
이 문제는 주문당 평균 아이템 개수를 구하는 문제이다.
단순 평균을 계산하는 것이 아닌 가중 평균 개념을 사용한다.
공식은 다음과 같다.
- 총 아이템 수 = item_count * order_occurrences의 합
- 총 주문 수 = order_occurrences의 합
- 평균 = 총 아이템 수 / 총 주문 수
1. 옛날 방식
SELECT round(
(sum(item_count * order_occurrences) / sum(order_occurrences)) * 10
) / 10 as mean
FROM items_per_order;설명
이 방식은 소수점 처리를 직접 하는 방식이다.
1. 평균값에 10을 곱한다.
2. round로 반올림한다.
3. 다시 10으로 나눈다.
특징
- PostgreSQL, MySQL 모두에서 동작이 가능하다.
(-> 문제에서 MySQL로 풀려고 했는데 테이블이 나오지 않아서 이 방식을 사용했다.) - 타입 문제 없이 안정적으로 사용이 가능하다.
- 직관적이지 않고 쿼리문이 좀 길어지는 단점이 있다.
2. ROUND 함수 사용
MySQL
SELECT round(
(sum(item_count * order_occurrences) / sum(order_occurrences))
, 1
)as mean
FROM items_per_order;PostgreSQL
SELECT round(
(sum(item_count * order_occurrences) / sum(order_occurrences))::NUMERIC
, 1
)as mean
FROM items_per_order;설명
- round(x, 반올림 위치)는 반올림 위치의 자리까지 반올림을 한다.
round(x, 1)이면 소수점 첫번째 자리까지 반올림을 하는 것이다. - MySQL은 타입에 관계없이 잘 동작한다.
- PostgreSQL은 numeric 타입으로 변환해서 사용해줘야 한다.
- PostgreSQL에서는 round(x)는 double precision에서도 동작한다.
- 하지만 소수점 자리를 지정하는 round(x, n)은 numeric 타입에서만 지원되기 때문에 명시적인 형변환이 필요하다.
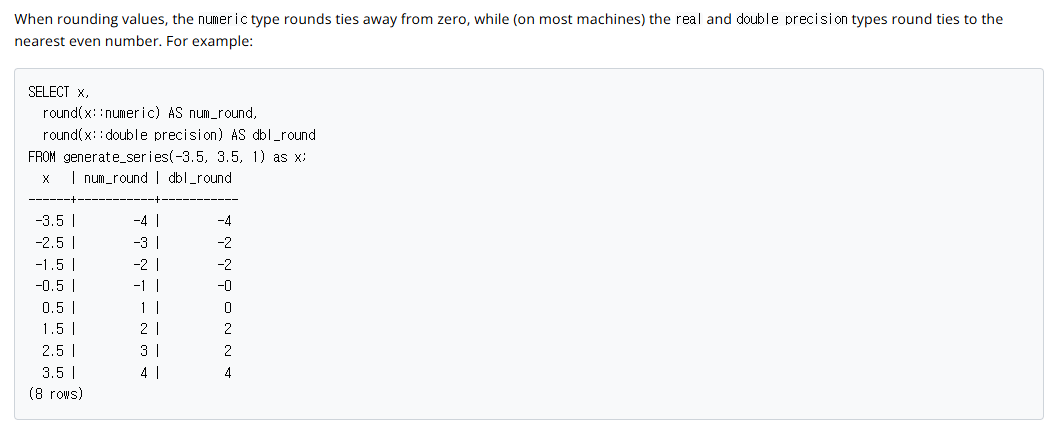
- 여기서 추가로 알 수 있는 것은 numeric은 정확한 반올림을 수행하고, double precision은 근사값을 기반으로 반올림을 수행한다는 점이다.
- 따라서 정확한 소수 계산이 필요한 경우 numeric 타입을 사용하는 것이 적절하다.
3. MySQL vs PostgreSQL
타입 처리 방식
MySQL은 타입에 비교적 관대한 편이라고 한다.
- 대부분의 경우 자동 형변환이 이루어져 편하게 사용할 수 있다.
PostgreSQL은 타입에 엄격하다.
- 타입이 맞지 않으면 에러가 발생한다.
- 명시적 캐스팅이 필요하다.
-- PostgreSQL
ROUND(double precision, 1) # 에러 발생
ROUND(numeric, 1) # 정상 동작나눗셈 결과 차이
MySQL은 정수끼리 나눗셈을 하면 자동으로 실수의 결과가 나온다.

PostgreSQL은 정수끼리 나눗셈을 하면 정수의 결과가 나온다.

그래서 PosgreSQL에서는 정확한 소수 결과를 얻기 위해서는 numeric 타입으로 캐스팅을 해주는 것이 필요하다.

개발하는 다람쥐