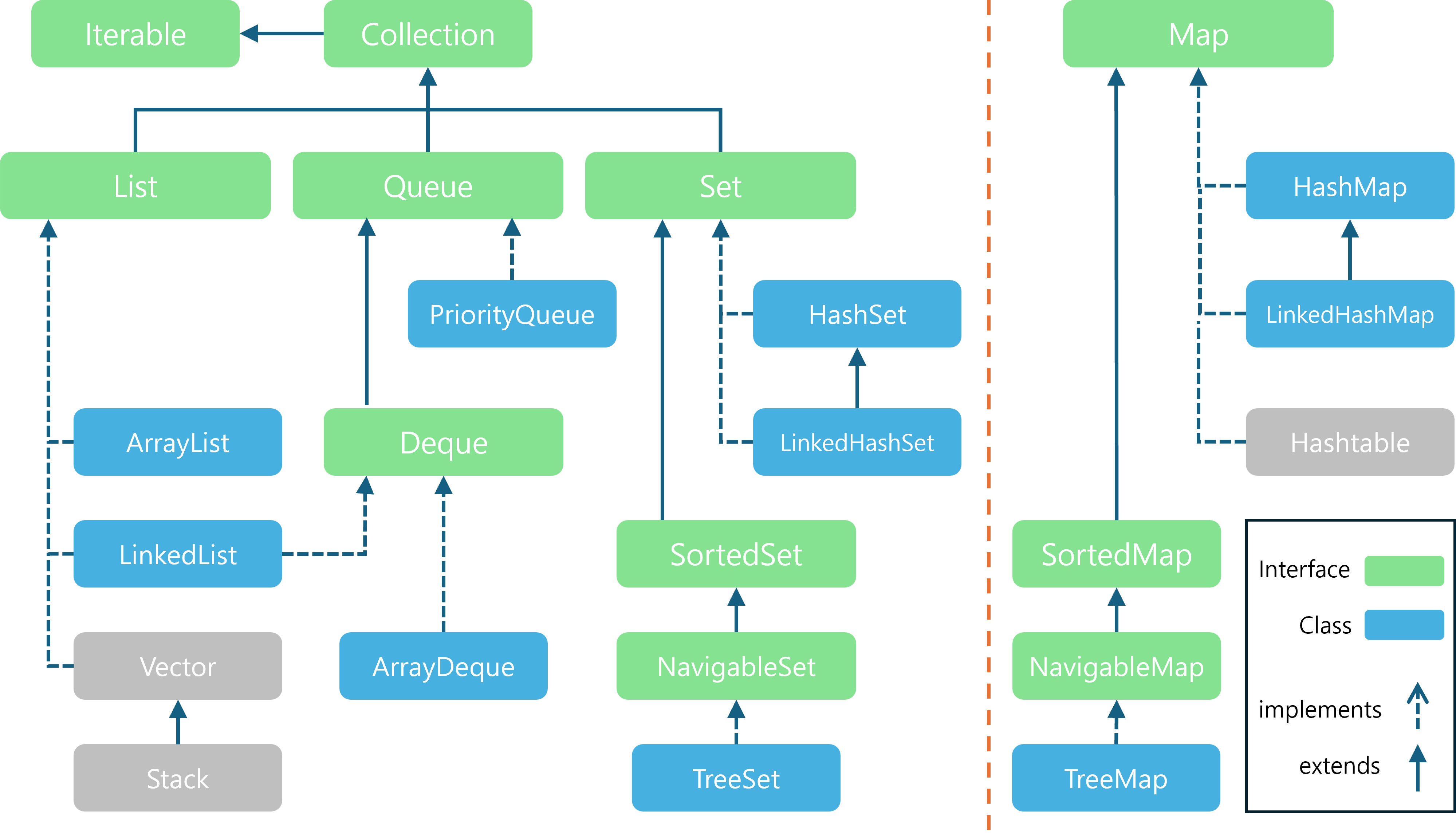
- 위 이미지는 주로 쓰이는 Collection Framework와 Map Interface의 상속 및 구현 관계를 제가 직접 그려본 것입니다.
- 회색으로 표시된
Vector,Stack,Hashtable은 Java 초창기에 만들어져서 하위 버전 호환을 위해 남겨진 Legacy Class들입니다.- 구조적인 문제들이 있어서 현재는 더이상 업데이트되지 않고 거의 쓰이지 않기 때문에 본 시리즈에서도 따로 정리하진 않을 예정입니다.
- Collection Framework
- List 구현체 :
ArrayList,LinkedList - Queue 구현체 :
PriorityQueue,ArrayDeque,LinkedList - Deque 구현체 :
ArrayDeque,LinkedList - Set 구현체 :
HashSet,LinkedHashSet,TreeSet
- List 구현체 :
- Map Interface 구현체 :
HashMap,LinkedHashMap,TreeMap
- 회색으로 표시된
- 이번 포스팅에서는
CollectionFramework의 하위 인터페이스인Set인터페이스와Map인터페이스에서 Hash를 기반으로 동작하는 구현체들을 자세히 다뤄보도록 하겠습니다.
1. Hash란?
Hash는 데이터를 고유한 숫자 값, 즉 해시코드로 변환하여 데이터를 빠르게 저장하고 검색할 수 있게 하는 방법입니다.- 해시는 대용량 데이터에서 효율적으로 데이터를 관리하고 검색하는 데 사용됩니다.
- Java의
HashSet,HashMap등과 같은 자료구조는 이러한 해시 기반 접근을 사용하여 빠른 성능을 제공합니다.
1.1. 해시 함수의 역할 (Hash Function)
- 해시 함수(Hash Function)는 주어진 데이터를 입력받아 이를 고유한 정수 값으로 변환합니다.
- 이렇게 반환된 정수 값을 해시코드(HashCode)라 하고, 데이터가 저장될 위치(인덱스)를 결정하는 데 사용됩니다.
- 해시 함수의 목표는 충돌을 최소화하면서도 모든 입력 데이터에 대해 고유한 해시코드를 생성하는 것입니다.
- 하지만, 해시 함수가 완벽하지 않기 때문에 충돌(두 개 이상의 데이터가 동일한 해시코드를 가지는 경우)이 발생할 수 있습니다.
- 이러한 상황을 해시 충돌(Hash Collision)이라 합니다
- 하지만, 해시 함수가 완벽하지 않기 때문에 충돌(두 개 이상의 데이터가 동일한 해시코드를 가지는 경우)이 발생할 수 있습니다.
1.2. 해시 테이블의 개념 (Hash Table)
- 해시 테이블은 배열과 해시 함수를 사용해 데이터를 관리하는 자료구조입니다.
- 각 데이터는 해시 함수를 거쳐 배열의 특정 인덱스에 저장되며, 이로 인해 빠른 검색과 삽입이 가능합니다.
- 검색, 삽입, 삭제의 평균 시간 복잡도는 O(1)입니다.
- 즉, 데이터가 크더라도 일정한 시간 안에 데이터를 찾거나 저장할 수 있습니다.
- 하지만 해시 충돌이 발생하면, 두 개 이상의 데이터가 같은 해시코드를 가질 수 있기 때문에 이를 해결하기 위한 방법이 필요합니다.
1.3. 해시 충돌 처리 방식 (Hash Collision)
-
해시 충돌은 여러 데이터를 해시 함수로 변환할 때 동일한 해시코드를 가지는 경우 발생합니다.
-
충돌을 처리하는 대표적인 방법은 다음과 같습니다:
Open Addressing,Separate Chaining
1.3.1. Open Addressing (개방 주소법)
-
Open Addressing은 해시 충돌이 발생하면 빈 버킷을 찾을 때까지 해시 테이블의 다른 인덱스를 순차적으로 탐색하여 데이터를 저장하는 방식입니다. (Python에서
dict자료형이 이 방법을 채택하고 있습니다)- 선형 탐사(Linear Probing): 충돌이 발생한 경우 다음 인덱스를 순차적으로 검사해 빈 자리에 저장합니다.
- 이 방식은 간단하지만, 연속적인 충돌이 발생할 경우 클러스터링(연속적인 충돌) 현상으로 인해 성능이 저하될 수 있습니다.
- 이차 탐사(Quadratic Probing): 충돌 시 고정된 간격이 아니라, 점차적인 간격을 두고 빈 자리를 찾습니다.
- Python에서는 이 방식을 변형한 특별한 해시 충돌 처리 방식을 사용합니다.
- 이 방식은 1차 클러스터링 문제를 해결할 수 있으나, 2차 클러스터링이 발생할 수 있습니다. 즉, 충돌이 발생한 위치 근처에 새로운 충돌이 몰릴 가능성이 있습니다.
- 이중 해싱(Double Hashing): 두 개의 해시 함수를 사용해 충돌이 발생한 경우 다른 해시 함수를 적용하여 빈 자리를 찾습니다.
- 이 방식은 클러스터링 문제를 어느 정도 해결하지만, 해시 함수 설계가 복잡할 수 있습니다.
- 선형 탐사(Linear Probing): 충돌이 발생한 경우 다음 인덱스를 순차적으로 검사해 빈 자리에 저장합니다.
-
Open Addressing의 장점은 추가적인 공간을 사용하지 않는다는 것이지만, 테이블이 가득 찼을 때 클러스터링(연속적인 충돌) 문제가 발생할 수 있습니다.
- 특히 선형 탐사의 경우 충돌된 인덱스 근처에 많은 충돌이 몰리게 됩니다.
1.3.2. Separate Chaining (체이닝)
- Separate Chaining(체이닝)은 충돌이 발생한 인덱스에 여러 값을 연결할 수 있도록 연결 리스트(linked list)를 사용하는 방법입니다.
- 충돌이 발생하면 동일한 해시코드를 가진 여러 데이터는 해당 인덱스의 연결 리스트에 추가됩니다.
- 이 방식은 해시 테이블의 크기와 상관없이 데이터를 계속 저장할 수 있다는 장점이 있습니다.
- 해시 테이블이 꽉 차도 데이터를 계속 저장할 수 있으며, 충돌이 발생해도 연결 리스트를 순회하면서 해당 요소를 찾거나 삽입할 수 있습니다.
- Java의
HashMap과HashSet은 Separate Chaining(체이닝) 방식을 사용하여 충돌을 처리합니다.- 이 방식은 해시 테이블의 각 인덱스가 연결 리스트(또는 트리)를 가지도록 구현되며, 동일한 해시코드를 가진 데이터를 체이닝으로 관리합니다.
- 체이닝 방식에서는 충돌이 발생해도 해당 연결 리스트를 순회하며 데이터를 찾거나 삽입할 수 있습니다.
1.3.3. Java의 최적화: 트리로의 변환 (Java 8)
- Java 8부터는
HashMap과HashSet에서 체이닝 방식의 연결 리스트(버킷 길이)가 일정 길이(6~8)를 넘어서면 자동으로 트리 구조(레드-블랙 트리)로 변환됩니다.- 이로 인해 검색 성능이
O(log n)으로 개선되며, 연결 리스트 기반의 순회 비용을 줄일 수 있습니다. - 이 최적화는 해시 충돌이 심각하게 발생하는 경우에 유리하며, 대용량 데이터 처리에 특히 강점이 있습니다.
- 이로 인해 검색 성능이
- 또한, Java의 해시 테이블은 데이터가 추가됨에 따라 배열 크기를 자동으로 조정하며, 버킷의 적재율(load factor)에 따라 동적으로 용량을 늘립니다.
- 이로 인해 해시 테이블이 너무 꽉 차는 것을 방지하고, 성능 저하를 막을 수 있습니다.
1.4. Java에서의 hashCode()와 equals() 메서드
- Java에서 해시 기반 자료구조는
hashCode()와equals()메서드를 통해 데이터의 고유성을 판단합니다.hashCode(): 객체의 해시코드를 반환합니다.- 해시 기반 자료구조에서 데이터는 이 해시코드를 기반으로 저장됩니다.
equals(): 해시코드가 같은 경우 두 객체가 실제로 같은지 판단하는 데 사용됩니다.- 해시코드가 같다고 해서 객체가 같은 것은 아니므로,
equals()를 통해 객체의 값 비교가 이루어집니다.
- 해시코드가 같다고 해서 객체가 같은 것은 아니므로,
중요성
- hashCode()와 equals()는 함께 사용되어 객체의 동등성을 보장합니다.
hashCode()로 빠르게 검색할 수 있지만, 정확한 일치는equals()로 판단됩니다.
- Java의
HashMap,HashSet과 같은 자료구조에서 객체가 동일한지 판단할 때 두 메서드를 올바르게 오버라이딩하지 않으면 중복 데이터가 발생하거나 정확한 검색이 불가능할 수 있습니다.- 따라서 별도로 정의한 객체를
HashMap,HashSet, 등에 담을때는 반드시 hashCode()와 equals()를 올바르게 오버라이딩 해야합니다.
- 따라서 별도로 정의한 객체를
2. Hash 기반 Set & Map의 공통적인 동작 원리
2.1. 해시 기반 자료구조의 특징
HashSet과HashMap은 모두 해시 테이블을 기반으로 동작하는 자료구조입니다.- 이 자료구조는 해시 함수를 사용하여 데이터를 효율적으로 저장하고 검색할 수 있습니다.
- 데이터를 저장할 때는 해시 함수가 데이터를 특정 위치(버킷)로 매핑하며, 이를 통해 빠른 검색 속도를 제공합니다.
- 빠른 데이터 접근: 해시 테이블을 사용하기 때문에, 평균적으로 삽입, 검색, 삭제 연산의 시간 복잡도는 O(1)입니다.
- 이는 다른 선형 탐색 자료구조에 비해 매우 빠른 성능을 제공합니다.
- 순서 보장 없음:
HashSet과HashMap은 삽입된 순서가 보장되지 않으며, 해시 테이블의 해시 값에 따라 무작위로 저장됩니다.- 즉, 데이터는 삽입 순서와 상관없이 저장되므로 순서를 신경 써야 하는 경우
LinkedHashSet이나LinkedHashMap같은 자료구조를 사용해야 합니다.
- 즉, 데이터는 삽입 순서와 상관없이 저장되므로 순서를 신경 써야 하는 경우
- 충돌 처리: 앞서 설명한 대로, 해시 테이블에서는 해시 충돌이 발생할 수 있으며, Java에서는 이 충돌을 처리하기 위해 Separate Chaining(체이닝) 방식을 사용합니다.
- 각 해시 버킷에 연결 리스트를 저장하고, 연결 리스트를 순회하며 동일한 해시 값을 가진 데이터를 처리합니다.
2.2. 중복 허용하지 않음
- Hash 기반 자료구조의 중요한 특징은 중복을 허용하지 않는 것입니다.
HashSet:Set인터페이스를 구현한HashSet은 중복된 값을 허용하지 않습니다.- 요소를 추가할 때 해시 함수를 사용해 고유한 해시 값을 생성하고, 동일한 해시 값을 가진 요소가 이미 존재하면 새로운 값이 삽입되지 않습니다.
HashSet은 고유한 값들의 집합을 표현하며, 중복된 값이 포함될 수 없다는 점이 핵심입니다.
HashMap:Map인터페이스를 구현한HashMap은 중복된 키를 허용하지 않으며, 하나의 키에 하나의 값만 매핑될 수 있습니다.- 동일한 키를 여러 번 추가하면 기존 값이 덮어씌워지며 중복 키는 허용되지 않습니다.
- 이는
HashSet에서 중복된 값이 허용되지 않는 것과 유사한 개념으로,HashMap은 고유한 키를 통해 값에 접근합니다.
- 따라서,
HashSet은 고유한 값을 저장하고,HashMap은 고유한 키를 사용해 값을 저장하며, 둘 다 중복된 데이터를 허용하지 않는다는 공통점을 가집니다.
2.3. HashSet과 HashMap의 데이터 구조
- HashSet은 내부적으로
HashMap을 사용하여 데이터를 저장합니다.HashSet에서 값을 추가할 때 실제로는 해당 값을 키로 하여HashMap에 저장되며, 키는 저장된 값을 의미하고, 값은 항상 PRESENT라는 상수로 설정됩니다.- 이 구조를 통해
HashSet은 고유한 값을 저장하는 간단한 자료구조를 구현할 수 있습니다.
- HashMap은 해시 테이블을 이용해 키-값 쌍을 저장합니다.
- 각 키는 고유한 해시 값을 가지고 있으며, 해시 값에 따라 해시 테이블에 저장됩니다. - 해시 충돌이 발생하면 연결 리스트 또는 트리로 관리되며, 키를 통해 빠르게 값을 조회할 수 있습니다.
2.4. 순서와 성능 최적화
- 순서가 보장되지 않음:
HashSet과HashMap은 해시 값에 따라 데이터가 저장되기 때문에 삽입된 순서를 유지하지 않습니다.- 순서를 유지해야 할 경우
LinkedHashSet이나LinkedHashMap을 사용하는 것이 더 적합합니다.
- 순서를 유지해야 할 경우
- 성능 최적화: 해시 테이블은 데이터의 적재율(load factor)에 따라 동적으로 크기가 조정됩니다.
- 해시 테이블이 가득 차면 자동으로 배열 크기가 늘어나며, Java 8부터는 버킷 길이가 일정 길이를 넘어서면 연결 리스트가 트리로 변환되어 검색 속도를 향상시키는 최적화가 적용됩니다.
3. HashSet & HashMap
3.1. HashSet
- 기본 원리: 해시 테이블을 사용하여 요소를 저장하며, 중복을 허용하지 않는
Set구현체입니다. - 중복 제거:
hashCode()와equals()메서드를 통해 중복 여부를 판단합니다. - 순서 없음: 삽입된 순서는 유지되지 않으며, 데이터는 임의의 순서로 저장됩니다.
- Null 허용:
HashSet은 단 하나의null요소를 허용합니다. - 빠른 검색/삽입: 평균적으로
O(1)시간 복잡도로 요소를 삽입, 삭제, 검색할 수 있습니다.
import java.util.HashSet;
public class HashSetExample {
public static void main(String[] args) {
HashSet<String> set = new HashSet<>();
set.add("apple");
set.add("banana");
set.add("apple"); // 중복된 요소는 저장되지 않음
System.out.println(set); // [banana, apple]
}
}3.2. HashMap
- 기본 원리: 해시 테이블을 사용하여 Key-Value 쌍을 저장하는
Map구현체입니다. - Key의 중복 제거: Key는 중복될 수 없으며, 동일한 Key로 데이터를 추가하면 기존 값을 덮어씁니다.
- 순서 없음: 삽입된 순서와 관계없이 저장됩니다.
- Null 허용:
HashMap에서는 Key와 Value 모두null을 허용합니다.- 단, Key는 하나의
null값만 허용됩니다.
- 단, Key는 하나의
- 빠른 검색/삽입: 평균적으로
O(1)시간 복잡도로 Key에 접근할 수 있습니다.
import java.util.HashMap;
public class HashMapExample {
public static void main(String[] args) {
HashMap<String, Integer> map = new HashMap<>();
map.put("apple", 1);
map.put("banana", 2);
map.put("apple", 10); // "apple" Key의 Value가 덮어씌워짐
System.out.println(map); // {banana=2, apple=10}
}
}4. LinkedHashSet & LinkedHashMap
4.1. LinkedHashSet
- 기본 원리:
HashSet과 유사하게 해시 테이블을 사용하지만, 요소의 삽입 순서를 유지하는Set구현체입니다. - 중복 제거:
hashCode()와equals()메서드를 통해 중복 여부를 판단합니다. - 순서 유지: 요소가 삽입된 순서대로 데이터를 저장하고, 그 순서를 기반으로 순회합니다.
- Null 허용:
null요소를 하나 허용합니다.
import java.util.LinkedHashSet;
public class LinkedHashSetExample {
public static void main(String[] args) {
LinkedHashSet<String> set = new LinkedHashSet<>();
set.add("apple");
set.add("banana");
set.add("apple"); // 중복된 요소는 저장되지 않음
System.out.println(set); // [apple, banana] (삽입 순서 유지)
}
}4.2. LinkedHashMap
- 기본 원리:
HashMap과 유사하게 해시 테이블을 사용하지만, 삽입된 순서를 유지하는 Map 구현체입니다. - Key의 중복 제거: Key는 중복될 수 없으며, 동일한 Key로 데이터를 추가하면 기존 값을 덮어씌웁니다.
- 순서 유지: 요소가 삽입된 순서대로 데이터를 저장하고, 그 순서를 기반으로 순회합니다.
- 특히
LinkedHashMap에서는 액세스 순서(Access Order)를 기반으로 순서를 유지할 수 있어, 최근에 액세스한 항목을 기준으로 정렬을 변경할 수 있습니다. - 이 기능은 LRU(Least Recently Used) 캐시와 같은 구조를 구현할 때 유용하게 사용할 수 있습니다.
- 특히
- Null 허용: HashMap과 마찬가지로 Key와 Value에 대해 null 값을 허용합니다.
import java.util.LinkedHashMap;
public class LinkedHashMapExample {
public static void main(String[] args) {
LinkedHashMap<String, Integer> map = new LinkedHashMap<>();
map.put("apple", 1);
map.put("banana", 2);
map.put("apple", 10); // "apple" Key의 Value가 덮어씌워짐
System.out.println(map); // {apple=10, banana=2} (삽입 순서 유지)
}
}5. Hash기반 Set & Map 활용 팁
- Hash 기반 자료구조는 데이터의 빠른 검색, 삽입, 삭제가 요구되는 상황에서 특히 유용합니다.
- 이 자료구조들은 해시 테이블을 사용해 평균적으로
O(1)시간 복잡도를 제공하므로, 대량의 데이터를 다루는 상황에서 매우 효율적입니다.
- 이 자료구조들은 해시 테이블을 사용해 평균적으로
5.1. 언제 HashSet과 HashMap을 사용해야 할까?
- 순서가 중요하지 않은 경우:
HashSet과HashMap은 순서를 보장하지 않기 때문에 삽입된 순서와 관계없이 데이터를 처리할 수 있습니다.- 따라서 데이터의 순서가 중요하지 않은 경우 이들 자료구조가 적합합니다.
- 빠른 검색/삽입/삭제가 필요한 경우: 해시 테이블을 기반으로 동작하기 때문에 평균적으로
O(1)시간 복잡도로 데이터를 빠르게 검색, 삽입, 삭제할 수 있습니다.- 성능 최적화를 위해 초기 용량(initialCapacity)과 적재율(load factor)을 조정하면 충돌과 재해시(resizing) 빈도를 줄여 효율적으로 사용할 수 있습니다.
- 예를 들어, 대량의 데이터를 한꺼번에 저장할 경우 initialCapacity를 크게 설정해 초기 리사이징 비용을 줄일 수 있습니다.
- 특히 중복된 요소나 키를 허용하지 않는 환경에서 유용합니다.
- 성능 최적화를 위해 초기 용량(initialCapacity)과 적재율(load factor)을 조정하면 충돌과 재해시(resizing) 빈도를 줄여 효율적으로 사용할 수 있습니다.
- 대규모 데이터 처리: 중복 없이 빠르게 데이터를 추가하고 삭제해야 하는 상황에서 매우 효율적입니다.
5.2. 언제 LinkedHashSet과 LinkedHashMap을 사용해야 할까?
- 순서가 중요한 경우:
LinkedHashSet과LinkedHashMap은 데이터의 삽입 순서를 보장합니다.- 그래서 삽입된 순서대로 데이터를 관리해야 하는 경우에 적합합니다.
- 예를 들어, 삽입 순서를 유지한 채로 데이터를 반복하거나 정렬된 순서로 데이터를 저장할 필요가 없는 경우 유용합니다. (정렬된 데이터가 필요하면 다음에 다룰 Tree구조 자료를 쓰면됩니다)
- 빠른 성능을 유지하면서 순서 보장이 필요할 때: 입력 순서를 유지하면서도 해시 기반의 빠른 성능을 요구하는 경우,
LinkedHashSet과LinkedHashMap이 적합한 선택이 될 수 있습니다.- 특히, 순차적으로 데이터를 처리해야 하면서도 삽입, 삭제, 검색의 성능을 유지해야 할 때 적합합니다.
5.3. Hash 기반 자료구조의 장단점
장점
- 빠른 데이터 접근: 해시 테이블을 기반으로 하기 때문에 평균적으로
O(1)시간 복잡도로 빠른 데이터 삽입, 삭제, 검색이 가능합니다. - 중복 허용 안 함:
HashSet은 중복된 요소를,HashMap은 중복된 키를 허용하지 않으므로, 데이터의 유일성을 보장할 수 있습니다. - 효율적인 메모리 사용: 해시 기반 자료구조는 데이터의 크기에 따라 동적으로 크기를 조절할 수 있으며, 특히 충돌 처리에 있어서도 효율적입니다.
단점
- 순서 보장 없음:
HashSet과HashMap은 기본적으로 데이터의 삽입 순서를 보장하지 않기 때문에, 데이터가 저장된 순서대로 처리되어야 하는 경우에는 적합하지 않습니다. - 해시 충돌: 해시 테이블에서는 어쩔 수 없이 충돌이 발생할 수 있습니다. 해시 충돌이 자주 발생하면, 성능 저하가 생길 수 있습니다.
- Java에서는 Separate Chaining과 트리로 충돌을 처리하지만, 극단적인 경우에는 성능이
O(n)까지 떨어질 수 있습니다. - 이를 방지하기 위해 load factor 설정이 중요한데, 기본 값인 0.75를 유지하거나 데이터 성격에 맞게 조정하여 충돌 빈도를 줄이고 성능을 개선할 수 있습니다.
- 또한, 초기 용량(initialCapacity)을 적절히 설정하면 테이블 리사이징을 줄여 성능을 최적화할 수 있습니다.
- Java에서는 Separate Chaining과 트리로 충돌을 처리하지만, 극단적인 경우에는 성능이
- 메모리 사용량 증가: 해시 기반 자료구조는 내부적으로 해시 테이블을 사용하기 때문에, 초기 해시 테이블 크기와 load factor(적재율) 설정에 따라 불필요한 메모리를 차지할 수 있습니다.
- 특히 데이터가 적을 때도 초기 크기가 클 경우, 적재율이 높아지기 전에 공간이 많이 낭비될 수 있습니다.
- 기본적으로
HashMap과HashSet은 load factor를 0.75로 설정하고, 일정한 비율을 넘으면 자동으로 크기를 늘려 충돌을 줄이고 성능을 최적화합니다.
마무리
-
이번 포스팅에서는 Java의
HashSet,HashMap을 비롯한 Hash 기반의Set과Map구현체들에 대해 다뤘습니다.- 해시 함수를 통해 빠른 검색, 삽입, 삭제가 가능한 구조로, 대규모 데이터를 처리할 때 특히 강력한 성능을 자랑하는 자료구조입니다.
-
또한, 해시 충돌 처리 방식과 Java에서 이를 최적화하는 방법, 그리고
LinkedHashSet,LinkedHashMap을 통해 삽입 순서를 유지하면서 해시 기반 성능을 유지하는 방법도 살펴보았습니다. -
다음 포스팅에서는 트리 기반 자료구조로 넘어가서,
TreeSet,TreeMap등을 중심으로 정렬된Set과Map데이터를 다루는 방법을 구체적으로 살펴볼 예정입니다.

일 때문에 포스팅은 잠시 쉬어요 ㅠ // Now. 수학 강사 (광교) // Prev. Machine Learning (AI) Engineer & BackEnd Engineer