문제 풀이 핵심
- int -> hex 변환
- MD5 hash의 구조를 아는가?
- rand의 함정
- xor의 함정 (상수라도 다른 곳에서 연산이 되지 않는지 무조건 확인할 것)
- main
__int64 __fastcall main(int a1, char **a2, char **a3)
{
int v4; // ebx
int v5; // ebx
unsigned int *v6; // rbx
int v7; // [rsp+1Ch] [rbp-54h] BYREF
int i; // [rsp+20h] [rbp-50h]
int j; // [rsp+24h] [rbp-4Ch]
int k; // [rsp+28h] [rbp-48h]
int m; // [rsp+2Ch] [rbp-44h]
int s_len; // [rsp+30h] [rbp-40h]
unsigned int seed; // [rsp+34h] [rbp-3Ch]
char *s; // [rsp+38h] [rbp-38h]
__int64 md5_result[6]; // [rsp+40h] [rbp-30h] BYREF
md5_result[3] = __readfsqword(0x28u);
if ( a1 == 2 )
{
s = strdup(a2[1]);
s_len = strlen(s);
puts("Welcome to registration center");
seed = time(0LL);
srand(seed);
v4 = rand();
v7 = v4 + rand();
md5_result[0] = 0LL;
md5_result[1] = 0LL;
md5_hash(&v7, 4uLL, (__int64)md5_result);
for ( i = 0; i < s_len; ++i )
{
s[i] ^= *((_BYTE *)md5_result + ((4 * (_BYTE)i) & 0xF));
s[i] ^= *((_BYTE *)md5_result + ((4 * (_BYTE)i + 1) & 0xF));
s[i] ^= *((_BYTE *)md5_result + ((4 * (_BYTE)i + 2) & 0xF));
s[i] ^= *((_BYTE *)md5_result + ((4 * (_BYTE)i + 3) & 0xF));
}
for ( j = 0; j < s_len / 2; ++j )
*(_WORD *)&s[2 * j] ^= word_4048;
seed = time(0LL);
srand(seed);
v5 = rand();
v7 = v5 + rand();
memset(md5_result, 0, 0x10uLL);
md5_hash(&v7, 4uLL, (__int64)md5_result);
for ( k = 0; k < s_len; ++k )
{
s[k] ^= *((_BYTE *)md5_result + ((4 * (_BYTE)k) & 0xF));
s[k] ^= *((_BYTE *)md5_result + ((4 * (_BYTE)k + 1) & 0xF));
s[k] ^= *((_BYTE *)md5_result + ((4 * (_BYTE)k + 2) & 0xF));
s[k] ^= *((_BYTE *)md5_result + ((4 * (_BYTE)k + 3) & 0xF));
}
for ( m = 0; m < s_len / 4; ++m )
{
v6 = (unsigned int *)&s[4 * m];
*v6 = bit_reverse(*v6);
}
if ( !memcmp(s, &unk_4020, 0x29uLL) )
puts("Registration done !");
else
puts("Registration failed..");
return 0LL;
}
else
{
printf("%s [registration code]\n", *a2);
return 1LL;
}
}md5_hash라는 걸 알아내는게 핵심이었다.
- md5_hash
unsigned __int64 __fastcall md5_hash(const void *a1, size_t a2, __int64 a3)
{
unsigned int v5; // [rsp+28h] [rbp-98h]
unsigned int v6; // [rsp+2Ch] [rbp-94h]
unsigned int v7; // [rsp+30h] [rbp-90h]
unsigned int v8; // [rsp+34h] [rbp-8Ch]
unsigned int v9; // [rsp+38h] [rbp-88h]
unsigned int v10; // [rsp+3Ch] [rbp-84h]
unsigned int v11; // [rsp+40h] [rbp-80h]
unsigned int v12; // [rsp+44h] [rbp-7Ch]
unsigned int m; // [rsp+48h] [rbp-78h]
unsigned int n; // [rsp+48h] [rbp-78h]
int v15; // [rsp+4Ch] [rbp-74h]
int v16; // [rsp+50h] [rbp-70h]
unsigned int v17; // [rsp+54h] [rbp-6Ch]
size_t i; // [rsp+58h] [rbp-68h]
size_t j; // [rsp+60h] [rbp-60h]
size_t k; // [rsp+60h] [rbp-60h]
char *dest; // [rsp+68h] [rbp-58h]
int v22[18]; // [rsp+70h] [rbp-50h]
unsigned __int64 v23; // [rsp+B8h] [rbp-8h]
v23 = __readfsqword(0x28u);
v5 = 0x67452301;
v6 = 0xEFCDAB89;
v7 = 0x98BADCFE;
v8 = 0x10325476;
for ( i = a2 + 1; (i & 0x3F) != 0x38; ++i )
;
dest = (char *)malloc(i + 8);
memcpy(dest, a1, a2);
dest[a2] = 0x80;
for ( j = a2 + 1; j < i; ++j )
dest[j] = 0;
separate(8 * a2, (__int64)&dest[i]);
separate(a2 >> 29, (__int64)&dest[i + 4]);
for ( k = 0LL; k < i; k += 64LL )
{
for ( m = 0; m <= 0xF; ++m )
v22[m] = sub_135C(&dest[4 * m + k]);
v9 = v5;
v10 = v6;
v11 = v7;
v12 = v8;
for ( n = 0; n <= 0x3F; ++n )
{
if ( n > 0xF )
{
if ( n > 0x1F )
{
if ( n > 0x2F )
{
v15 = v11 ^ (v10 | ~v12);
v16 = (7 * (_BYTE)n) & 0xF;
}
else
{
v15 = v12 ^ v11 ^ v10;
v16 = (3 * (_BYTE)n + 5) & 0xF;
}
}
else
{
v15 = v10 & v12 | v11 & ~v12;
v16 = (5 * (_BYTE)n + 1) & 0xF;
}
}
else
{
v15 = v11 & v10 | v12 & ~v10;
v16 = n;
}
v17 = v12;
v12 = v11;
v11 = v10;
v10 += __ROL4__(v9 + v15 + dword_2020[n] + v22[v16], dword_2120[n]);
v9 = v17;
}
v5 += v9;
v6 += v10;
v7 += v11;
v8 += v12;
}
free(dest);
separate(v5, a3);
separate(v6, a3 + 4);
separate(v7, a3 + 8);
separate(v8, a3 + 12);
return __readfsqword(0x28u) ^ v23;
}처음에 v5, v6 등의 변수들은 int 형으로 저장되어 있다. 이를 hex로 변경 시, 어디서 많이 본 값들이 나오는 것을 알 수 있다.
지난번에 hash-browns 문제 해결할 때 본 초기값 세팅이다.
- main 함수 정리
md5(rand() + rand())와 입력값 xor 연산
한 번 더 반복 후, bit reverse
마지막에 unk_4020과 비교
- time 조건
실행을 해보니 아직 시간이 안 됐다며 기다리라는 문구가 나온다.
기다리기 싫으니 패치해주자
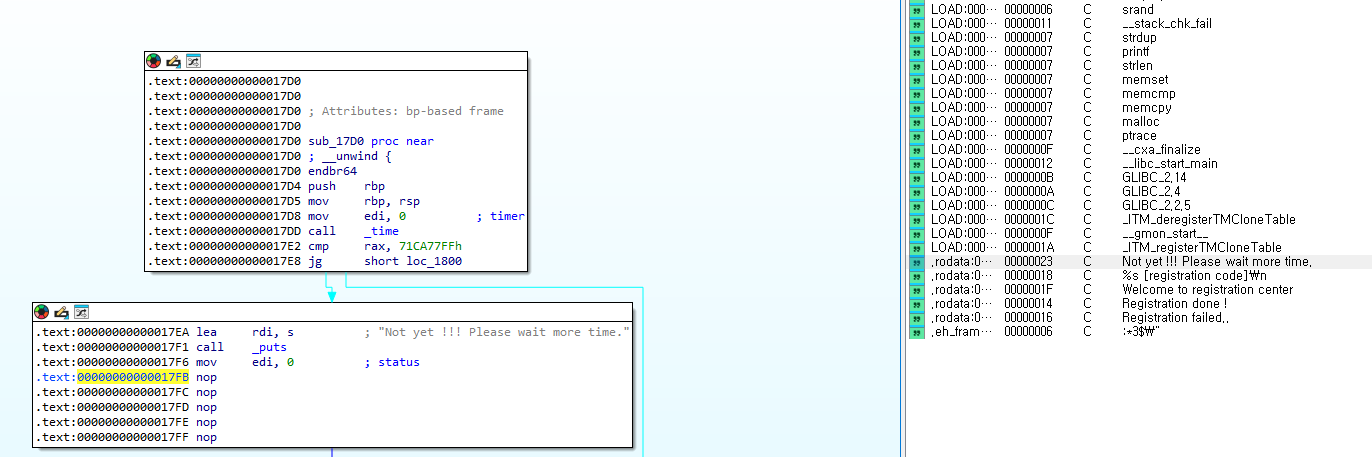
exit 부분을 nop으로 패치한다.

패치 후 재실행하면 기다리지 않아도 되는 걸 확인할 수 있다.
- python 코드를 짜도 제대로 안 돼서 코드를 계속 보니까 이상한게 껴있다.
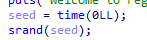
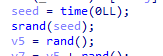
이거 왜 두 번 나오지
그래서 찾아보니까 time(0)의 기준은 초. 이 코드가 실행되는 동안 1초가 지날까? 아니다.
한 마디로
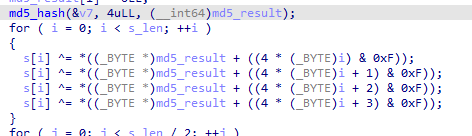
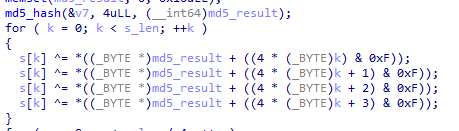
이 둘은 그냥 쓸모가 없다. xor은 두 번 연산하면 없어지니까. (이거 구현하느라 머리 싸맸는데...)
남은 건

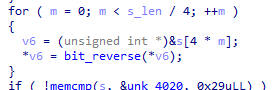
이렇게 두 개
그리고 솔직히 저거 bit_reverse 맞는지도 모르겠다 (점점 gpt에 대한 불신이 쌓여간다)
그래서 직접 python으로 교체했다.
def rol(n, cnt):
return (n << cnt) | (n >> (32-cnt))
calc = (num << 1) & 0xAAAAAAAA | (num >> 1) & 0x55555555
calc1 = (calc << 2) & 0xCCCCCCCC | (calc >> 2) & 0x33333333
calc2 = (calc1 << 4) & 0xF0F0F0F0 | (calc1 >> 4) & 0xF0F0F0F
calc3 = (calc2 << 8) & 0xFF00FF00 | (calc2 >> 8) & 0xFF00FF
result = rol(calc3, 16)num = 0x12345678 = 10 0100 0110 1000 1010 1100 1111 000
result = 1111 0011 0101 0001 0110 0010 01 000
4byte(32bit)의 값을 bit 기준으로 역으로 만든다. (gpt가 맞긴 하네... 그래도 다음부터는 코드를 직접 분석하도록 하자)
bit reverse라서 굳이 역연산 안 만들어도 된다. (한 번 더 적용하면 원상복구)
- word_4048과의 xor이 왜 필요가 없는가
-> 이거 이해하는게 진짜 힘들었다.
아무리 해도 답이 안 나오길래 (애초에 아스키코드 문자로 변환이 안 됨)
도대체 뭐가 문제일까하고 검색해봤다.
그랬더니 bit_reverse까지만 하고 word_4048 xor은 역연산을 안 해줬다.
gpt한테 물어보니 xor이 깨져서 그렇다고 한다. 이게 도대체 무슨 말일까? reverse를 다시 reverse하면 역연산이 된 형태로 돌아가는거 아닌가? (정적분석도 ptrace 때문에 막혀서 레지스터 확인도 안 된다ㅠ)
...진짜 허무하네 이걸 어케 찾어...ㅋㅋㅋㅋㅋ
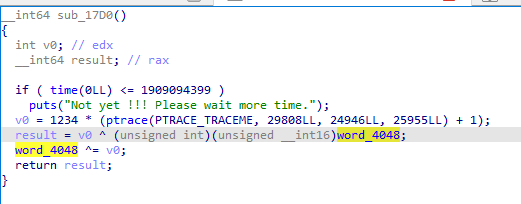
여기서 word_4048이 먼저 연산이 된다.
(gpt는 정말 정확한 정보를 주지 않는 한 오히려 역효과가 난다는 것을 깨달았다.)
ptrace는 문제가 없으면 0을 반환한다. (뒤에 +1있어서 연산할 때는 1이 된다)
그럼 v0는 1234, word_4048은 1234이랑 xor하면 0이 된다.
즉 우리가 main 함수에서 보는 word_4048은 0이었다...
그렇기에 역연산이 필요없다.
- exploit.py
def rol(n, cnt):
return ((n << cnt) | (n >> (32-cnt))) & 0xffffffff
def reverse(num):
calc = ((2 * num) & 0xAAAAAAAA | (num >> 1) & 0x55555555)
calc1 = ((calc << 2) & 0xCCCCCCCC | (calc >> 2) & 0x33333333)
calc2 = ((calc1 << 4) & 0xF0F0F0F0 | (calc1 >> 4) & 0xF0F0F0F)
calc3 = (calc2 << 8) & 0xFF00FF00 | (calc2 >> 8) & 0xFF00FF
result = rol(calc3, 16)
return result
n = [0x660C4C86, 0xA62C1C9C, 0x1C661C2C, 0x9C6CA6CC, 0xA66C6CAC, 0xA6A6864C, 0x2C46EC8C, 0xEC468C9C, 0x4CECC666, 0x4C46864C]
ans = b''
for i in range(10):
n[i] = reverse(n[i])
ans += n[i].to_bytes(4,'big')
print(ans)여기서 big으로 연산한 이유는 메모리에 저장된 순서 그대로 n에 저장했기 때문이다.
little로 연산하기를 원했으면 66 0C 4C 86 (메모리 저장) -> dword 0x864C0C66으로 변경해줘야 한다.
하지만 귀찮기 때문에 big로 간주하고 해결해주면 된다.
역시...4단계가 되니까 어렵구만
