
4.1 사라진 SQLException
JdbcTemplate으로 바꾸기 전과 후의 deletaAll() 메소드를 비교해보자.
public void delteAll() throws SQLException {
this.jdbcContext.executeSql("delete from users");
}public void delteAll() {
this.jdbcTemplate.update("delete from users");
}throw SQLException 선언이 사라진 것을 확인할 수 있다.
SQLException 선언이 사라졌으니 예외가 발생하지 않을까? NO!!!
4.1.1 초난감 예외처리
초난감 예외 처리 대표 선수들은 예외 블랙홀, 무의미하고 무책임한 throws가 있다.
초난감한 예외 처리라고 불려도 이러한 예외처리들이 필요한 경우도 있다.
예외 블랙홀
예외 블랙홀의 대표적인 예시를 떠올려 보면 예외를 은폐하는 경우라고 생각하면 쉽다.
- 쓰레드 처리 sleep()
try {
Thread.sleep(1, 500000);
} catch (InterruptedException e){}- 예외 무시하기
} catch (SQLException e) () } catch (SQLException e) {
System.out.println(e);
} } catch (SQLException e) {
e.printStackTrace();
}다시 본론으로 돌아와 책에서 말하는 예외 블랙홀 작성하면
초난감한 예외처리 방법 중 예외가 발생하면 그 예외를 catch 블록을 써서 잡아내는 것까지는 좋지만 아무것도 처리하지 않고 넘어가 버리는 경우이다. 이렇게 코드를 구현하는 경우 프로그램 실행 중 어디에선가 오류가 있어서 예외가 발생하더라도 무시하고 계속 진행 되기 때문이다.
예외가 발생하여 catch 블록을 써서 잡아내고 화면에 출력해주는 것은 무슨 문제가 있을까? 눈에 어떤에러가 발생했는지 눈에 띄어서 금방 알아차리고 조취를 취할 수 있을 것이라고 생각하지만 다른 로그나 메시지에 묻혀버린 다면 놓치기 쉽상이다. 콘솔로그를 계속해서 모니터링하지 않는 이상 예외 코드는 심각한 폭단으로 남아 있을 것이다.
예외 처리할 때 반드시 지켜야할 핵심 원칙은
모든 예외는 적절하게 복구되든지 아니면 작업을 중단시키고 운영자 또는 개발자에서 분명하게 통보돼야 한다는 점 이다.
예외를 무시해서 처리하는 것보단 프로그램을 강제로 종료시키는게 그나마 나은 예외처리 방법이다.
} catch (SQLException e) {
e.printStackTrace();
System.exit(1);
}위의 코드는 예외가 발생하면 프로그램을 강제로 종료시키는 코드이다. 발생한 예외에 대하여 조치를 취할 방법이 없을 때 문제가 더 커지지 않도록 여기서 끊어내는 것이다. 하지만 갑자기 프로그램을 죽인다면 애플리케이션 전체가 죽게 되므로 좋은 방법은 아니다.
조치를 취할 방법이 없다면 잡지 말아야한다. 메소드에 throws SQLException을 선언해서 메소드 밖으로 던지고 자신을 호출한 코드에 예외처리 책임을 전가하는 것도 해결 방법 중 하나이다.
무의미하고 무책임한 throws
throws를 한다고 해서 무의미하고 무책임한 방법이라고는 할 수 없는 것 같다. 처리 할 수 있는게 없다면 위에서 말하듯 예외를 밖으로 던져서 책임을 전가하는 것도 해결 방법 중 하나이기 때문이다.
public void method1() throws Exception { // 6. method1을 호출한 쪽으로 예외 되던지기
method2(); // 1. method2를 호출
...
}
public void method2() throws Exception { // 5. method1에게 예외 되던지기
method3(); // 2. method3를 호출
...
}
public void method3() throws Exception { // 4. method2에게 예외 되던지기
// 3. 예외 발생
...
}
예외를 무시해버리는 경우보다 낫지만 습관적으로 throws Exception을 복사해서 붙여놓는 것은 안 좋은 예외처리 방법이다.
4.1.2 예외의 종류와 특징
예외의 종류는 체크 예외(checked exception)과 언체크드 예외(unchecked exception)로 나누어 볼 수 있다.
체크 예외는 명시적인 처리가 필요한 예외를 사용하고 다루는 방법이다.
자바에서 throw를 통해 발생시킬 수 있는 예외는
크게 세가지(Error, Exception과 체크 예외, RuntimeException과 언체크/런타임 예외)가 있다.
- Error
- 에러는 시스템에 뭔가 비정상적인 상황이 발생했을 경우에 사용된다. 주로 자바 VM에서 발생시키는 것이며 애플리케이션 코드에서 잡으려고 하면 안된다. (수습이 불가능)
- Exception과 체크 예외
- Exception 클래스는 체크 예외와 언체크 예외로 구분된다. Exception
┣ IOException
┣ ClassNotFoundException
┣ …Exception
└ RuntimeException
┣ ArithmeticException
┣ ClassCastException
┣ NullPointerException
└ IndexOutOfBoundsException
- Exception 클래스는 체크 예외와 언체크 예외로 구분된다. Exception
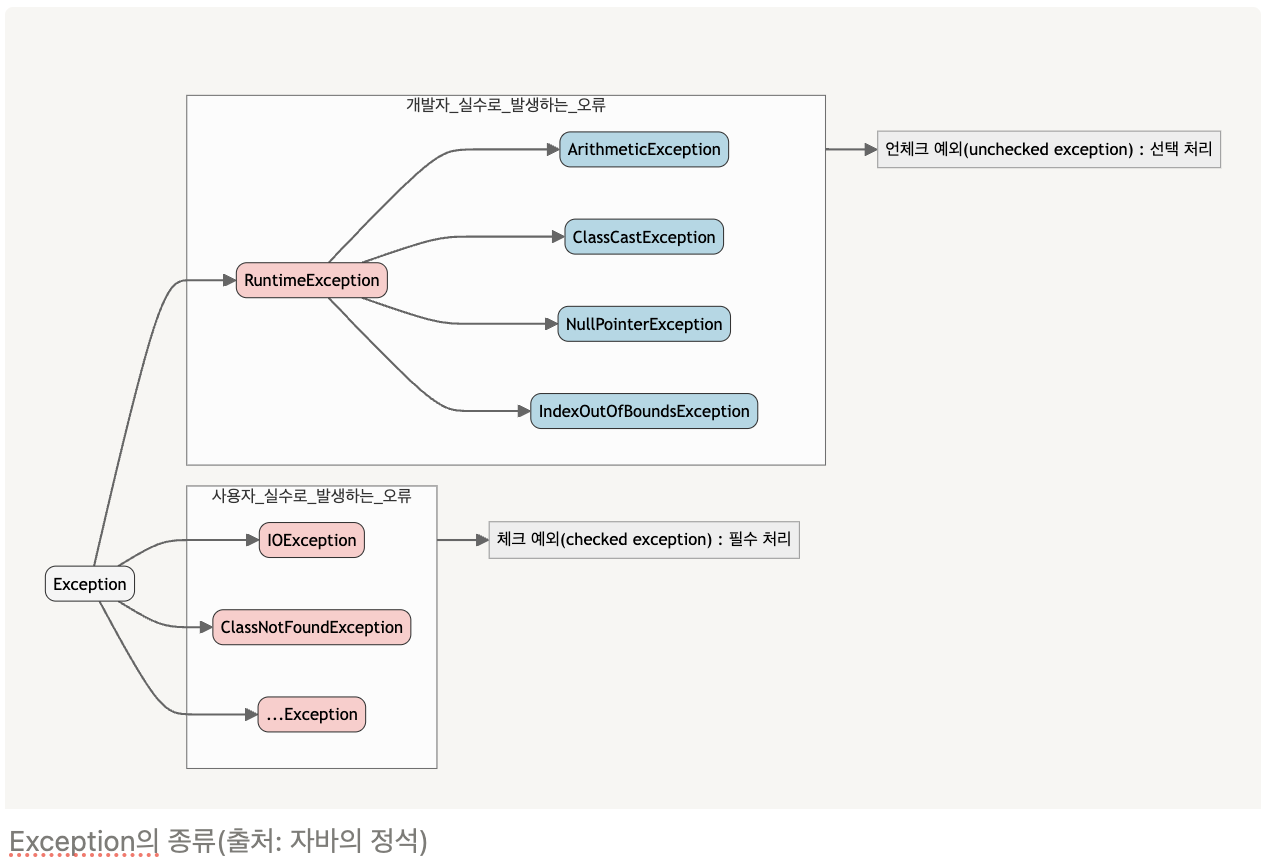
- RuntimeException과 언체크/런타임 예외
- RunctimeException 클래스를 상속한 예외들은 명시적인 예외처리를 강제하지 않는다.
- 에러와 마찬가지로 런타임 예외는 catch문으로 잡거나 throws로 선언하지 않아도 된다.
주로 프로그램의 오류가 있을 때 발생하도록 의도된 것들이다. - NullPointerException, IllegalArgumentException 등 이런 예외는 코드에서 미리 조건을 체크하도록 주의 깊게 만든 다면 피할 수 있다.
- 피할 수 있지만 개발자의 부주의(유효성 검사를 빼먹었다던지?)해서 발생할 수 있는 경우에 발생하도록 만든 것이 런타임 예외다.
4.1.3 예외처리 방법
예외는 실질적인 처리방법이 중요하다.
예외처리 전략 3가지 : 복구, 회피, 전환
예외 복구
예외 복구 : 예외상황을 파악하고 문제를 해결해서 정상 상태로 돌려놓는 것
예외 복구의 대표적인 방법으로 재시도 방법이 있다.
- 재시도 하는 방법
- 몇 번 시도 할 것인가
- 얼마 간격으로 시도 할 것인가
- 재시도 할 때는 rollback, 부작용도 고려해서 결정을 해야 한다.
예를 들어 네트워크 접속이 원활하지 않아서 예외가 발생했다면 일정 시간 대기했다가 다시 접속을 시도해보는 방법을 사용해서 예외상황으로부터 복구를 시도 할 수 있다.(정해진 횟수만큼 재시도 해서 실패했다면 예외 복구는 포기해야 한다)
int maxretry = MAX_RETRY;
while(maxretry -- > 0) {
try {
... // 예외가 발생할 가능성이 있는 시도
return; // 작업 성공
}
catch(SomeException e) {
// 로그 출력. 정해진 시간만큼 대기
}
finally {
// 리소스 반납. 정리 작업
}
}
throw new RetryfailedException(); // 최대 재시도 횟수를 넘기면 직접 예외 발생예외처리 회피
예외처리 회피 : 예외처리를 자신이 담당하지 않고 자신을 호출한 쪽으로 던져버리는 것
public void add() throws SQLException {
// JDBC API
}public void add() throws SQLException {
try {
// JDBC API
}
catch(SQLException e) {
// 로그 출력
throw e;
}예외를 회피하는 것은 예외를 복구하는 것처럼 의도가 분명해야 한다.
다른 오브젝트에게 예외처리 책임을 분명히 지게 하거나, 자신을 사용하는 쪽에서 예외를 다루는 게 최선의 방법이라는 분명한 확신이 있어야 한다.
예외 전환
예외 전환 : 예외를 그대로 넘기는 게 아니라 적절한 예외로 전환해서 메소드 밖으로 던지는 것
- 예외를 다른 예외로 변경하는 방법
- 예외 감싸기
- 새로운 예외로 만들기(사용자 정의 예외 만들기)
- 예외 묶기
- 예외가 너무 디테일하면 덜 디테일하게 바꿀 수 있음
- DB 종류가 다른 경우에도 ConnectionError, DuplicationKey, 제약조건, SQL 잘못기입, 권한 없음 등 DB마다 던지는 예외가 다를 수 있기 때문에 중립적으로 묶어서 처리할 수 있음
예외 전환은 보통 두가지 목적으로 사용된다.
- 내부에서 발생한 예외를 그대로 던지는 것이 그 예외상황에 대한 적절한 의미를 부여해주지 못하는 경우에, 의미를 분명하게 해줄 수 있는 예외로 바꿔주기 위함
- 의미가 분명한 예외가 던져지면 서비스 계층 오브젝트에는 적절한 복구 작업을 시도할 수 있다.
- 의미가 분명한 예외가 던져지면 서비스 계층 오브젝트에는 적절한 복구 작업을 시도할 수 있다.
public void add(User user) throws DuplicateUserIdException, SQLException {
try {
// JDBC를 이용해 user 정보를 DB에 추가하는 코드 또는
// 그런 기능을 가진 다른 SQLException을 던지는 메소드를 호출하는 코드
}
catch(SQLException) {
// ErrorCode가 MySQL의 "Duplicate Entry(1062)"이면 예외 전환
if (e.getErrorCode() == MysqlErrorNumbers.ER_DUP_ENTRY)
throw DuplicateUserIdException();
else
throw e; // 그 외의 경우는 SQLException 그대로
}
}- 보통 전환하는 예외에 원래 발생한 예외를 담아서 중첩 예외로 만드는 것이 좋다. getCause()메소드를 통해 처음 발생한 예외가 무엇인지 확인할 수 있고, 생성자나 initCause() 메소드로 근본 원인이 되는 예외를 넣어줄 수 있다.
catch (SQLException e) {
...
throw DuplicateUserIdException(e); catch (SQLException e) {
...
throw DuplicateUserIdException().initCause(e);- 예외를 처리하기 쉽고 단순하게 만들기 위해 포장
- 의미를 명확하게 하려고 다른 예외로 전환하는 것이 아닌
예외처리를 강제하는 체크 예외를 언체크 예외인 런타임 예외로 바꾸는 경우에 사용
- 의미를 명확하게 하려고 다른 예외로 전환하는 것이 아닌
try {
OrderHome orderHome = EJBHomeFactory.getInstance().getOrderHome();
Order order = orderHome.findByPrimaryKdy(Integer id);
} catch (NamingException ne) {
throw new EJBException(ne);
} catch (SQLException se) {
throw new EJBException(se);
} catch (RemoteException re) {
throw new EJBException(re);
} try {
OrderHome orderHome = EJBHomeFactory.getInstance().getOrderHome();
Order order = orderHome.findByPrimaryKdy(Integer id);
} catch (NamingException | SQLException | RemoteException e) {
throw new EJBException(e);
}- 이렇게 런타임 예외로 만들어서 전달하면 시스템 익셉션으로 인식하고 트랜잭션을 자동으로 롤백해준다.
- 런타임 예외이기 때문에 클라이언트에서 일일이 예외를 잡거나 다시 던지는 수고를 할 필요가 없다.
4.1.4 예외처리 전략
런타임 예외의 보편화
대응이 불가능한 체크 예외라면 빨리 런타임 예외로 전환해서 던지는 게 낫다.
언체크 예외라도 필요하다면 얼마든지 catch 블록으로 잡아서 복구하거나 처리할 수 있지만 대개 복구 불가능한 상황이고 RuntimeException 등으로 포장해서 던져야 할 테니 API 차원에서 런타임 예외를 던지도록 만드는 것이다.
add() 메소드의 예외처리
DuplicatedUserIdException처럼 의미 있는 예외는 add() 메소드를 바로 호출한 오브젝트 대신 더 앞단의 오브젝트에서 다룰 수 도 있다. 어디에서든 DuplicatedUserIdException을 잡아서 처리할 수 있다면 굳이 체크 예외로 만들지 않고 런타임 예외로 만드는게 낫다.
런타임 예외로 만드는 예시
- 사용자 아이디가 중복됐을 때 사용하는 DuplicateUserIdException을 만든다.
public class DuplicateUserIdException extends RuntimeException {
public DuplicateUserIdException(Throwable cause) {
super(cause);
}
}- add() 메소드가 SQLException을 런타임 예외로 전환해서 던지도록 만든다.
기존의 아이디 중복 때문에 SQLException이 발생한 경우에는 DuplicateUserIdException을 던지게 하는 코드는 그대로 둔다.
public void add()throws DuplicateUserIdExceiption { // 아이디 중복 예외를 처리하고 싶은 경우 활용할 수 있음을 알려줌(throws)
try {
// JDBC를 이용해 user 정보를 DB에 추가하는 코드 또는
// 그런 기능을 가진 다른 SQLException을 던지는 메소드를 호출하는 코드
}
catch(SQLException) {
if (e.getErrorCode() == MysqlErrorNumbers.ER_DUP_ENTRY)
throw new DuplicateUserIdException(e); // 예외 전환
else
throw new RuntimeException(e); // 예외 포장
}
}- 이제 add() 메소드를 사용하는 오브젝트는 SQLException을 처리하기 위해 불필요한 throws 선언을 할 필요는 없으면서, 필요한 경우 아이디 중복을 처리하기 위해 DuplicatedUserIdException을 이용할 수 있.
런타임 예외를 일반화해서 사용하는 방법은 장점이 많지만 런타임 예외로 만들었기 때문에 사용에 더 주의를 기울일 필요도 있다. 컴파일러가 예외처리를 강제하지 않으므로 신경 쓰지 않으면 예외상황을 충분히 고려하지 않을 수 도 있기 때문이다.
