Collection Framework & Map - 개요
- 이번 포스팅부터는 Java의 Collection과 Map Framework에 대해 소개해 보려합니다.
- 프레임워크의 기반이 되는 자료구조에 대한 개념은 따로 시리즈로 작성할 것이고, 본 시리즈에서는 Java에서 제공하는 자료구조들과 그에 따른 메서드들을 정리할 것입니다.
Java의 Collection Framework와 Map Interface
- Java에서는 데이터 구조와 알고리즘을 지원하는 강력한 표준 라이브러리를 제공하며, 이 중 Collection Framework와 Map은 데이터 관리와 처리의 핵심적인 역할을 합니다.
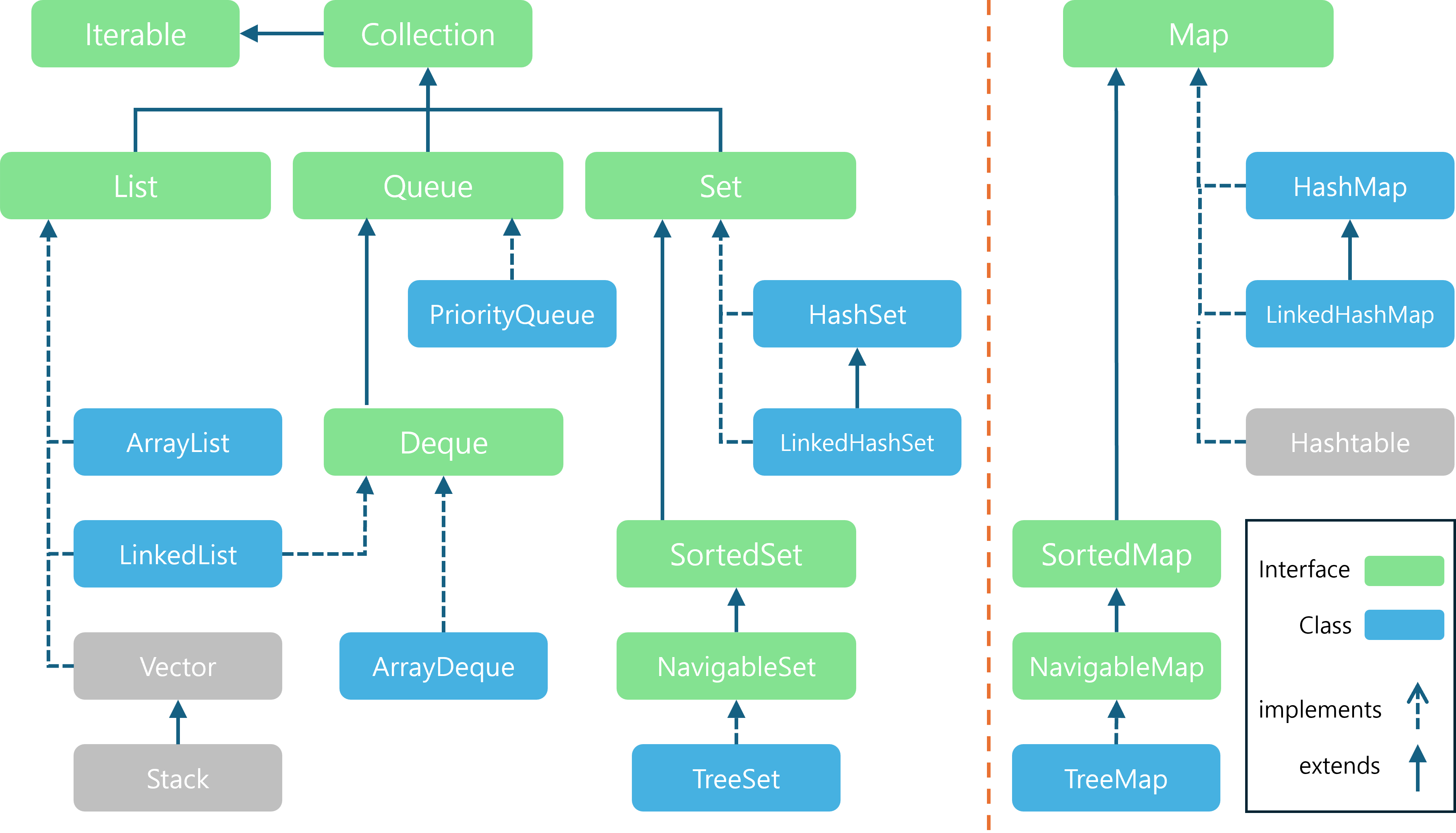
- 위 이미지는 주로 쓰이는 Collection Framework와 Map Interface의 상속 및 구현 관계를 제가 직접 그려본 것입니다.
- 회색으로 표시된
Vector,Stack,Hashtable은 Java 초창기에 만들어져서 하위 버전 호환을 위해 남겨진 Legacy Class들입니다.- 구조적인 문제들이 있어서 현재는 더이상 업데이트되지 않고 거의 쓰이지 않기 때문에 본 시리즈에서도 따로 정리하진 않을 예정입니다.
- Collection Framework
- List 구현체 :
ArrayList,LinkedList - Queue 구현체 :
PriorityQueue,ArrayDeque,LinkedList - Deque 구현체 :
ArrayDeque,LinkedList - Set 구현체 :
HashSet,LinkedHashSet,TreeSet
- List 구현체 :
- Map Interface 구현체 :
HashMap,LinkedHashMap,TreeMap
- 회색으로 표시된
1. Collection Framework & Map Interface 소개
- Java에서 Collection Framework와 Map Interface는 데이터 관리와 처리의 핵심적인 역할을 합니다.
- 이들 프레임워크는 다양한 자료구조와 알고리즘을 통해 데이터를 효율적으로 관리하고 처리할 수 있는 강력한 기능을 제공합니다.
- 이러한 기능들은 코드를 보다 간결하고 가독성 있게 작성할 수 있도록 도와주며, 더 나아가 프로그램의 성능을 최적화할 수 있는 유연성도 갖추고 있습니다.
Collection Framework와 Map의 중요성
1. 데이터를 체계적으로 관리하기 위한 필수 도구
- 컬렉션(Collection)은 객체의 집합을 의미합니다.
- 이 객체들은 동적으로 크기가 변할 수 있고 다양한 형태로 저장 및 관리됩니다.
- 배열과 달리, 컬렉션은 정적 크기를 갖지 않으므로 필요한 만큼 동적으로 데이터를 추가하거나 삭제할 수 있습니다.
- Map은
키-값 쌍을 기반으로 데이터를 관리하며,키(Key)를 기준으로 중복을 허용하지 않고 값을 저장할 수 있는 유용한 자료구조입니다.- 특히, 데이터 탐색, 삽입, 삭제 등을 효율적으로 처리할 수 있습니다.
2. 코드의 가독성과 유지보수성 향상
- Java의
Collection과MapFramework는 자료구조의 구현과 관련된 복잡한 내부 동작을 추상화하여, 개발자가 데이터 처리 로직에 집중할 수 있도록 도와줍니다.- 예를 들어,
ArrayList와 같은 클래스는 배열 기반의 데이터 관리를 효율적으로 수행하지만, 개발자가 직접 배열의 크기를 관리하거나 요소를 삽입/삭제하는 것에 신경 쓸 필요가 없습니다. LinkedList,HashSet,TreeSet등의 다양한 자료구조도 마찬가지로, 개발자는 데이터가 어떻게 저장되고 관리되는지보다 어떤 방식으로 데이터를 처리할 것인지에 집중할 수 있습니다.
- 예를 들어,
3. 다양한 데이터 처리 방식 제공
List,Set,Queue등의 자료구조는 각각의 고유한 특성과 사용처를 가지고 있습니다.- 예를 들어,
List는 순서를 보장하면서 데이터를 저장하고,Set은 중복을 허용하지 않는 데이터 집합을 처리하며,Queue는 FIFO(First In, First Out) 방식으로 데이터를 관리합니다.
- 예를 들어,
- 이러한 자료구조를 통해 개발자는 구체적인 요구사항에 맞는 적합한 구조를 선택할 수 있으며, 이를 통해 더욱 효율적인 프로그램을 작성할 수 있습니다.
4. 성능과 메모리 효율성
- 다양한 구현체를 통해 상황에 맞는 자료구조를 선택할 수 있고, 그에 따라 성능과 메모리 사용을 최적화할 수 있습니다.
- 예를 들어,
HashSet과TreeSet은 모두 중복을 허용하지 않는Set구현체이지만,HashSet은 해시 테이블을 이용해 빠른 탐색 성능을 제공하는 반면,TreeSet은 이진 트리를 이용해 요소를 정렬된 순서로 저장합니다.
- 예를 들어,
Map역시HashMap과TreeMap처럼, 각각 해시 테이블 기반의 빠른 탐색을 제공하거나 이진 트리를 이용한 정렬된 키 값을 제공합니다.
5. 병렬 처리와 스레드 안전성
- Java의 동기화된 컬렉션(Synchronized Collections)과 병렬 스트림(Parallel Streams)을 활용하면, 멀티 스레드 환경에서 데이터의 일관성을 유지하거나, 대규모 데이터에 대한 병렬 처리를 쉽게 구현할 수 있습니다.
- 이러한 기능을 통해 Java Collection Framework와 Map은 멀티 스레드 프로그램의 성능을 높이거나 동시성 문제를 해결할 수 있는 도구로 활용될 수 있습니다.
2. Collection Interface
- Java의
Collection Interface는List,Set,Queue와 같은 여러 데이터 구조의 공통적인 동작을 정의하는 최상위 인터페이스입니다.- Java Collection Framework는 이 인터페이스를 기반으로 다양한 자료구조를 구현하고 있으며, 이를 통해 개발자는 일관된 방법으로 데이터를 저장, 삭제, 조회할 수 있습니다.
2.1 Collection Interface의 역할
- 데이터 그룹 관리:
Collection은 데이터를 하나의 그룹으로 관리하기 위한 기본 틀을 제공합니다.- 이 인터페이스를 구현한 클래스들은 모두 데이터를 추가, 삭제, 순회 등의 기능을 제공하며, 각 클래스가 제공하는 구체적인 방법은 자료구조에 따라 다릅니다.
- 일관된 API 제공:
Collection인터페이스를 상속받은 모든 구현체는 공통된 메서드 집합을 가지고 있어, 개발자는 자료구조의 구체적인 구현 방식에 상관없이 데이터를 처리할 수 있습니다.
2.2 주요 메서드
- Collection 인터페이스는 데이터를 처리하기 위한 기본적인 메서드를 정의합니다.
- 이를 통해 모든 자료구조에서 일관된 방식으로 데이터를 처리할 수 있습니다.
- 본 포스팅에서는 주로 많이 쓰이는 것들을 위주로 간단하게 소개하고, 자세한 메서드들은 각 구현체들을 통해 정리해보도록 할 예정입니다!
add(E e): 컬렉션에 요소를 추가합니다.remove(Object o): 특정 요소를 컬렉션에서 제거합니다.size(): 컬렉션의 크기를 반환합니다.isEmpty(): 컬렉션이 비어 있는지 확인합니다.contains(Object o): 컬렉션이 특정 요소를 포함하는지 확인합니다.iterator(): 컬렉션의 요소를 순회할 수 있는 Iterator를 반환합니다. (Iterable을 상속 받았기 때문에 사용가능한 메서드입니다.)
2.3 Collection의 주요 하위 인터페이스
List: 순서를 유지하면서 중복된 요소를 허용하는 자료구조입니다.- 대표적으로
ArrayList,LinkedList등이 있습니다.
- 대표적으로
Set: 중복된 요소를 허용하지 않는 집합을 관리합니다.HashSet,TreeSet등이 대표적인 구현체입니다.
Queue: FIFO(First In, First Out) 방식을 따르는 자료구조로, 주로 대기열을 구현할 때 사용됩니다.PriorityQueue,ArrayDeque등이 있습니다.
Deque: 양쪽 끝에서 요소를 추가하거나 제거할 수 있는 자료구조입니다.ArrayDeque,LinkedList가 이를 구현합니다.
2.4 Collection Framework의 유연성
Collection인터페이스는 상속 구조 덕분에 다양한 자료구조를 선택할 수 있는 유연성을 제공합니다. (다형성을 활용한 것이라 해석할 수 있습니다)- 개발자는 데이터의 특성과 요구사항에 따라
List,Set,Queue등 적절한 자료구조를 선택하고 사용할 수 있으며, 필요에 따라LinkedList와 같이 한 가지 자료구조에서 여러 인터페이스를 구현한 클래스도 활용할 수 있습니다.
3. Map Interface
Map Interface는 Java에서키(key)-값(value)쌍을 저장하는 자료구조를 정의하는 인터페이스입니다.- 다른 컬렉션과는 다르게, Map은 데이터를 키로 식별하고, 각 키는 고유하며, 하나의 키에 하나의 값을 연결할 수 있습니다.
- 이는 해시 테이블, 이진 트리 등 다양한 내부 구조를 통해 구현될 수 있습니다.
3.1 Map의 특징
- Key-Value 쌍으로 관리:
Map은 데이터를 키와 값의 쌍으로 관리하며, 키를 통해 값을 효율적으로 조회할 수 있습니다. - 고유한 키:
Map은 각 키가 고유해야 하며, 동일한 키로 여러 값을 저장할 수 없습니다. 반면에 값은 중복을 허용합니다. - 순서가 없는 저장: 대부분의
Map구현체는 요소들이 저장되는 순서를 보장하지 않으나, 일부는 입력 순서나 정렬된 순서를 유지합니다 (LinkedHashMap,TreeMap).
3.2 주요 메서드
- Map Interface는 키와 값을 관리하기 위한 메서드를 정의합니다.
- 이를 통해 데이터의 추가, 삭제, 조회 등의 작업을 일관된 방식으로 처리할 수 있습니다
- 본 포스팅에서는 주로 많이 쓰이는 것들을 위주로 간단하게 소개하고, 자세한 메서드들은 각 구현체들을 통해 정리해보도록 할 예정입니다!
put(K key, V value): Map에 주어진 키와 값을 추가합니다.- 이미 존재하는 키라면 해당 키의 값을 새로운 값으로 업데이트합니다.
get(Object key): 주어진 키에 해당하는 값을 반환합니다.- 키가 존재하지 않으면 null을 반환합니다.
remove(Object key): 특정 키에 해당하는 값과 키를 Map에서 제거합니다.containsKey(Object key): 특정 키가 Map에 존재하는지 확인합니다.keySet(): Map에 있는 모든 키를Set으로 반환합니다.values(): Map에 저장된 모든 값을Collection으로 반환합니다.- 중복은 허용하면서 순서는 보장되지 않기 때문에 상위 인터페이스인 Collection으로 반환하게 됩니다.
entrySet(): Map에 저장된 모든 키-값 쌍을Set<Map.Entry<K, V>>형태로 반환합니다.
3.3 Map의 주요 구현체
HashMap: 가장 많이 사용되는 Map 구현체로, 해시 테이블을 사용하여 키-값 쌍을 저장합니다.- 요소의 순서를 보장하지 않으며, 빠른 조회 성능을 제공합니다.
LinkedHashMap: HashMap의 확장으로, 저장된(입력된) 순서를 유지합니다.- 삽입 순서를 유지하면서 빠른 조회 성능을 제공합니다.
TreeMap: 이진 트리 구조(Red-Black Tree)를 사용하여 키를 정렬된 순서로 저장합니다.- 키의 자연 순서나 사용자 정의 비교자에 따른 순서로 데이터를 정렬할 수 있습니다.
3.4 Map의 활용
- Map Interface는 다음과 같은 상황에서 주로 사용됩니다
- 빠른 조회가 필요한 경우: 키를 이용한 빠른 조회가 가능하므로, 주로 데이터베이스 캐시, 환경 변수 저장, 세션 정보 관리 등에 활용됩니다.
- 데이터의 유일성을 보장해야 하는 경우: 키가 고유해야 하므로, 중복되지 않는 데이터를 관리해야 하는 상황에서 유용합니다.
- 예를 들어, 사용자 ID와 프로필 정보를 매핑하거나, 제품 코드와 제품 정보를 저장할 때 사용할 수 있습니다.
4. Legacy Class (Vector, Stack, Hashtable)
- Java의
Legacy Class들은 초창기에 개발된 컬렉션 클래스들로, 현재는 하위 호환성을 위해 남아 있는 상태입니다.- 하지만 구조적 한계나 성능 문제로 인해, 더 이상 새로 개발되는 프로젝트에서 사용되지 않으며, 대부분의 경우 Java Collections Framework에 포함된 최신 구현체들이 권장됩니다.
- 이들 클래스를 사용하는 대신, 현재는 더 나은 성능과 동시성 제어를 지원하는 최신 컬렉션 클래스를 사용하는 것이 바람직합니다.
5.1 Vector
Vector는 동기화된 동작을 제공하는 List의 초기 구현체입니다.- 멀티스레드 환경에서 안전하게 사용할 수 있지만, 불필요한 성능 저하가 발생할 수 있습니다.
- 현재는
ArrayList가 동기화된 List로 더 적합하게 사용됩니다.
5.2 Stack
Stack은 LIFO (Last In First Out) 구조를 구현한 클래스로,Vector를 상속받습니다.- 하지만, 스택 구조를 구현할 때는
Deque인터페이스의 구현체인ArrayDeque클래스를 사용하는 것이 권장됩니다.
- 하지만, 스택 구조를 구현할 때는
5.3 Hashtable
Hashtable은 동기화된 해시 테이블 구조로, Map 인터페이스의 초창기 구현체입니다.- 현재는 더 나은 성능을 제공하는
HashMap과, 동시성 처리를 위한ConcurrentHashMap이 그 역할을 대신하고 있습니다.
- 현재는 더 나은 성능을 제공하는
Legacy Class 대체 구현체
- Vector →
ArrayList - Stack → Deque (특히
ArrayDeque) - Hashtable →
HashMap또는ConcurrentHashMap
마무리
- Java의
Collection Framework와Map Interface는 데이터 처리의 핵심 도구로, 다양한 자료구조를 손쉽게 사용할 수 있도록 해줍니다.
- 이번 포스팅에서는 그 개요와 구조에 대해 간략히 다루어 보았습니다.
- 다음 포스팅 부터는 각 주요 구현체들의 사용법과 특징을 깊이 있게 다루며, 코드 예시를 통해 실제로 어떻게 활용할 수 있는지 알아보겠습니다.

일 때문에 포스팅은 잠시 쉬어요 ㅠ // Now. 수학 강사 (광교) // Prev. Machine Learning (AI) Engineer & BackEnd Engineer