
본 시리즈에서는 데이터베이스의 개념을 정리하고 필요시 실습을 진행합니다.
- 실습 환경(Server)
- 원격 서버 (OS) : AWS-EC2 (
Ubuntu-24.04) - DBMS(관리 시스템) : MariaDB (
10.11.8-MariaDB)
- 원격 서버 (OS) : AWS-EC2 (
- 실습 환경(Client)
- Client OS : Windows 11
- DB Tool (IDE) : JetBrains DataGrip (
2024.2.2) - Java (JDBC) : JDK 21 (
correto-21) - Java IDE : IntelliJ IDEA (
Ultimate Edition)
- DB 실습 예제
- MySQL
world database - https://dev.mysql.com/doc/index-other.html
- MySQL
DataBase - DB & DBMS 개요
1. DBMS(DataBase Management System)
1.1 Data와 File System
- 데이터(Data)는 현실의 정보를 컴퓨터가 처리할 수 있는 형태로 변환한 것으로, 디지털 환경에서 중요한 자원입니다.
- 파일 시스템(File System)은 데이터를 파일 단위로 저장하고 관리하는 전통적인 방법으로, 운영 체제의 일부로 작동하여 파일의
생성,삭제,검색,수정등을 처리합니다.- 그러나 파일 시스템은
데이터의 중복,데이터 일관성 문제,다중 사용자 환경에서의 접근 제어 문제를 갖고 있으며, 이를 해결하는 데 한계가 있습니다.
- 그러나 파일 시스템은
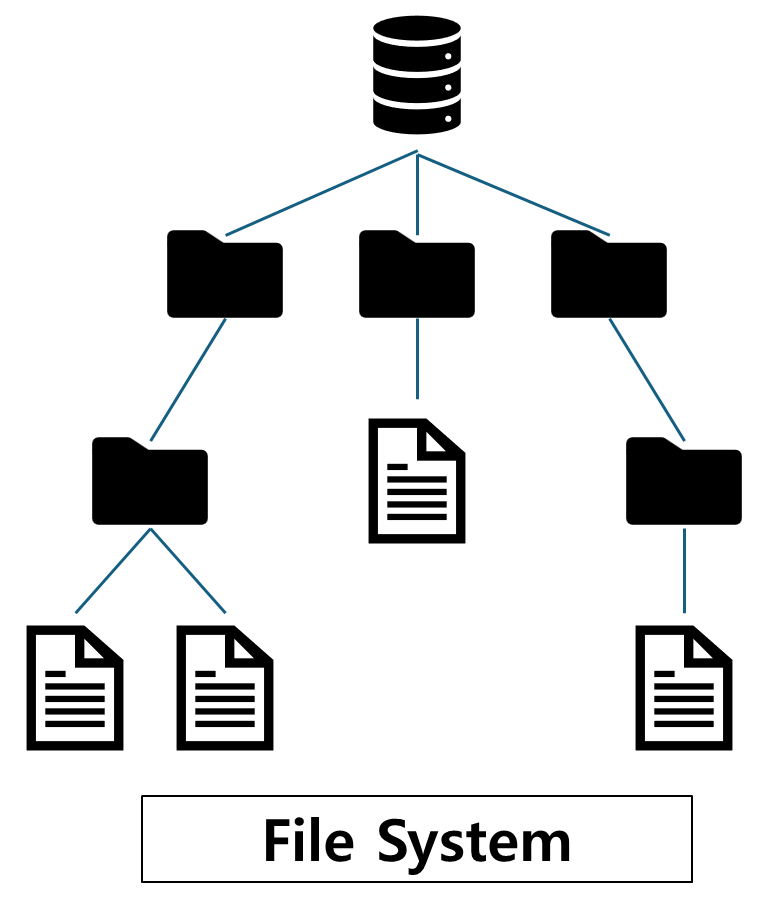
이러한 한계를 극복하기 위해 개발된 것이 데이터베이스 시스템(Database System)이며, 데이터베이스는 다량의 데이터를 구조화하여 관리할 수 있는 환경을 제공합니다.
- 파일 시스템과 달리 데이터베이스 시스템은
데이터의 중복을 최소화하고,데이터 일관성 및 무결성을 보장할 수 있는 기능을 갖추고 있습니다.
1.2 DataBase란?
데이터베이스(Database)는 데이터를 효율적으로 저장하고 관리하기 위한 시스템입니다.
- 데이터베이스는 다양한 형태로 구조화된 데이터를 수집하고, 이를 빠르게 검색하고 수정할 수 있도록 설계되어 있습니다.
- 데이터를 체계적으로 관리함으로써 중복 데이터를 줄이고, 데이터의 무결성을 유지할 수 있습니다.
데이터베이스는 데이터를 효과적으로 활용할 수 있도록 스키마(Schema)라는 구조를 가지고 있으며, 사용자는 이러한 스키마를 통해 데이터의 유형과 관계를 정의할 수 있습니다.
- 즉, 데이터베이스는 데이터를 저장하는 단순한 창고 역할을 넘어, 데이터를 관리하고 분석할 수 있는 강력한 도구로 작용합니다.
1.3 DBMS란?
DBMS(DataBase Management System)는 데이터베이스를 체계적으로 관리하기 위한 시스템으로, 데이터의 생성, 저장, 검색, 수정, 삭제 등을 효과적으로 처리하는 시스템 소프트웨어입니다.
- DBMS는 데이터의 중복을 최소화하고, 데이터의 무결성과 일관성을 보장하여 사용자에게 신뢰성 있는 데이터를 제공합니다.
- 이를 통해 데이터의 효율적인 관리와 분석이 가능해지며, 데이터의 접근 권한을 설정하고 제어하여 보안성을 높일 수 있습니다.
DBMS는 데이터의 관리에 특화된 프로그램으로, 대규모 데이터 처리 환경에서 필수적이며, 다양한 유형이 존재합니다.
DBMS의 유형
DBMS는 여러 구조적 방식에 따라 구분되며, 주요 유형은 다음과 같습니다:
- 계층형 DBMS:
- 데이터를 트리 구조로 관리하여 부모-자식 관계를 설정해 데이터를 저장합니다.
- 주로
조직 구조나파일 시스템과 같은 계층적 데이터에 사용됩니다.
- 망형(네트워크형) DBMS:
- 데이터가 네트워크 구조로 연결되며, 복잡한 관계를 표현할 수 있습니다.
- 네트워크형 DBMS는 효율적인 관계 표현이 필요한 환경에서 사용됩니다.
- 관계형 DBMS (RDBMS):
- 데이터를 테이블 형태로 관리하며, 정형화된 데이터를 다루는 데 효과적입니다.
- 예:
MySQL/MariaDB,Oracle,PostgreSQL
- 객체지향형 DBMS:
- 객체 지향 개념을 기반으로 데이터를 저장하고 관리하며, 복잡한 데이터 구조를 처리하는 데 적합합니다.
- 예:
PostgreSQL
- 객체관계형 DBMS (ORDBMS):
- 관계형 DBMS에 객체 지향 개념을 결합한 형태로, RDBMS와 객체 지향 DBMS의 장점을 혼합하여 사용합니다.
- 예:
PostgreSQL
또한 데이터의 형태에 따라 정형화된 데이터를 관리하는 RDBMS와, 비정형 데이터를 관리하는 NoSQL로 구분할 수 있습니다.
- NoSQL은 주로 대용량 비정형 데이터와 비관계형 데이터를 처리할 때 유용하며, 대표적으로
MongoDB,Cassandra,DynamoDB등이 있습니다.
DB와 DBMS의 차이
- 데이터베이스 (DB): 데이터가 저장되는 공간이자, 데이터를 체계적으로 정리하여 보관하는 저장소입니다.
- DBMS: 이러한 데이터베이스를 운영하고 관리하는 소프트웨어로, 데이터의
접근,저장,보안등을 담당합니다.
본 시리즈에서는 이러한 DBMS 중에서 RDMBS(MariaDB)로 실습을 진행합니다.
2. RDBMS Instance & User
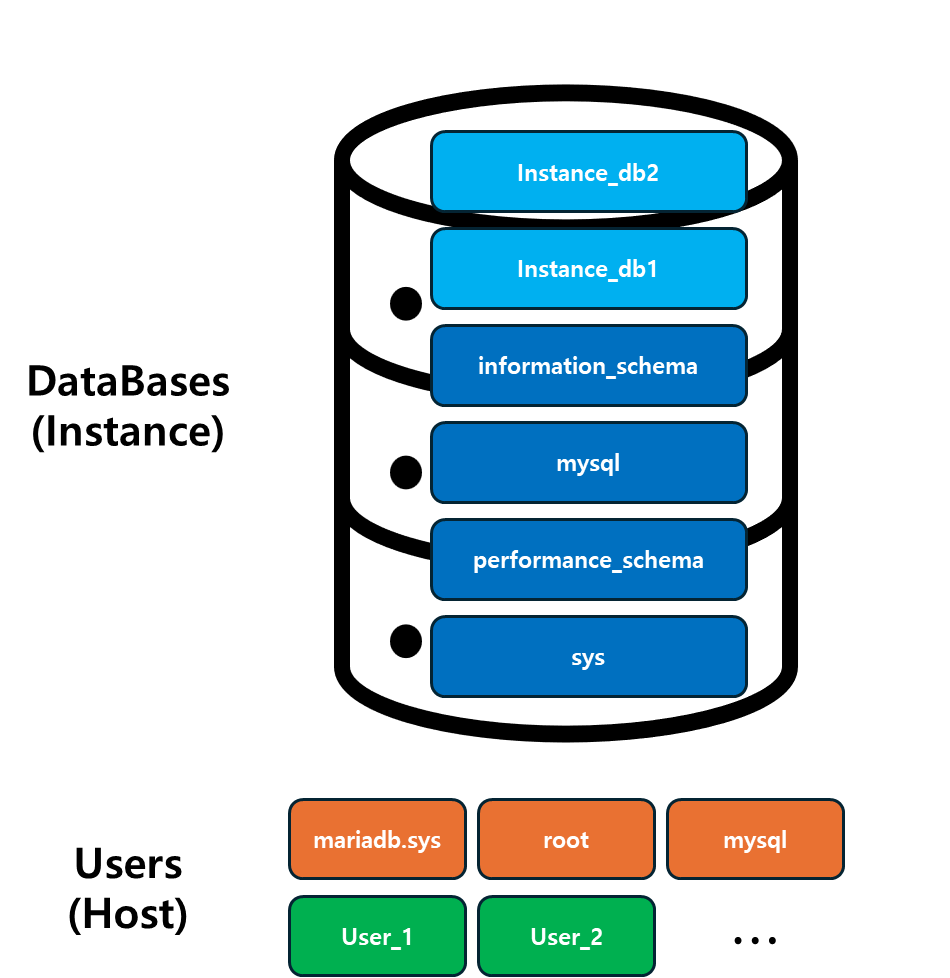
2.1 인스턴스와 사용자(Host)
인스턴스(Instance)는 DBMS 소프트웨어가 실행되어 데이터베이스를 관리하는 구체적인 프로세스를 의미합니다.
- RDBMS에서 인스턴스는 데이터베이스가 메모리 상에서 동작하며 사용자 요청에 따라 데이터 입출력과 같은 작업을 수행하게 됩니다.
- 인스턴스는 DBMS가 실행될 때마다 생성되며, 하나의 DBMS가 다수의 인스턴스를 가질 수도 있습니다.
사용자(Host)는 DBMS와 데이터베이스에 접근할 수 있는 권한을 가진 개별 계정입니다.
- 각 사용자는 데이터베이스에 접근하고 특정 작업을 수행할 수 있는 권한을 가지며, 이를 통해 데이터베이스의 보안을 강화할 수 있습니다.
- 사용자는 주로 다음과 같은 유형으로 나뉩니다:
- DBA (Database Administrator): 데이터베이스 시스템을 설치, 유지보수, 백업, 복구 등의 작업을 담당하는 관리자 계정입니다. (일반적으로는
root라는 이름의 관리자 계정입니다.) - 일반 사용자(User): 주어진 권한에 따라 데이터베이스에 접근하고 데이터를 조회, 삽입, 수정, 삭제 등의 작업을 수행할 수 있는 일반 계정입니다.
- DBA (Database Administrator): 데이터베이스 시스템을 설치, 유지보수, 백업, 복구 등의 작업을 담당하는 관리자 계정입니다. (일반적으로는
RDBMS 환경에서는 각 사용자 계정에 대해 접근 권한과 역할을 지정하여 데이터 보안을 강화합니다.
- 예를 들어, 사용자가 데이터를 조회할 수 있지만 수정은 할 수 없도록 설정할 수 있습니다.
2.2 DB의 명명규칙
데이터베이스와 테이블, 컬럼 등의 객체에 이름을 부여할 때는 일관된 명명 규칙을 설정하는 것이 중요합니다.
- 이는 코드의 가독성을 높이고, 협업 환경에서의 혼동을 줄이며, 유지보수를 용이하게 합니다
- 데이터베이스 객체에 이름을 부여할 때는 스네이크 표기법(snake_case)을 주로 사용합니다.
- 또한, SQL 예약어는 주로 대문자로 작성하여 가독성을 높이는 것이 일반적입니다.
일반적인 명명 규칙은 다음과 같습니다:
-
스네이크 표기법 사용: 객체 이름을 작성할 때, 단어 사이를 밑줄(
_)로 구분하는 스네이크 표기법(snake_case)을 사용합니다.- 예를 들어,
user_info와 같이 표기하여 객체의 의미를 직관적으로 전달합니다.
- 예를 들어,
-
SQL 예약어는 대문자로 표기: SQL 구문에서 예약어(SELECT, INSERT, UPDATE 등)는 주로 대문자로 작성하여 SQL 코드의 가독성을 높이는 것이 관례입니다.
- 예약어 사용 시 소문자로 사용해도 큰 상관은 없지만, 일관된 스타일을 유지하는 것이 좋습니다.
-
영문 소문자 사용: 일반적으로 데이터베이스 객체 이름은 모두 소문자로 작성합니다.
- 하나의 이름에 대소문자를 혼용할 경우 혼란을 줄 수 있기 때문에, 테이블과 컬럼 이름 등은 소문자로 작성하는 것이 권장됩니다.
-
알파벳, 숫자, 밑줄(_)만 사용:
공백이나특수 문자는 피하고, 단어 간 구분이 필요한 경우 밑줄(_)을 사용합니다.- 예를 들어,
product_id와 같이 표기합니다.
- 예를 들어,
-
명확하고 직관적인 이름: 객체의 의미를 잘 표현할 수 있는 이름을 사용합니다.
- 예를 들어,
user_info는 사용자 정보를 저장하는 테이블임을 쉽게 이해할 수 있습니다.
- 예를 들어,
-
약어와 접두사 사용 시 일관성 유지:
약어나접두사를 사용할 때는 프로젝트 전반에 걸쳐 일관성을 유지해야 합니다.- 예를 들어, 모든 테이블 이름 앞에
tbl_을 붙이기로 했다면, 이를 일관되게 사용합니다.
- 예를 들어, 모든 테이블 이름 앞에
-
단수형 사용 권장: 일반적으로 테이블 이름에는 단수형을 사용하는 것이 권장됩니다.
- 예를 들어,
user와 같은 이름을 사용하여 한 행이 한 사용자를 나타내도록 합니다.
- 예를 들어,
이러한 명명 규칙을 적용하여 작성하면 데이터베이스의 구조가 일관성 있게 유지되며, 코드 가독성과 유지보수성을 높일 수 있습니다.
2.3 RDBMS 주요 키워드 정리
RDBMS 주요 키워드
| 분류 | 용어 | 설명 |
|---|---|---|
| 데이터 요소 | 데이터 (Data) | 각 항목에 저장되는 값 |
| 데이터 요소 | 테이블 (Table) | 사전에 정의된 행과 열의 구조화 데이터 |
| 데이터 요소 | 필드 (Field, Attribute) | 열 (Column) |
| 데이터 요소 | 레코드 (Record, Tuple) | 한 행(Row)의 저장 정보 |
| 키 | 기본키 (Primary Key) | 각 테이블의 레코드 하나를 가리키는 고유한 값 |
| 키 | 외래키 (Foreign Key) | 다른 테이블의 기본키를 참조하기 위한 값 |
| 엔티티 | 엔티티 (Entities) | 고유 정보의 단위 각각의 테이블이라고 보면 됨 |
| 엔티티 | 필드 (Fields) | 각 엔티티에 해당하는 특성 엔티티의 컬럼으로 볼 수 있음 |
| 엔티티 | 레코드 (Records) | 테이블에 저장된 항목 엔티티의 행으로 볼 수 있음 |
Schema 기반 관계 종류
| 관계 종류 | 설명 |
|---|---|
| 1:1 관계 | 테이블 레코드 하나당 다른 테이블 하나와 연결. 일반적으로 테이블을 합치는 것이 보편적이므로 흔하지 않음 |
| 1:N 관계 | 테이블 레코드 하나가 여러 개의 레코드와 연결. 가장 흔한 관계이며, N쪽에 1의 고유 정보를 포함시켜 관리함 |
| N:N 관계 | 여러 레코드가 서로 다수의 레코드를 가지는 관계. 주로 조인 테이블을 만들어 1:N 혹은 N:1 형식으로 관리함 |
| Self-referencing | 테이블 내에서 자기 자신과 관계가 성립. 예: 추천인-유저 관계 |
사용자 입장에 따른 Schema 구분
| 스키마 종류 | 설명 |
|---|---|
| 외부 스키마 | 사용자 입장에서의 스키마 |
| 개념 스키마 | 설계자 입장에서의 스키마 |
| 내부 스키마 | 개발자 입장에서의 스키마 |
3. RDBMS Table
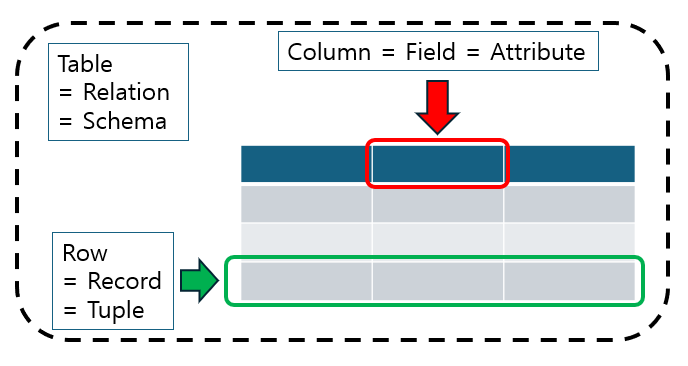
3.1 Table이란?
테이블(Table)은 관계형 데이터베이스(RDBMS)에서 데이터를 행(Row)과 열(Column)의 2차원 구조로 저장하는 데이터의 집합체입니다.
-
테이블은 데이터베이스의 가장 기본적인 저장 단위로, 특정 주제나 엔티티에 대한 정보를 저장하는 역할을 합니다.
- 예를 들어,
users테이블은 사용자 정보(이름, 이메일, 비밀번호 등)를 저장할 수 있으며,orders테이블은 주문 정보를 관리할 수 있습니다.
- 예를 들어,
-
열(Column): 테이블의 열은 각 필드 또는 속성을 의미하며, 테이블에 저장된 데이터의 특성을 정의합니다.
- 예를 들어,
users테이블의 열에는user_id,name,email등이 있을 수 있습니다.
- 예를 들어,
-
행(Row): 테이블의 행은 하나의 레코드(Record) 또는 튜플(Tuple)을 의미하며, 각 행은 테이블의 특정 열에 해당하는 데이터를 가지고 있습니다.
users테이블의 한 행은 특정 사용자의 정보를 나타냅니다.
테이블은 키(Key)를 통해 다른 테이블과 연결될 수 있으며, 이를 통해 관계형 데이터베이스가 구조화된 데이터를 효율적으로 관리할 수 있습니다. (SQL 파트에서 다세히 다룹니다)
3.2 Data 자료형 (MySQL/MariaDB)
MySQL과 MariaDB에서는 데이터를 효율적으로 저장하고 관리하기 위해 다양한 데이터 타입(Data Type)을 제공합니다.
- 각 열(Column)에 적합한 데이터 타입을 설정하여 저장 공간을 효율적으로 사용하고, 데이터의 무결성을 유지할 수 있습니다.
Oracle,SQL Server,PosetgreSQL등에서는 다루는 데이터 타입의 종류는 거의 비슷하지만, 세부적인 변수의 종류나 이름에 있어서 차이가 다소 있습니다.
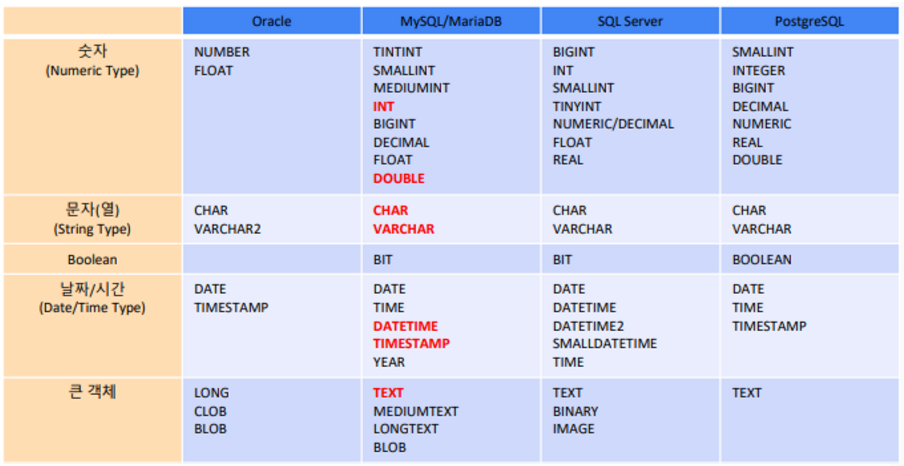
- 그래서 이번 시리즈에서는
MySQL/MariaDB에서의 Data 자료형을 정리해보고자 합니다.
- 그래서 이번 시리즈에서는
MySQL과 MariaDB의 Data 자료형
| 자료형 분류 | 자료형 | 설명 |
|---|---|---|
| 비트형 | BIT | 비트 값을 저장하며, 1에서 64비트까지 설정 가능 (예: BIT(1)은 1비트의 논리값) |
| 논리형 | BOOLEAN | 참(True) 또는 거짓(False)을 나타내는 논리형. 실제로는 TINYINT(1)로 저장 (1 = True, 0 = False) |
| 숫자형 | TINYINT | 1바이트 크기의 정수 (-128 ~ 127 범위) |
| SMALLINT | 2바이트 크기의 정수 (-32,768 ~ 32,767 범위) | |
| MEDIUMINT | 3바이트 크기의 정수 (-8,388,608 ~ 8,388,607 범위) | |
| INT | 4바이트 크기의 정수 (-2,147,483,648 ~ 2,147,483,647 범위) | |
| BIGINT | 8바이트 크기의 정수 | |
| FLOAT, DOUBLE | 실수형 데이터, 소수점을 포함한 값을 저장 | |
| DECIMAL | 고정 소수점 숫자 정확한 계산이 필요한 금융 데이터에 적합 | |
| 문자열형 | CHAR(n) | 고정 길이 문자열 (최대 255문자) |
| VARCHAR(n) | 가변 길이 문자열 (최대 65,535바이트) | |
| TEXT | 큰 문자열 데이터 저장 (최대 65,535바이트) | |
| MEDIUMTEXT | 매우 큰 텍스트 데이터 저장 (최대 16MB) | |
| LONGTEXT | 매우 큰 텍스트 데이터 저장 (최대 4GB) | |
| 날짜 및 시간형 | DATE | 날짜 저장 (YYYY-MM-DD 형식) |
| TIME | 시간 저장 (HH:MM:SS 형식) | |
| DATETIME | 날짜와 시간 저장 (YYYY-MM-DD HH:MM:SS 형식) | |
| TIMESTAMP | UNIX 타임스탬프 형식으로 날짜와 시간 저장 자동 업데이트 지원 | |
| YEAR | 연도 저장 (YYYY 형식, 1901~2155 범위) | |
| 기타 자료형 | ENUM | 선택 가능한 값 목록을 정의하여, 특정 값만 허용 |
| SET | 하나 이상의 값을 선택할 수 있는 목록을 정의하여 여러 값 허용 | |
| BLOB | 이진 데이터(Binary Large Object) 저장 이미지, 동영상 등 이진 데이터 저장 가능 |
각 자료형을 적절히 선택하여 테이블을 설계하면 저장 공간을 절약하고 데이터 무결성을 유지할 수 있습니다.
마무리
이번 포스팅에서는 DataBase의 기본적인 개념과 RDBMS(관계형 DBMS)에서의 Instance, Host, Table, Data 자료형, 등에 대해 다루어보았습니다.
- DataBase : 데이터를 효율적으로 저장하고 관리하기 위한 구조화된 시스템.
- DBMS : 데이터베이스를 체계적으로 관리하는 소프트웨어로, 데이터의 생성, 저장, 검색 등을 담당.
- RDBMS : 데이터를 테이블 형태로 관리하는 관계형 DBMS로, 데이터 간의 관계를 설정하여 정형화된 데이터를 관리.
- Instance : DBMS가 실행 중일 때 메모리에서 동작하는 데이터베이스 관리 프로세스.
- User(Host) : 데이터베이스에 접근할 수 있는 권한을 가진 계정.
명명 규칙 : 객체 이름에 일관된 규칙을 적용하여 가독성과 유지보수성을 높임. - Table : 데이터를 행과 열의 구조로 저장하는 기본 단위.
- Data 자료형 : 테이블의 각 열에 저장할 데이터의 유형을 정의하여 효율적이고 정확하게 데이터 관리.
다음 포스팅부터는 이러한 RDBMS를 다루기 위한 특수한 언어인 SQL(Structured Query Language)에 대해 다루어 보도록 하겠습니다.
