
문제 발생
Coodori님 새로 요구사항 들어와서 스키마에 넣은 테이블 보았는데 왜 다중 PK컬럼으로 넣으신걸까요?
라는 질문을 받았다.
나는 테이블 구조를 넣을 때 단일PK컬럼으로 넣었고
평소 테이블이 크지 않아 스키마는 기본적으로 사용되는 public 스키마를 사용했는데
이번 기회에 정리 및 내가 입력한 테이블은 어떤 구조로 들어가게 되었나 찾아 보게되었다.
Postgresql 자주쓰는 명령어(RDS)
- 접속
$ psql --host=[rds public 주소] --port=[port] --username=[username] --dbname=[db이름] --password
여기서 password 는 인자가 없다.
-
SQL shell 진입시
# psql [스키마명 -
DB 데이터 베이스 출력
# \l -
DB 선택
# \c [dbname] -
DB 종료
# \q -
DB 테이블 출력
# \dt -
나머지 명령어 보기
$ psql --help
Postgresql의 Schema
PostgreSQL에서는 database와 schema 두가지 개념 모두 사용되며 database는 schema의 상위 개념이라 할 수 있습니다.
table의 집합을 schema 라고 표현하며 이 schema는 하나의 database를 논리적으로 나누는 개념입니다.
즉, MySQL에서의 논리 database는 PostgreSQL에서의 schema라고 할 수 있습니다.
database 를 생성하면 기본 Schema로 public을 사용한다.
테이블이 적으면 사용해도되지만 많아지면 다른 스키마를 추가 생성해서 테이블을 관리하는 것이 좋다.
-- 스키마(test) 생성 + authorization user 를 해서 테이블 생성이 가능하도록 함.
create schema if not exists test authorization postgres;
-- 확인
select * from pg_catalog.pg_namespace pn
order by nspname;
-- 생성한 schema 를 기준으로만 쿼리가 동작하도록 세팅
set search_path to test;
-- 제대로 스키마가 적용되었는지 확인
show search_path;DB Table 관련 명령어
- Table 생성
CREATE TABLE ACCOUNT_TEST
(
USER_ID SERIAL PRIMARY KEY,
USERNAME VARCHAR(50) UNIQUE NOT NULL,
PASSWORD VARCHAR(50) NOT NULL,
EMAIL VARCHAR(355) UNIQUE NOT NULL,
CREATED_ON TIMESTAMP NOT NULL,
LAST_LOGIN TIMESTAMP
);- fk 참조하는 것
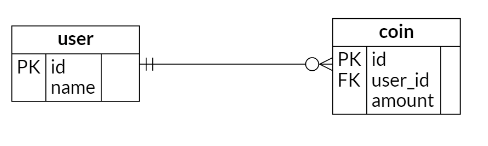
CREATE TABLE "user" (
id VARCHAR(20) PRIMARY KEY, -- 사용자 ID
name VARCHAR(20),
CONSTRAINT chk_id CHECK (CHAR_LENGTH(id) >= 5)
);CREATE TABLE coin (
id SERIAL PRIMARY KEY,
user_id VARCHAR(20) NOT NULL, -- 사용자 ID
amount INTEGER,
CONSTRAINT fk_user_id FOREIGN KEY(user_id) REFERENCES "user"(id)
);CONSTRAINT [제약명 보통 fk_fk키] FOREIGN KEY([fk키]) REFERENCES "[참조하는 테이블]"([참조하는 컬럼]) ON DELETE CASCADE ON UPDATE CASCADE
- 연관 관계 제약 조건 설정
on delete cascade
부모 테이블에서 어떤 외래키를 삭제하면, 그 외래키를 참조하는 자식 테이블의
ROW가 모두 삭제되는 기능을 부여해준다.
CREATE TABLE coin (
id SERIAL PRIMARY KEY,
user_id VARCHAR(20) NOT NULL, -- 사용자 ID
amount INTEGER,
CONSTRAINT fk_user_id FOREIGN KEY(user_id) REFERENCES "user"(id) **ON DELETE CASCADE ON UPDATE CASCADE**
);단일 PK를 사용해야하는 이유
Jpa @Id를 했을 경우 작성해준 단일 PK만 인식을 한다.
또한 다중 PK를 사용하지 않게 하기 위해 @ManyToMany 를 지양하고 다대일, 일대다로 분리하는 연결 테이블을 만든다.
다중 PK가 마냥 나쁜것은 아니다.
해당 쿼리에 대해서는 index 가 걸린 연산이기 때문에 빠르게 조회 가능하다는 것이다. PK는 행을 구분하기 위해, 다른 테이블과의 연관 관계를 알기 위해 (PK-FK) 사용한다. PK 지정 시, INDEX가 걸려 해당 칼럼으로 조회 시 굉장히 빠르게 접근 가능하다
필요한 경우 사용이 되겠지만 현재 설계상 단일 PK로 정했기 때문에 말씀해주신것이다.
내가 추가한 테이블 확인 (recommend_item)
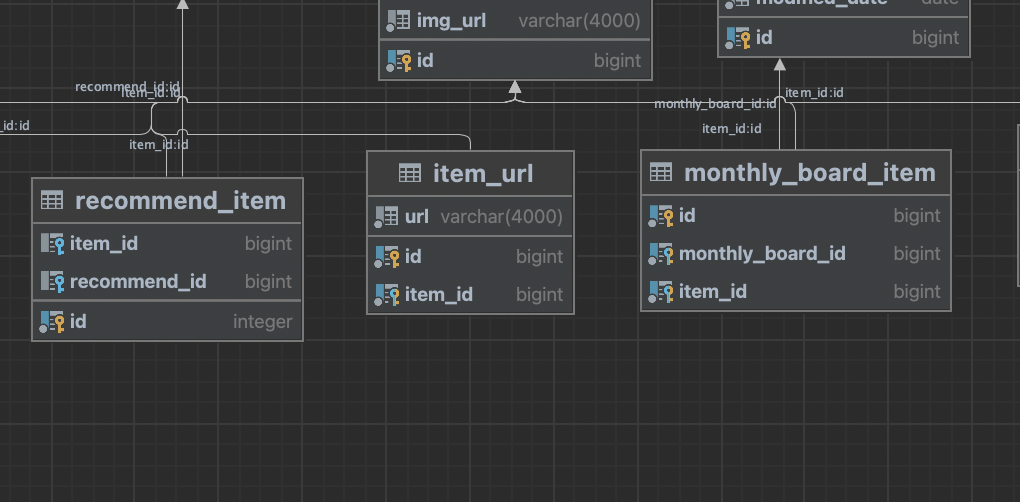
내가 만든 recommend_item을 보면 단일 컬럼으로 되어있었다.
오히려 다른 테이블들이 PK 1개와 FK 1~2개가 결합된 다중 PK컬럼으로 만들어지고 있었다.
문제 상황을 인지한뒤 바로 팀원에게 보고를 해서 수정을 완료하였다.
Reference
https://velog.io/@dailylifecoding/postgresql-create-schema-and-table
https://shanepark.tistory.com/446
https://www.postgresql.org/docs/current/datatype.html
https://kwomy.tistory.com/11
https://dog-developers.tistory.com/179
