Retrieval-Augmented Generation (RAG)
Retrieval는 골든리트리버(사냥개)에서 나온 단어이다. 사냥을 할 때 끝까지 추적해서 잡아오는게 리트리버의 역할이었고, Retrieval는 검색(Search)보다는 수색에 가까운 느낌이다. '수색해온 정보를 증강시켜서 결과를 만든다'로 RAG란 단어를 사용한다.
LLMS의 한계
- 오래된 정보 - GPT3.5의 경우 마지막 업데이트가 21년 1월이다.
- 내부 정보 접근 불가 - 자기 정보에 대해서만 대답이 가능하다. 실시간 정보나 내부 정보는 알지 못한다.
이 한계를 극복하기 위해 도메인 지식 통합을 시도하고 있다.
-
프롬프트 엔지니어링: 상황에 맞는 학습 -
파인튜닝: 새로운 기술 배우기(영구적으로)- 언어 모델 자체를 파인튜닝 하는건데, 예를 들어 제주도 방언 데이터를 모아서 튜닝하면 '폭싹 속았수다' 이런 말을 하게된다. 복잡한 용어에 대한 대답은 파인튜닝을 활용할 수 있다.
- 파인튜닝을 하면 파인튜닝 된 new LLM이 나오게 된다.
- 단점 1. 비용(GPU)과 시간이 많이 든다.
- 단점 2. 한 번 튜닝하면 그 상태로 또 다시 내용이 고정 된다.
계속 바뀌는 정보들은 파인튜닝으로 해결할 수 없다.
-
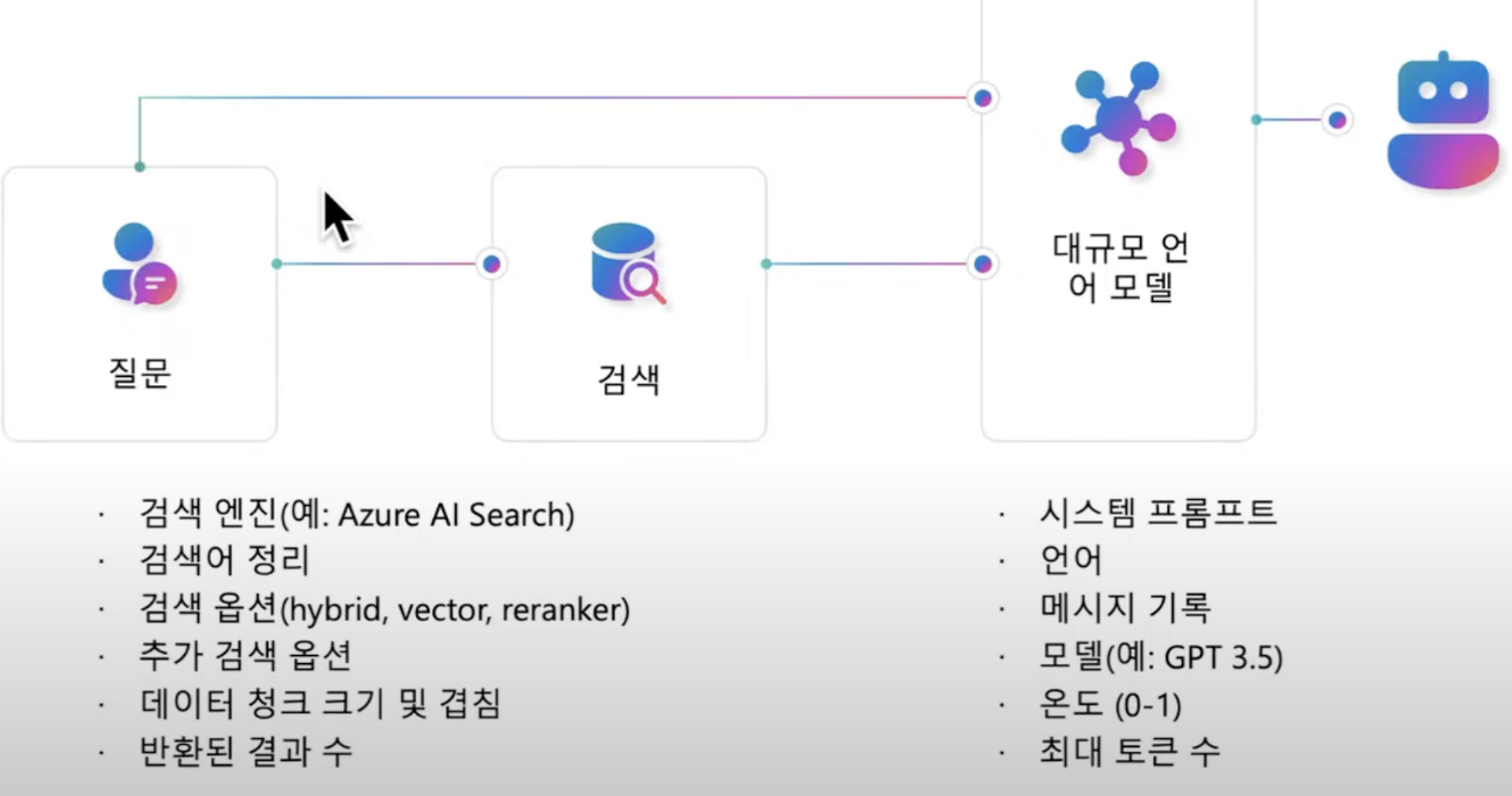
RAG: 새로운 사실 습득(임시로)- 사용자 질문 -> 검색 -> 검색 결과를 LLM에 전달 -> LLM이 답변을 만듦
- RAG를 위해 Azure AI Search만 사용해야 하는건 아니다. PostgreSQL도 이용할 수 있다.
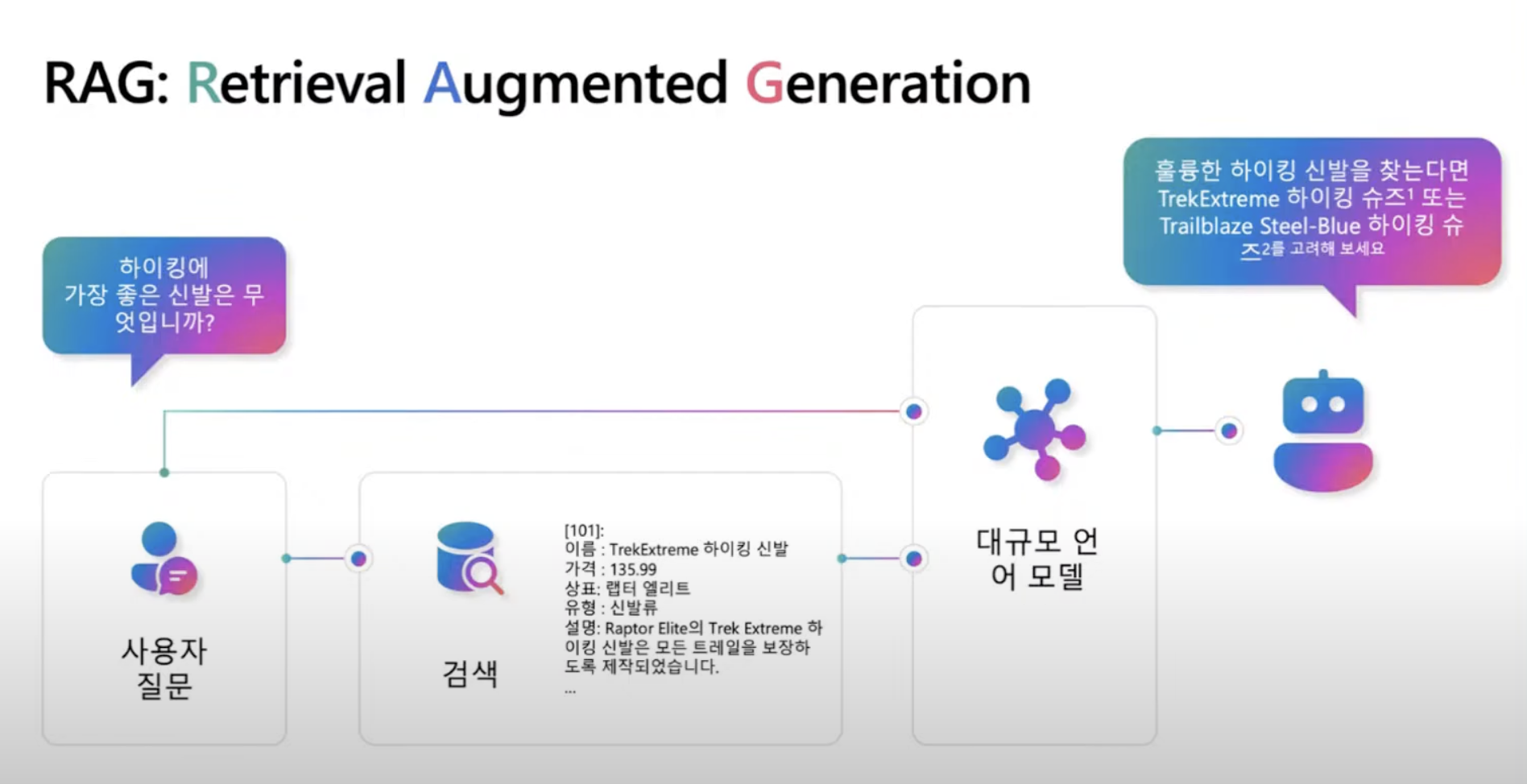
고급 RAG
사람들의 질문이 다르면 결과도 중구난방이 되는데 LLM을 거치고 검색하면 정확도가 올라간다.
- 사용자 질문 -> LLM이 중요한 키워드를 뽑아냄 -> 키워드로 검색 -> 검색 결과를 가지고 LLM이 답을 만듦
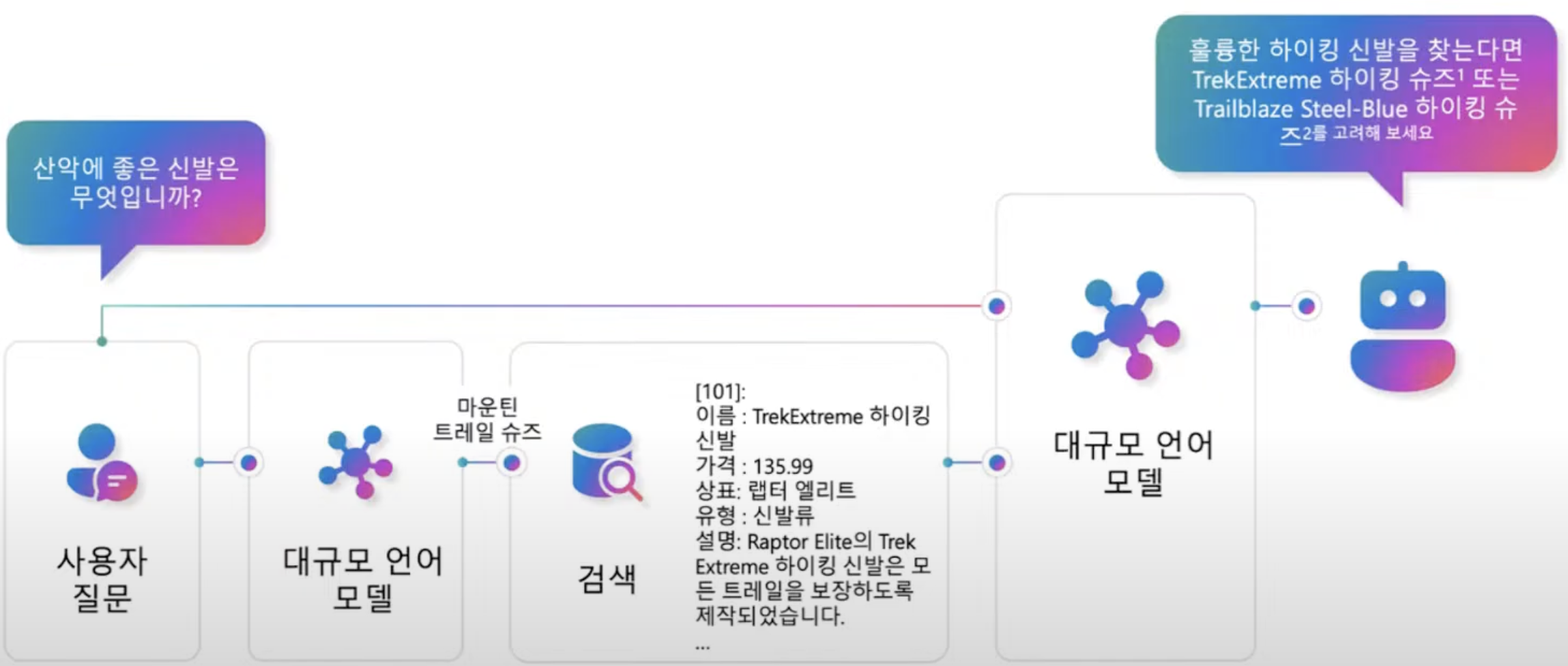
문서에 대한 RAG
JSON, PDF같은 비정형 데이터를 다룰 수 있는 솔루션이 필요하다.
- 사용자 질문 -> 비정형 데이터 검색 -> LLM 답변 (비효율적)
현실적으로 질문하는 순간 수많은 PDF를 뒤지는건 불가능하다. 평상시에 PDF를 미리 스캔해서 색인해둔 Index가 필요하다. 질문하면 Index에서 답을 가져와서 답변하는 솔루션이 필요하다.
- [사전 준비] 비정형 데이터 -> 청킹 -> 임베딩 -> Index 색인화
- [실시간 처리] 사용자 질문 -> Index 검색 -> 관련 문서 추출 -> LLM 답변 (효율적)
JSON, PDF 같은 데이터의 Index를 구현하는게 Azure AI Search의 역할이다.
RAG 검색이란?
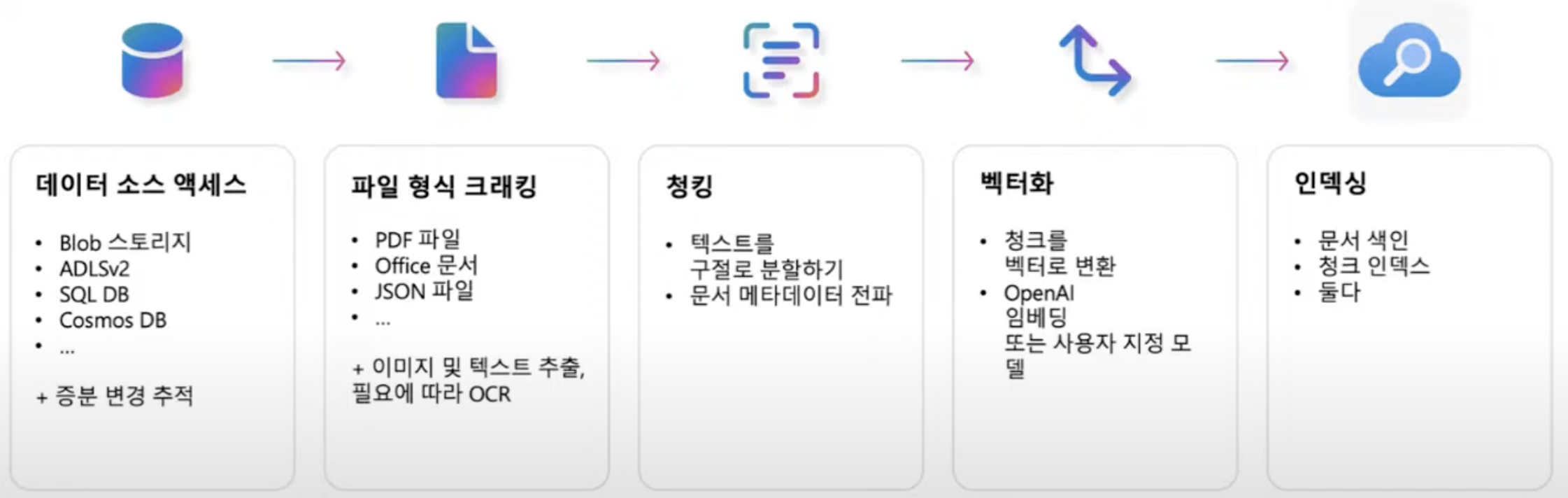
RAG 검색은 크게 2개로 나눠서 접근한다.
- 데이터베이스 행 (구조화된 데이터): 대상 열을 벡터화하고 검색하는 방법이 필요
- 문서(비정형 데이터): PDF, docx, pptx, md, html, 이미지 등.. 수집 프로세스가 필요한 경우 추출, 분할, 벡터화, 문서 청크를 저장
고품질 RAG의 구성 요소
정교한 LLM- 지침 준수
- 함수 호출 지원
잘 준비된 데이터- 적당한 크기의 텍스트 :: 만개의 PDF가 있으면 적당한 청크로 나눠진 것
- 의미 있는 벡터
강력한 검색 기능- 벡터 검색
- 하이브리드 검색
- 시맨틱 순위 재지정
- 필터링
벡터와 벡터검색
벡터 임베딩
임베딩이란 입력을 부동 소수점 숫자 목록으로 인코딩하는걸 말한다.
- '개' -> [0.017198, -0.007493, -0.057982, ... ]
- 벡터는 언어 모델이 정교화 될수록 길이(차원)가 길어진다.
- 차원이 높은 임베딩을 하면 정보가 상세하고 정확하게, 성실하게 분배된다.
| 모델 | 인코딩합니다 | MTEB 평균 | 벡터 길이 |
|---|---|---|---|
| 워드 2vc (LLM의 증조할아버지) | 가사 | 300 | |
| 스버트 (문장 트랜스 포머) | 텍스트(최대 ~400단어) | 768 | |
| OpenAI 텍스트 임베딩-ADA-002 | 텍스트(최대 8131개 토큰) | 61.0% | 1536 |
| OpenAI 텍스트 임베딩-3-스몰 | 텍스트(최대 8191개 토큰) | 62.3% | 512, 1536 |
| OpenAI 텍스트 임베딩-3-라지 | 텍스트(최대 8191개 토큰) | 64.6% | 256, 1024, 3072 |
| Azure 컴퓨터 비전 | 이미지 또는 텍스트 | 1024 |
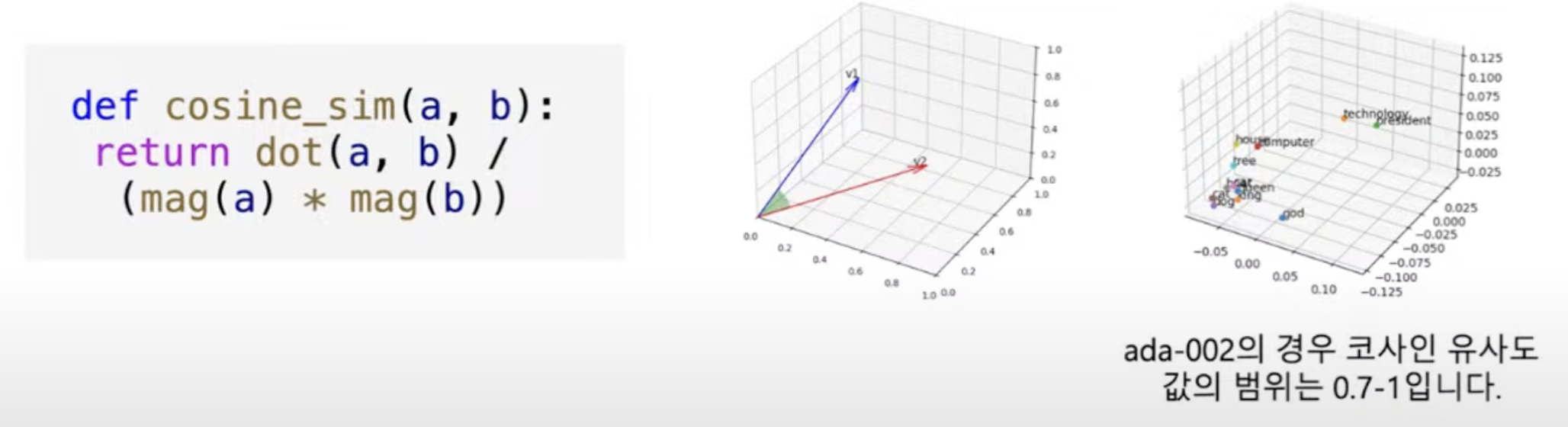
벡터 유사성
입력 간의 유사성을 계산할 수 있도록 임베딩을 계산한다. 가장 일반적인 거리 측정은 코사인 유사성이다.
각각의 좌표계 사이의 거리가 근접할수록, 방향이 일치할수록 유사하다고 본다.
벡터 검색
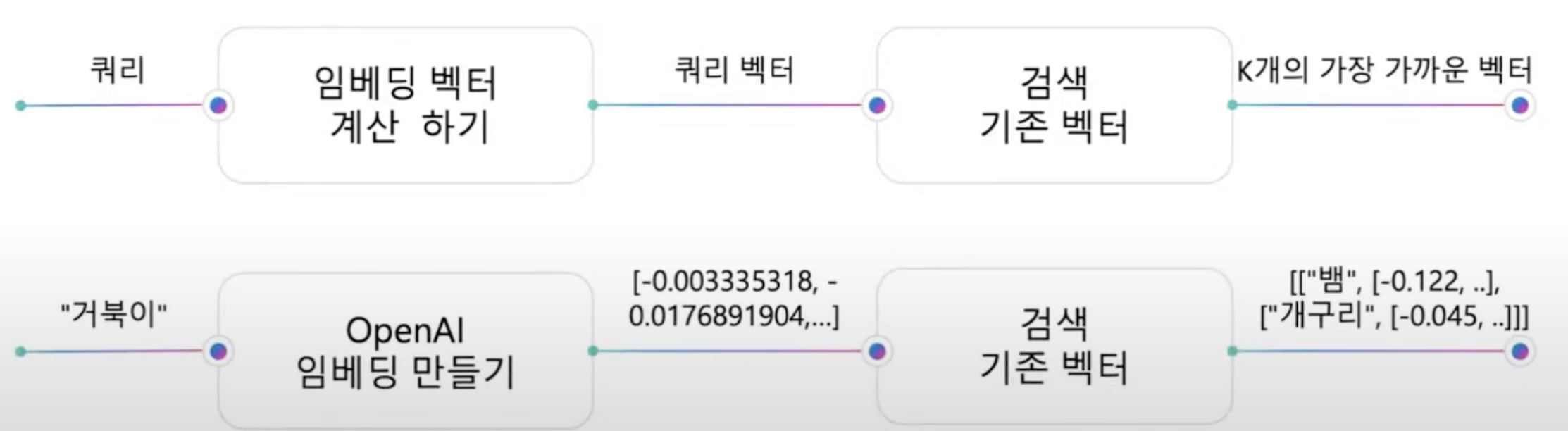
- 쿼리에 대한 임베딩 벡터를 계산한다.
- 쿼리 벡터에 대해 가장 가까운 K개의 벡터 찾기 - 철저하게 또는 근사치를 사용하여 검색
Azure의 벡터 데이터베이스
벡터 데이터를 다루고 저장할때 전부 코딩으로 처리하면 어디에서 뭐가 터질지 모르고, 신뢰도 문제나 업무 부하 상태의 대처등을 고려해야하기에 Azure에서 제공하는 기능을 사용하면 좋다.
- Azure 데이터베이스의 벡터
- 데이터를 현재 위치에 유지: 기본 벡터 검색 기능
- 내장:
- Azure Cosmos DB MongoDB vCore
- Azure PostgreSQL 서비스
- Microsoft Fabric의 Eventhouse
- Azure SQL 서버(예정)
- Azure AI Search
- 최고의 관련성: 즉시 사용 가능한 최고 품질의 결과
- Azure 데이터 원본의 데이터 자동 인덱싱:
- SQL DB
- Cosmos DB
- Blob Storage
- ADLSv2 등
- Azure AI Search는 벡터 검색 기능을 포함한 통합 검색 서비스로, 내부의 Index가 실질적인 벡터 데이터베이스 기능을 담당한다.
AI Search를 통한 최첨단 검색
Azure AI Search 는 포괄적인 검색 솔루션으로 엔터프라이즈급이고, Semantic Kernel, LangChain, LlamaIndex, Azure OpenAI Service, Azure AI Foundry 등 오픈소스와 연결해서 사용하기 좋다.
벡터 검색 전략
우리가 사용하는 데이터나 컨텐츠에 따라 결과가 달라질 수 있어서 구축 후 테스트를 통해 잘 맞는 알고리즘을 찾아서 사용해야한다.
ANN 검색- ANN = 근사치 최근접 이웃 :: 일반적으로 사용
- 대규모 빠른 벡터 검색
- 성능 재현율이 뛰어난 그래프 방법인 HNSW를 사용
- 인덱스 매개 변수에 대한 세밀한 제어
철저한 KNN 검색- KNN = k개의 최근접 이웃 :: 클러스터링 같은 알고리즘에서 사용
- 쿼리별 또는 스키마에 기본 제공
- 회수 기준선을 만드는 데 유용
- 선맥도가 높은 필터를 사용하는 시나리오. 예) 밀집된 다중 테넌트 앱
풍부한 벡터 검색 쿼리 기능
-
필터링된 벡터 검색- 날짜 범위, 범주, 지리적 거리, 액세스 제어 그룹 등으로 범위를 지정한다.
- 풍부한 필터 표현식
- 사전/사후 필터링
- 사전 필터: 선택적 필터에 적합, 리콜 중단 없음
- 포스트 필터: 낮은 선택성 필터에 더 좋지만 빈 결과 관찰 필요
https://learn.microsoft.com/ko-kr/azure/search/vector-search-filtersr = search_client.search( None, top=5, vector_queries=[VectorizedQuery( vector=query_vector, k_nearest_neighbors=5, fields="embedding")], vector_filter_mode=VectorFilterMode.PRE_FILTER, filter="tag eq 'perks' and created gt 2023-11-15T00:00:00Z" )
-
다중 벡터 시나리오- 문서당 여러 벡터 필드
- 다중 벡터 쿼리
- 필요에 따라 믹스 앤 매치 가능
r = search_client.search( None, top=5, vector_queries=[ vectorizedQuery( vector=query1, fields="body_vector", k_nearest_neighbors=5), vectorizedQuery( vector=query2, fields="title_vector", k_nearest_neighbors=5) ])
Q: 채팅을 기반으로 이미지를 검색하는것도 가능한가요?
A: '사진속에 개가 있는 이미지를 찾아줘' 같은 이미지 검색은 가능하다. 비전쪽을 다룰 수 있는 모델을 사용해야 한다. 그런데 LLM 자체에서 검색하는건 비용 문제가 있다. 이미지 사이즈가 커지면 토큰 비용이 훅훅 늘어난다.(이미지 크기가 2배 증가 -> 토큰 수 약 4배 증가) Azure AI Search에서 컴퓨터 비전 API에 IMG를 넣으면 이미지에 필요한 태그와 한 줄 짜리 설명을 뽑아주는게 가능하다. 비용적인 측면에서 이걸 사용하여 검색하는게 낫다.
최적의 관련성: 하이브리드 검색 + 시맨틱 랭커
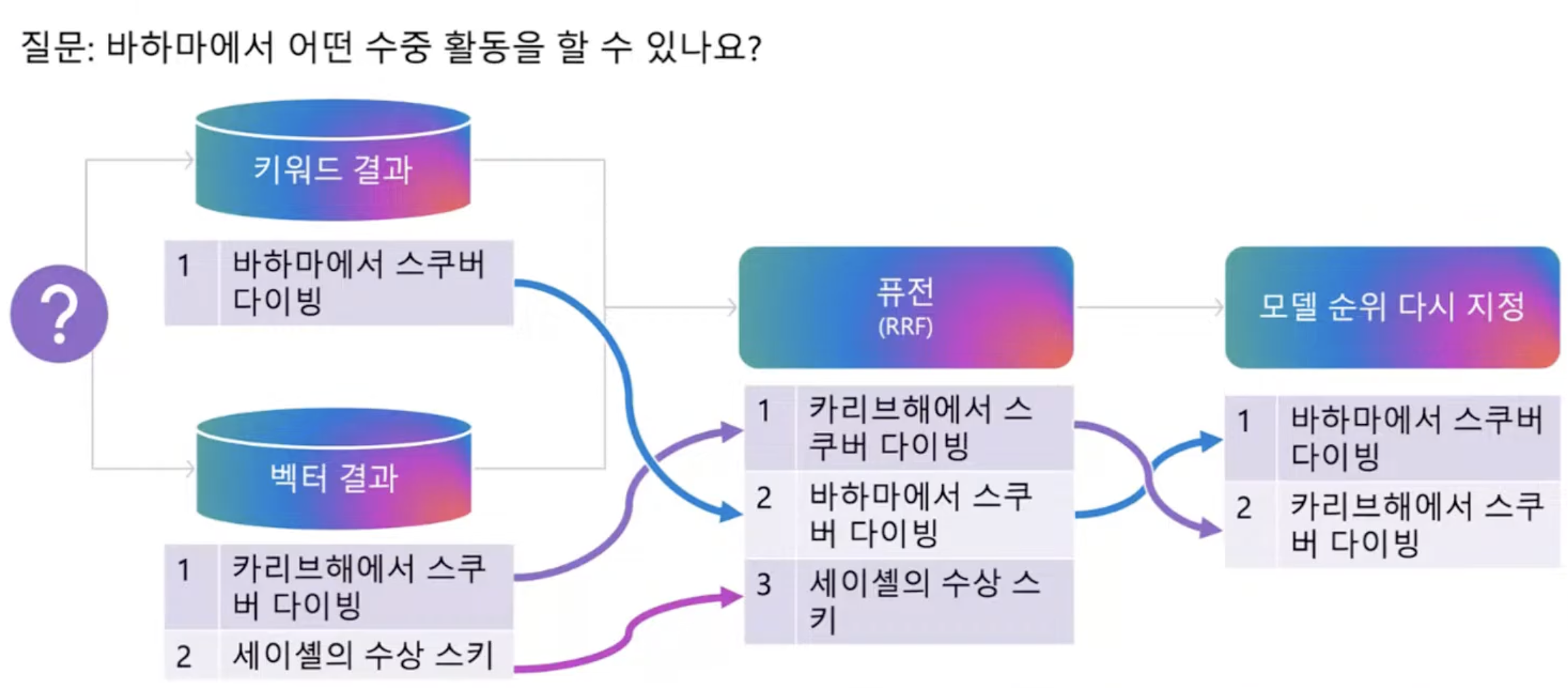
하이브리드 검색 = 키워드 결과 + 벡터 결과 => L1 단계는 회상율을 향상시킨다.
시맨틱 랭커 = 의미적으로 다시 한 번 랭킹을 지정 => L2 단계에서 랭킹 정밀도가 향상된다.
- 회상율: 자료에서 필요한 정보를 뽑아내는 것을 말한다.
- 퓨전(Reciprocal Rank Fusion): 하이브리드 검색에서 여러 검색 결과를 통합하는 알고리즘을 말한다. 벡터 검색과 키워드 검색의 결과를 효과적으로 결합하는데 사용한다.
데이터 수집 접근 방식
문서를 분할해야 하는 이유는 무엇입니까?
1. LLM은 컨텍스트 윈도우가 제한되어 있다. (4k-128k)
즉, LLM이 사용할 수 있는 데이터의 양이 한정적이다. 그렇기 때문에 LLM에 맞춰서 필요한 만큼 문서를 잘 잘라서 사용해야 한다. 자르는 작업을 청킹이라 하는데, 청킹의 사이즈도 정해야 한다.
2. LLM이 너무 많은 정보를 수신하면 관련 없는 세부 사항으로 인해 쉽게 주의가 산만해질 수 있다.
문서 청크의 최적 크기
- 토큰은 LLM의 입력/출력에 대한 측정 단위이다. 영어의 경우 ~1 토큰/단어, 다른 언어의 경우 더 높은 비율이다.
- 청크 분할 알고리즘도 테이블을 고려해야 하며 일반적으로 가능한 경우 테이블을 분할하지 않아야 한다.
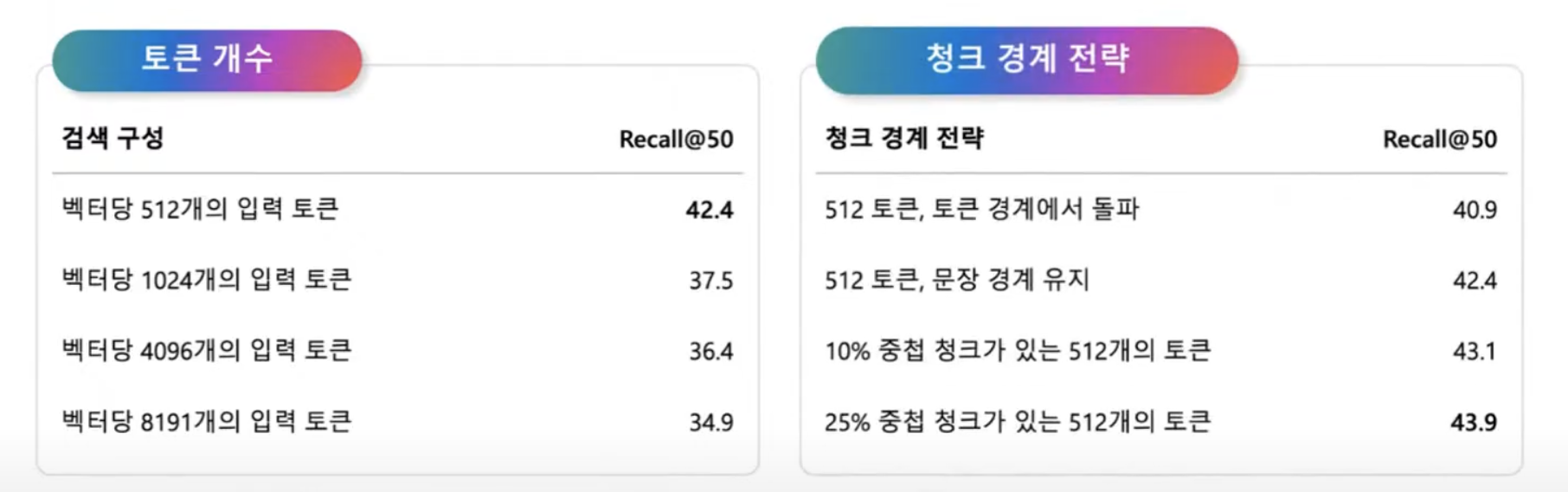
뭐가 뭔지 모르겠다면 일단 512로 먼저 잘라서 시도해보고, 처리하는 단위가 크고 복잡하다면 1024로 조금씩 늘려가며 사용해보자.
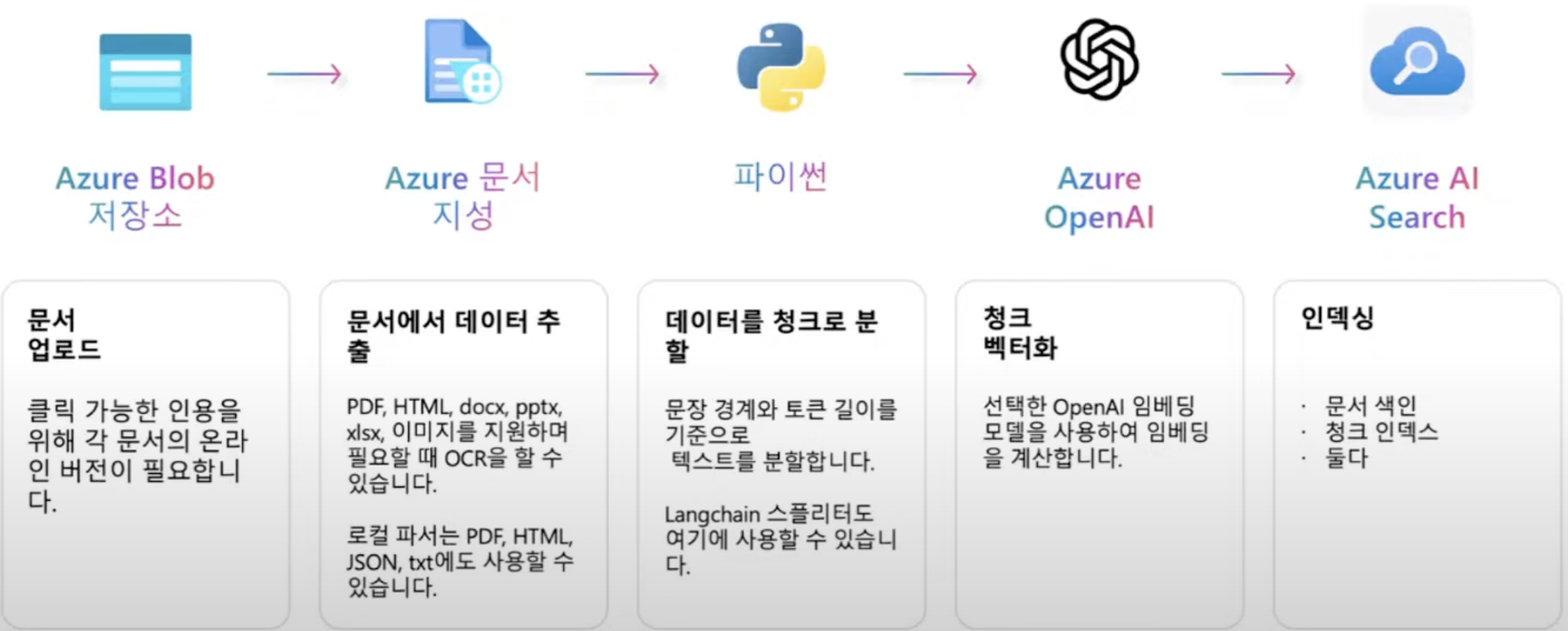
데이터 수집 프로세스
- 데이터를 일단 Azure Blob 스토리지에 저장해야한다.
- 데이터를 추출해오는 방법으로 Azure AI Search를 활용할 수 있다. PDF의 텍스트를 가져오는건 Indexer가 뽑아낼 수 있다. 사진속에 있는 글자는 OCR 기능을 사용해야 한다. 이런 스킬들을 사용하면 정보를 더 잘 뽑아낼 수 있다.
- 파이썬등을 이용해서 청크로 분할을 하고
- 임베딩 모델을 사용해서 벡터화를 하고
- 데이터들을 Azure AI Search에 넣어 Indexing 해주면
- 질문에 대한 대답을 잘 해준다.
Azure AI Search는 준비된 자료에 대해 인덱싱 시점을 지정할 수 있다.
- 한 번만 인덱싱을 할 것인지
- 매뉴얼로 시킬때마다 인덱싱 할것인지
- 특정 주기를 가지고 인덱싱 할것인지
통합 벡터화
Azure AI Search에서는 벡터화 하는 과정을 통합적으로 워크 플로우로 가져갈 수 있다.
https://learn.microsoft.com/ko-kr/azure/search/vector-search-integrated-vectorization
평가
품질에 영향을 미치는 것은?
답변에 대한 정확도를 테스트해야 한다.
질문과 답변 셋을 미리 만들어서, 결과가 몇 프로나 일치하는지 검색하며 평가하는 방법들이 있다.
- 검색 시스템 평가: 재현율, 정밀도, NDCG/MAP
- 언어 모델 평가: 공간 이동, 많은 메트릭, 작업을 고려
- 품질 및 안전성을 위해 전체 RAG 스택 평가: GPT 기반 평가 및 메트릭을 위한 AI Studio 또는 promptflow-evals
배포
보안
Azure를 사용하면 역할 기반의 엑세스 컨트롤이 가능하다.
개인 네트워크 배포
가상 네트워크에 배치하는게 좋다.
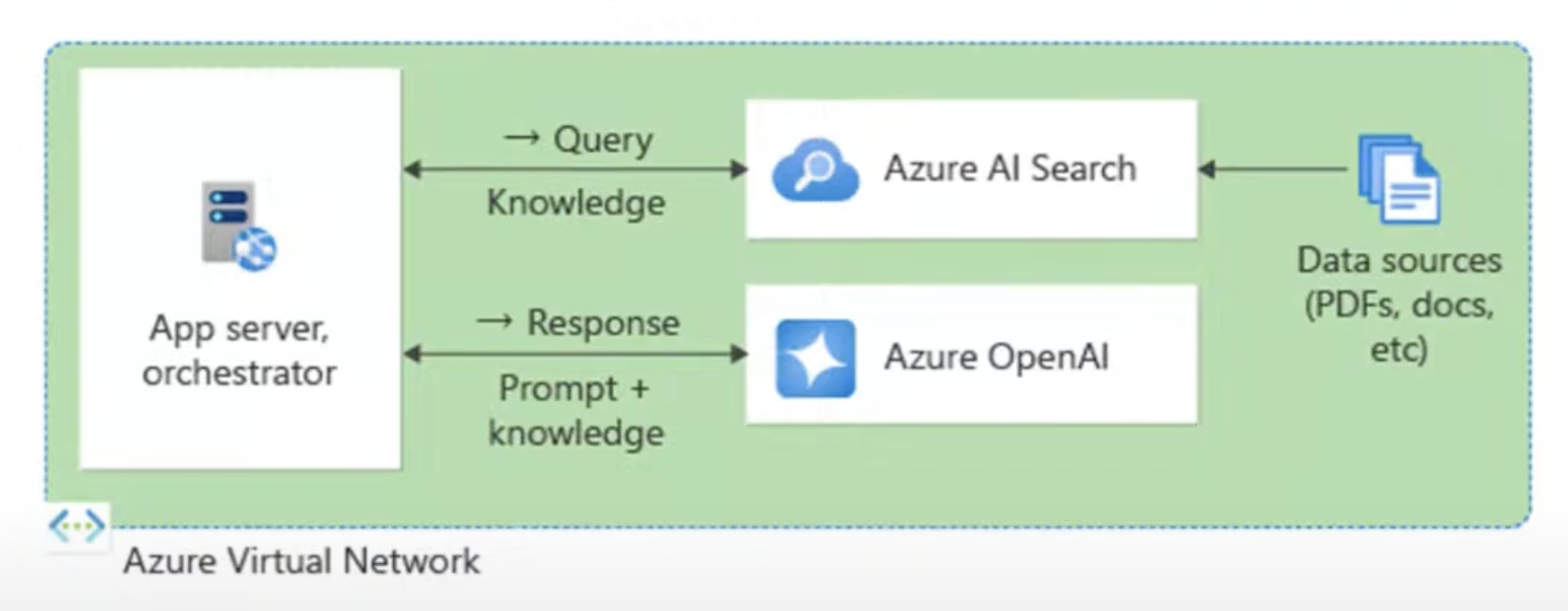

Azure AI Search와 RAG로 프로덕션 준비!
AI Learn Collection
AI Samples - Curated by Developer Relation
Outperforming vector search with hybrid retrieval and reranking
