
시계열 데이터 분석에 필요한 개념들을 요약하고 정리하는 시리즈 - 4. 다변량 시계열 모델 (ARCH, VAR, VECM) 편
1. 변동성 모형 (ARCH, GARCH)
1-1. 변동성의 개념
- 변동성(volatility)란 시간에 따른 변수의 변동 정도를 의미하고, 대부분 표준편차나 분산으로 측정됩니다.
- 대부분의 시계열 데이터에서는 변동성의 군집현상(volatility clustering)이 발생하는데, 이러한 현상은 오차항의 분산이 일정하다는 회귀모형의 기본적인 가정을 만족시키지 못하게 됩니다.
- 즉, 외부 요인에 영향을 받는다는 의미이며, 이러한 영향으로 인해 시계열에서 분산이 일정해지지 않는 이분산성(Heteoskedasticity)이 나타나게 됩니다.
- 이때 조건부 확률을 이용한 조건부 분산을 통해 오차항의 분산과 독립변수가 일정한 관계를 가지도록 할 수 있습니다.
- 조건부 분산 : x값을 알고 있을 경우에 대한 조건부 확률분포 P(y|x)의 분산
- 조건부 분산은 예측의 불확실성을 의미한다고도 볼 수 있습니다.
1-2. 변동성 모형 (ARCH, GARCH)
- 이론적으로는 상당히 좋은 모델이지만, 실제로 적용하기에는 단점이 많아서 잘 쓰이진 않지만, 개념적으로는 일단 정리해보도록 하겠습니다.
ARCH (AutoRegressive Conditional Heteroskedasticity))
- ARCH 는 오차항의 분산의 현재값이 이전의 오차항의 제곱값들에 의존할 것이라는 접근에서 출발합니다.
- 바로 직전의 오차항의 제곱값에 의존 :
- 전체 모형은 조건부 평균과 분산에 대해 두개의 구별되는 모형을 포함합니다.
- ARCH(1)
- ARCH 모형은 다양한 문제점들을 가지고 있습니다.
- 과거 값의 제곱을 이용하므로 방향(+/-)에 따른 영향력을 반영하지 못합니다.
- ARCH의 차수 q를 결정하는데 있어 q값이 상당히 커질 수 있습니다.
- 추정해야하는 모수가 많아지는 경우에 모든 파라미터가 양(+)의 값을 가지지 못할 수 있어 이에 따른 모순이 발생할 수 있습니다.

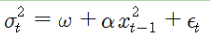
GARCH (Generalized AutoRegressive Conditional Heteroskedasticity)
- ARCH 모형과 달리, GARCH 모형은 변동성의 시계열 의존성(자기상관)을 표현하는 데 있어서 모수의 수를 줄일 수 있습니다.
- GARCH 모형은 조건부분산이 직전의 오차항의 제곱값과 함께 자체 시차값(lagged values)에 의존하도록 합니다.
- GARCH(1,1)
- GARCH(1, 1) = ARCH(∞) 모형이므로 추정해야 하는 모수의 수를 줄일 수 있다는 장점이 있습니다.
- GARCH가 ARCH의 단점을 극복했다고 하더라도, 조건부 오차항의 분포가 비정규성을 나타내는 것을 제대로 설명하지 못하는 등 다양한 한계점들이 존재합니다.
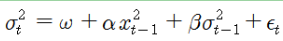
2. 벡터 회귀 모형 (VAR, VECM)
2-1. 벡터자기회귀 (Vector AutoRegressive Model, VAR)
- 실제 시계열 분석에서는 2개 이상의 시계열을 동시에 모형화하는 것이 여러모로 유리합니다.
- 대부분의 시계열 데이터들은 서로 독립적으로 움직이지 않고 시계열 데이터간의 일정한 상관관계를 보입니다.
- 벡터자기회귀(VAR) 모델에서는 AR(자기회귀)식을 벡터로 쌓음으로써 2개 이상의 시계열을 동시에 모형화 할 수 있습니다.
- 다만 단일 시계열의 AR과의 차이점은 자기 자신의 lag뿐만 아니라 다른 변수들의 lag도 포함하여 해석을 진행한다는 것입니다.
Python으로 간단한 VAR 모델 실습해보기
- statsmodels의 VAR 모듈을 통해 진행합니다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import statsmodels.api as sm
from statsmodels.tsa.api import VAR- 데이터 불러오기 (statsmodels에서 제공하는 macro 데이터셋)
mdata = sm.datasets.macrodata.load_pandas().data
mdata
- 데이터 전처리 (시간변수를 인덱스로 병합)
from statsmodels.tsa.base.datetools import dates_from_str
# 실수형 -> 정수형 -> 문자열로 변환
dates = mdata.loc[:,['year','quarter']].astype(int).astype(str)
# 연도Q분기로 변환
y_q = dates['year']+'Q'+dates['quarter']
# datetime형태의 자료가 담긴 리스트로 반환
year_quart = dates_from_str(y_q)
print(year_quart[:4])
print(len(year_quart))
'''
[datetime.datetime(1959, 3, 31, 0, 0),
datetime.datetime(1959, 6, 30, 0, 0),
datetime.datetime(1959, 9, 30, 0, 0),
datetime.datetime(1959, 12, 31, 0, 0)]
203
'''
# 필요한 column만 추출
cols = ['realgdp','realcons','realinv']
data = mdata[cols]
# 인덱스틑 datetime리스트로 설정
data.index = pd.DatetimeIndex(year_quart)
data.head()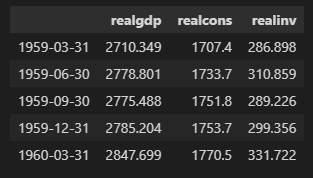
- 분포 시각화
data.plot()
plt.show()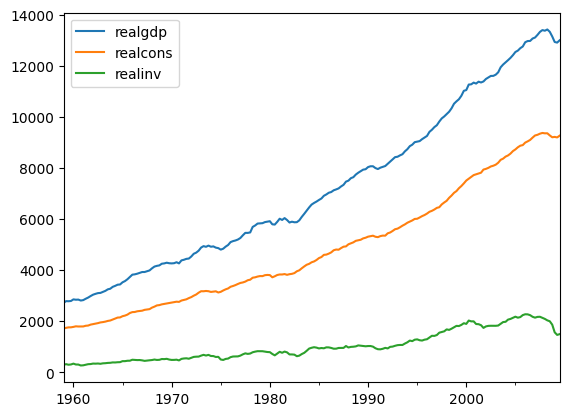
- 데이터 전처리 ( log변환 및 차분 )
diff_data = np.log(data).diff().dropna()
diff_data.plot()
plt.show()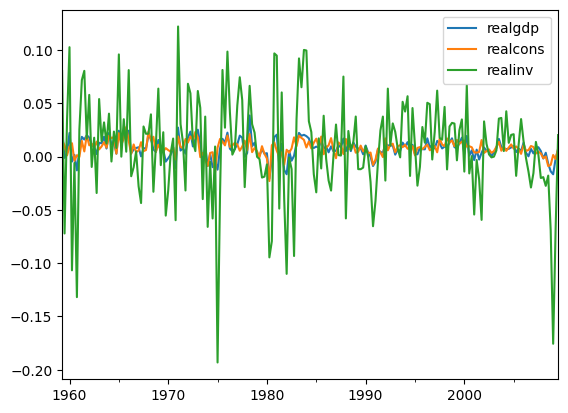
- 변수별 정상성 검정 (ADF검정)
from statsmodels.tsa.stattools import adfuller
# Stationarity Check
# (H0): non-stationary
# (H1): stationary
def adf(time_series):
result = adfuller(time_series.values)
print('ADF Statistic: {:.4f}'.format(result[0]))
print('p-value: {:.4f}'.format(result[1]))
for i in diff_data:
print('--Test statistic for %s' % i)
adf(diff_data[i])
print()
'''
--Test statistic for realgdp
ADF Statistic: -6.9729
p-value: 0.0000
--Test statistic for realcons
ADF Statistic: -4.9920
p-value: 0.0000
--Test statistic for realinv
ADF Statistic: -12.2190
p-value: 0.0000
'''- 전처리한 세 변수 모두 정상성을 만족함을 알 수 있음
- 학습, 테스트 데이터 분리 (90% : 10%)
X_train = diff_data[:int(len(diff_data)*0.9)]
X_test = diff_data[int(len(diff_data)*0.9):]
print(X_train.shape, X_test.shape)
'''
(181, 3) (21, 3)
'''- VAR 모델링 실시
model_var = VAR(endog=X_train)
var_fit = model_var.fit(maxlags=3, ic='aic')
var_fit.summary()
'''
Summary of Regression Results
==================================
Model: VAR
Method: OLS
Date: Thu, 30, Mar, 2023
Time: 15:31:16
--------------------------------------------------------------------
No. of Equations: 3.00000 BIC: -27.6469
Nobs: 180.000 HQIC: -27.7734
Log likelihood: 1753.15 FPE: 7.95563e-13
AIC: -27.8597 Det(Omega_mle): 7.44798e-13
--------------------------------------------------------------------
Results for equation realgdp
==============================================================================
coefficient std. error t-stat prob
------------------------------------------------------------------------------
const 0.004186 0.001007 4.158 0.000
L1.realgdp -0.333564 0.185854 -1.795 0.073
L1.realcons 0.703384 0.141602 4.967 0.000
L1.realinv 0.053481 0.027982 1.911 0.056
==============================================================================
Results for equation realcons
==============================================================================
coefficient std. error t-stat prob
------------------------------------------------------------------------------
const 0.006896 0.000852 8.095 0.000
L1.realgdp -0.073753 0.157241 -0.469 0.639
L1.realcons 0.248239 0.119802 2.072 0.038
L1.realinv 0.031390 0.023675 1.326 0.185
==============================================================================
Results for equation realinv
==============================================================================
coefficient std. error t-stat prob
------------------------------------------------------------------------------
const -0.012571 0.005163 -2.435 0.015
L1.realgdp -2.493790 0.953078 -2.617 0.009
L1.realcons 4.574692 0.726149 6.300 0.000
L1.realinv 0.300710 0.143497 2.096 0.036
==============================================================================
Correlation matrix of residuals
realgdp realcons realinv
realgdp 1.000000 0.607436 0.763364
realcons 0.607436 1.000000 0.142382
realinv 0.763364 0.142382 1.000000
'''- 예측(forecast) 실시
# lag order 값 산출 (적분차수)
var_lag_order = var_fit.k_ar
var_fit.forecast(X_train.values[-var_lag_order:], steps=len(X_test))
'''
array([[0.00788875, 0.00904605, 0.00720955],
[0.00830317, 0.00878588, 0.01130695],
[0.00820107, 0.00881935, 0.01031542],
[0.00820564, 0.00880406, 0.01042498],
[0.00819923, 0.00880337, 0.01037661],
[0.00819829, 0.00880215, 0.01037489],
[0.00819766, 0.00880187, 0.01037114],
[0.00819747, 0.00880173, 0.01037028],
[0.00819738, 0.00880168, 0.01036985],
[0.00819735, 0.00880166, 0.0103697 ],
[0.00819734, 0.00880165, 0.01036965],
[0.00819734, 0.00880165, 0.01036962],
[0.00819734, 0.00880165, 0.01036962],
[0.00819734, 0.00880165, 0.01036961],
[0.00819734, 0.00880165, 0.01036961],
[0.00819734, 0.00880165, 0.01036961],
[0.00819734, 0.00880165, 0.01036961],
[0.00819734, 0.00880165, 0.01036961],
[0.00819734, 0.00880165, 0.01036961],
[0.00819734, 0.00880165, 0.01036961],
[0.00819734, 0.00880165, 0.01036961]])
'''- 예측 결과 시각화
- 신뢰구간에 따른 상한선과 하한선도 확인 가능
var_fit.plot_forecast(steps=len(X_test))
plt.show()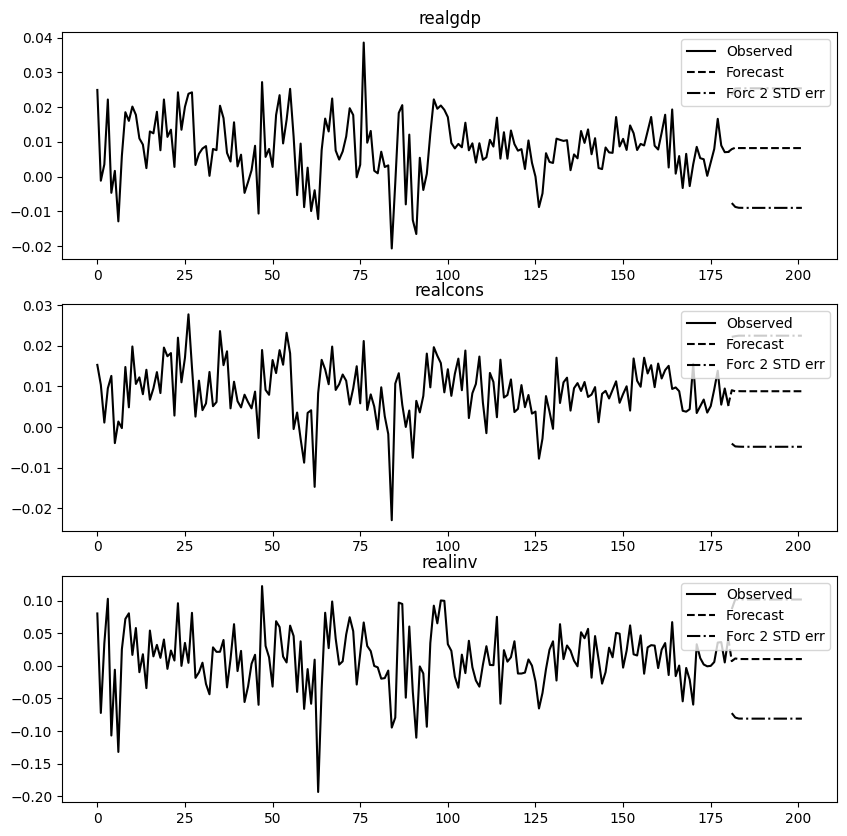
- 예측 결과 오차 계산 (MAE, MSE, RMSE)
# 예측 결과를 데이터프레임으로 만들기
pred_var = var_fit.forecast(X_train.values[-1:], steps=len(X_test))
pred_df = pd.DataFrame(pred_var, index=X_test.index, columns=X_test.columns + '_pred')
# 평가 (MAE, MSE, RMSE)
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error
#Calculate mean absolute error
mae = mean_absolute_error(X_test['realgdp'],pred_df['realgdp_pred'])
print('MAE: %f' % mae)
#Calculate mean squared error and root mean squared error
mse = mean_squared_error(X_test['realgdp'], pred_df['realgdp_pred'])
print('MSE: %f' % mse)
rmse = np.sqrt(mse)
print('RMSE: %f' % rmse)
'''
MAE: 0.005971
MSE: 0.000082
RMSE: 0.009054
'''2-2. 벡터오차수정모형 (Vector Error Correction Model, VECM)
- 공적분 관계의 존재 여부에 따라 VAR와 VECM을 선택하여 실시할 수 있는 모형입니다.
- 공적분(Cointegration): 두 비정상 시계열을 선형조합 했을 때 시계열의 적분 차수가 낮아지거나 정상상태가 되는 경우
- 적분차수: 정상성이 되기까지 차분해야 하는 횟수
- 두 개 이상의 시계열이 공적분 관계에 있으면 장기관계 또는 균형관계를 가진다는 의미합니다.
- VAR 모형은 각 시계열이 안정성 조건을 만족하지 않아도 사용할 수 있지만, 일반적으로 불안정성 시계열의 경우 차분을 하거나 변수간 장기적 관계에 대하여 정보를 상실할 수 있다는 단점이 있습니다.
- 따라서 VECM 모형에서는 변수간 공적분 관계에 있는 시계열은 차분을 거치지 않고 원 데이터를 써서 모형에 적합시킬 수 있다는 점에서 장점을 가집니다.
Python으로 간단한 VECM 모델 실습해보기
- statsmodels의 vecm 모듈을 이용합니다. (데이터는 VAR과 동일한 데이터를 이용합니다.)
from statsmodels.tsa.vector_ar import vecm- 공적분 테스트
## Statistical Test for Cointegration (VECM 공적분 테스트)
## 귀무가설 : 공적분 특성없다, 대립가설 : 공적분 특성 있다
vec_rank = vecm.select_coint_rank(X_train, det_order = 1, k_ar_diff = 1, signif=0.01)
print(vec_rank.summary())
'''
Johansen cointegration test using trace test statistic with 1% significance level
=====================================
r_0 r_1 test statistic critical value
-------------------------------------
0 3 208.6 41.08
1 3 105.7 23.15
2 3 37.84 6.635
-------------------------------------
'''- 통계값이 임계값보다 훨씬 크므로 귀무가설을 기각할 수 있고, 따라서 공적분 특성이 있다고 결론 지을 수 있습니다.
- VECM 모델링
vecm = vecm.VECM(endog = X_train, k_ar_diff = 9, coint_rank = 3, deterministic = 'ci')
vecm_fit = vecm.fit()- 10개의 지점에 대한 예측(Forcast) 실시
vecm_fit.predict(steps=10)
'''
array([[ 0.00855749, 0.00808964, 0.01745962],
[ 0.00637704, 0.00811118, 0.00024825],
[ 0.00666643, 0.00782071, 0.00703061],
[ 0.00586009, 0.00686629, 0.00285183],
[ 0.00603568, 0.00852688, -0.00404639],
[ 0.0102598 , 0.0111991 , 0.01528229],
[ 0.01035375, 0.01132725, 0.02284169],
[ 0.01152781, 0.00997501, 0.02785296],
[ 0.00895585, 0.00876293, 0.01774089],
[ 0.00853485, 0.00855157, 0.01511429]])
'''- 예측 결과 시각화
vecm_fit.plot_forecast(steps=10, n_last_obs=50);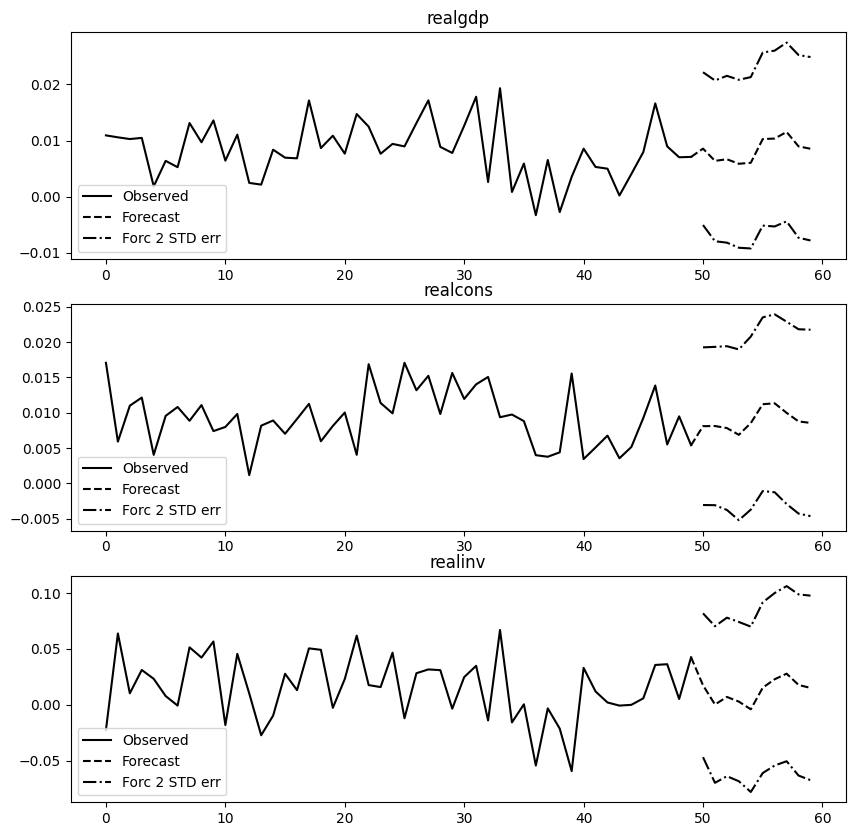
마무리
- 이번 글에서는 다변량 시계열 모델인 ARCH, GARCH, VAR, VECM에 대해서 정리해보고 간단하게 실습을 진행해보았습니다.
- 금융 분야에서 주로 많이 쓰이기는 하지만, 최근에는 이후의 글에서 정리할 딥러닝 기법을 더 많이 쓰기 때문에 이번 글에서는 최대한 간단하게 살펴보았습니다.
Keyword 정리
- 변동성 모형 (ARCH, GARCH)
- 1-1. 변동성의 개념
- 변동성(volatility)
- 이분산성(Heteoskedasticity)
- 조건부 분산
- 1-2. 변동성 모형 (ARCH, GARCH)
- ARCH (AutoRegressive Conditional Heteroskedasticity))
- GARCH (Generalized AutoRegressive Conditional Heteroskedasticity)
- 벡터 회귀 모형 (VAR, VECM)
- 2-1. 벡터자기회귀 (Vector AutoRegressive Model, VAR)
- AR(자기회귀)식을 벡터로 쌓음
- 2-2. 벡터오차수정모형 (Vector Error Correction Model, VECM)
- 공적분(Cointegration)
- 적분차수
- 다음 글에서는 딥러닝을 활용한 시계열 분석에 대해서 정리해볼 예정입니다.
- 딥러닝 기초 이론도 따로 정리해야해서 업데이트에 다소 시간이 걸릴 것으로 예상됩니다 ㅠ

일 때문에 포스팅은 잠시 쉬어요 ㅠ // Now. 수학 강사 (광교) // Prev. Machine Learning (AI) Engineer & BackEnd Engineer