법정동 코드 추출하기
import pandas as pd
import requests
from bs4 import BeautifulSoup as bs행정표준코드관리시스템
https://www.code.go.kr/stdcode/regCodeL.do
아파트 실거래가 API에서 사용하는 법정동 코드 목록
(출처: 손끝으로 만드는 세상)
https://inasie.github.io/%ED%94%84%EB%A1%9C%EA%B7%B8%EB%9E%98%EB%B0%8D/5/
response = requests.get(url)
html = bs(response.text, 'lxml')
table = html.select('table')
table = pd.read_html(str(table))
gu = table[0]gu['법정동코드'] = gu['법정동코드'].astype(str)city = gu[~gu['법정동코드'].str.contains('000')]city = city[city['법정동주소'].str.contains('인천')]city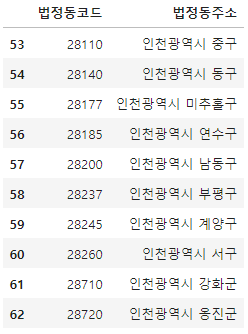
서비스키 불러오기
from urllib.request import urlopen
from urllib.parse import urlencode, unquote, quote_plus
import urllib
import requests
import pandas as pd
import xmltodict
import json
from datetime import datetimemo = [m for m in range(202101, 202113)]
mo.extend([m for m in range(202201, 202213)])
mo.extend([m for m in range(202301, 202313)])data = []
serviceKey = "인코딩키주소"url + payload주소 제대로 나오는지 확인
'https://apis.data.go.kr/1613000/~~~~~import json
import xmltodict
import pandas as pd
from urllib.parse import urlencode, quote_plus
from urllib.request import urlopen법정동 코드를 통해 추출하기
data = []
for i in city['법정동코드']:
for a in mo:
url = f'http://apis.data.go.kr/1613000/RTMSDataSvcAptTradeDev/getRTMSDataSvcAptTradeDev?serviceKey={serviceKey}'
queryParams = '&' + urlencode({quote_plus('pageNo'): 1, quote_plus('numOfRows'):'1000',quote_plus('LAWD_CD'):i, quote_plus('DEAL_YMD'):a})
url2 = url + queryParams
response = urlopen(url2)
results = response.read().decode('utf-8')
# XML to JSON-like dictionary
results_to_json = xmltodict.parse(results)
# Check if 'response', 'body', and 'totalCount' exist before accessing them
try:
if results_to_json.get('response') and results_to_json['response'].get('body'):
total_count = results_to_json['response']['body'].get('totalCount', None)
print(total_count)
# Accessing the items in the response
items = results_to_json['response']['body'].get('items', {}).get('item', None)
# Adding the items to the data list
if items:
if isinstance(items, list): # multiple items
data.extend(items)
else: # only one item
data.append(items)
print(a)
else:
print('오류: 올바르지 않은 응답 형식입니다.')
except Exception as e:
print(f'오류 발생: {e}')
# Create DataFrame from the collected data
df = pd.DataFrame(data)
# Display the DataFrame
print(df)출력은 아래와 같이 나옴
261
202101
227
202102
410
.
.
0
오류 발생: 'NoneType' object has no attribute 'get'
0
.
.
aptDong aptNm aptSeq bonbun bubun buildYear buyerGbn cdealDay \
0 None 라이프비취2차 28110-28 0027 0107 1981 None None
.
.
df.rename(columns={'old_column_name': 'new_column_name'}, inplace=True)df.columnsIndex(['aptDong', 'aptNm', 'aptSeq', 'bonbun', 'bubun', 'buildYear',
'buyerGbn', 'cdealDay', 'cdealType', 'dealAmount', 'dealDay',
'dealMonth', 'dealYear', 'dealingGbn', 'estateAgentSggNm', 'excluUseAr',
'floor', 'jibun', 'landCd', 'landLeaseholdGbn', 'rgstDate', 'roadNm',
'roadNmBonbun', 'roadNmBubun', 'roadNmCd', 'roadNmSeq', 'roadNmSggCd',
'roadNmbCd', 'sggCd', 'slerGbn', 'umdCd', 'umdNm'],
dtype='object')컬럼명 변경
이름을 바꾸기 위해 공공데이터포털의 기술문서를 확인한 후
한국어 이름으로 변경한다.
변경할 때는 엑셀 & 메모장을 통해 아래 방법을 사용한다.
엑셀 CONCATENATE 함수 사용법 및 실전예제 총정리(오빠두엑셀)
https://www.oppadu.com/%EC%97%91%EC%85%80-concatenate-%ED%95%A8%EC%88%98/
df.rename(columns = {'aptDong' : '아파트',
'aptNm' : '단지명',
'aptSeq' : '단지',
'bonbun' : '법정동본번코드',
'bubun' : '법정동부번코드',
'buildYear' : '건축년도',
'buyerGbn' : '매수자',
'cdealDay' : '해제사유발생일',
'cdealType' : '해제여부',
'dealAmount' : '거래금액',
'dealDay' : '계약일',
'dealMonth' : '계약월',
'dealYear' : '계약년도',
'dealingGbn' : '거래유형',
'estateAgentSggNm' : '중개사소재지',
'excluUseAr' : '전용면적',
'floor' : '층',
'jibun' : '지번',
'landCd' : '법정동지번코드',
'landLeaseholdGbn' : '토지임대부',
'rgstDate' : '등기일자',
'roadNm' : '도로명',
'roadNmBonbun' : '도로명건물본번',
'roadNmBubun' : '도로명건물부번',
'roadNmCd' : '도로명코드',
'roadNmSeq' : '도로명일련번호',
'roadNmSggCd' : '도로명시군구코드',
'roadNmbCd' : '도로명지상지하',
'sggCd' : '법정동시군구코드',
'slerGbn' : '매도자',
'umdCd' : '법정동읍면동코드',
'umdNm' : '법정동'}, inplace = True)컬럼명 바뀌었는지 재확인한다.
df.columnsIndex(['아파트', '단지명', '단지', '법정동본번코드', '법정동부번코드', '건축년도', '매수자', '해제사유발생일',
'해제여부', '거래금액', '계약일', '계약월', '계약년도', '거래유형', '중개사소재지', '전용면적', '층',
'지번', '법정동지번코드', '토지임대부', '등기일자', '도로명', '도로명건물본번', '도로명건물부번', '도로명코드',
'도로명일련번호', '도로명시군구코드', '도로명지상지하', '법정동시군구코드', '매도자', '법정동읍면동코드', '법정동'],
dtype='object')거래금액에 있는 쉼표를 없애기 위해 람다를 쓴다.
*주의사항: 람다는 두번 엔터치면 값이 날라갈 수도 있음
만약에 잘못 친다고 하면 다시 처음부터 실행->실행 해야 함.
df['거래금액'] = df['거래금액'].apply(lambda x : int(x.replace(',', '')))원하는 컬럼 추출
거래금액 기준으로 정렬하고, 내가 원하는 컬럼만 추출한다.
전용면적으로 평수를 구한다.
더 쉽게 알아보기 위해 아파트 단지명에 계약년도를 붙여서
이를 '아파트거래연도'로 칭한다.
df1 = df.sort_values(by = '거래금액', ascending = False)[['거래금액', '법정동', '아파트', '계약년도', '계약월', '층', '전용면적', '단지명']]
df1['평수'] = df1['전용면적'].apply(lambda x : round(float(x) * 0.3025, 2))
df1['아파트거래연도'] = df1['단지명']+' '+df1['계약년도']헤드 10개만 보고 리인덱스
df1_10 = df1.head(10).reset_index()
df1.head()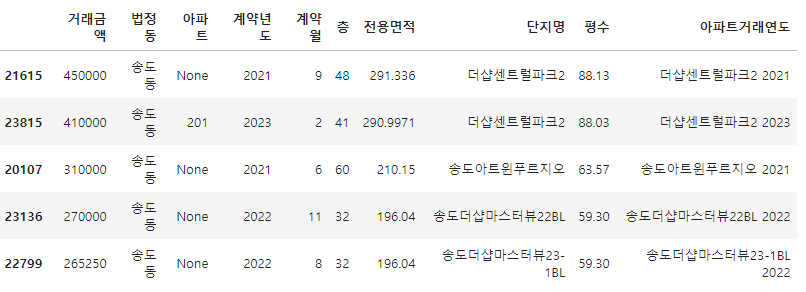
최근 3년 거래금액 top 10 알아보기
## 최근3년 거래금액 Top 10
import matplotlib.pyplot as plt
from matplotlib.patches import Rectangle
import seaborn as snsplt.rcParams['font.family'] = 'Malgun Gothic'
plt.rcParams['font.size'] = 12
plt.figure(figsize = (12, 10))
plt.title('최근3년 거래금액 Top 10 ')
sns.barplot(x = '거래금액', y = df1_10['아파트거래연도'].tolist(), data = df1_10, palette = sns.color_palette('deep', 10))
## https://steadiness-193.tistory.com/297
display(df1_10)

막대 그래프 확인
인천시에서는 연수구 송도동에 위치한 더샵센트럴파크2 단지가 top1인것으로 나왔는데, 자세히 알아보자.
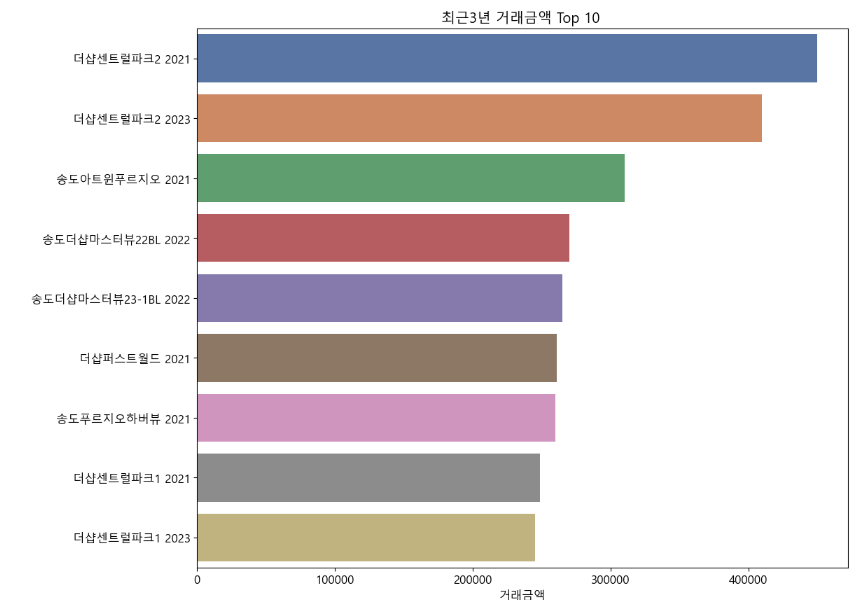
검증을 위해 아파트실거래가 아실 플랫폼을 통해 조회한 결과
실제로 2021년도 9월에 119평 매물이 매매 45억에 팔린 것을 확인할수 있었다.

출처(아실): https://asil.kr/asil/index.jsp
