가. API 불러오기 & 기본정보 조회
1. OpenDartReader 설치
!pip install OpenDartReader2. OpenDartReader, pandas 임포트 및 API 불러오기
import OpenDartReader
import pandas as pd
my_api = '보안필수'
dart = OpenDartReader(my_api)3. 주식종목 리스트 조회 하기
stock_list
4. api를 통한 재무제표 불러오기 (종목코드, 희망연도)
# api를 통한 재무제표 불러오기 (종목코드, 희망연도)
dart.finstate("005380", 2023)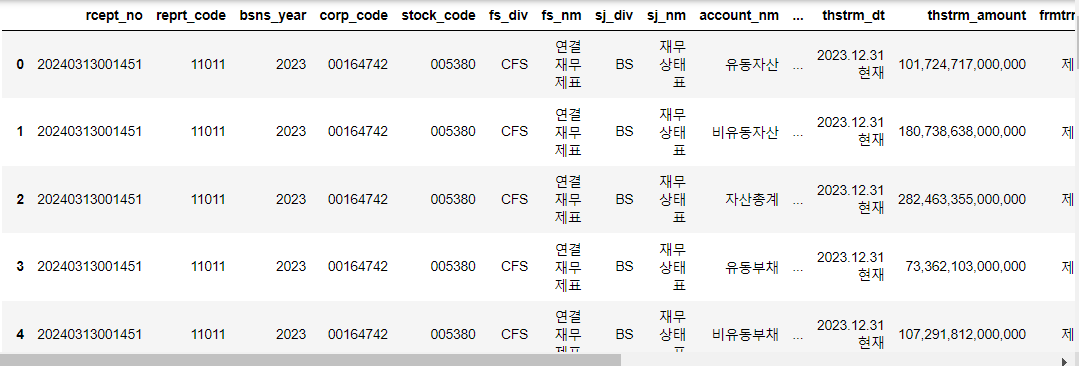
2023년도 현대차의 정보를 가져올 것이다.
*올해가 2024년도니 당연히 2024년도 재무제표는 없다. 전년도(2023년도)가 가장 최신 자료이다.
5. 심볼이 특정 값인 것 가져오기
stock_list.loc[stock_list["Symbol"] == "005380"] # 심볼이 특정 값인 것 가져오기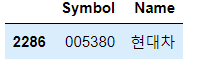
6. 네임이 특정 값인 것 가져오기
이름으로도 검색해서 가져올 수 있다. (결과는 동일해서 생략한다.)
stock_list.loc[stock_list["Name"] == "현대차"] # 네임이 특정 값인 것 가져오기나. 사용자 정의 함수를 통한 재무제표 추출
1. numpy, pandas 임포트
import numpy as np
import pandas as pd2. def 함수를 통한 재무제표 추출
def find_fins_ind_list(stock_code, stock_name, year, ind_list):
try: # 데이터 가져오기
report = None
report = dart.finstate(stock_code, year) # 스탁코드와 연도
except:
pass
if report is None: # 리포트가 없다면 (참고: 리포트가 없으면 None을 반환함)
# 리포트가 없으면 당기, 전기, 전전기 값 모두 제거
data = [[stock_name, year] + [np.nan] * len(ind_list)] # 당기
data.append([stock_name, year - 1] + [np.nan] * len(ind_list)) # 전기
data.append([stock_name, year - 2] + [np.nan] * len(ind_list)) # 전전기
else:
report = report[report["account_nm"].isin(ind_list)] # 관련 지표로 필터링
if sum(report["fs_nm"] == "연결재무제표") > 0:
# 연결재무제표 데이터가 있으면 연결재무제표를 사용
report = report.loc[report["fs_nm"] == "연결재무제표"]
else:
# 연결재무제표 데이터가 없으면 일반재무제표를 사용 (그냥 제무제표)
report = report.loc[report["fs_nm"] == "재무제표"] #
data = []
for y, c in zip([year, year - 1, year - 2], #2023 ~ 2021
["thstrm_amount", "frmtrm_amount", "bfefrmtrm_amount"]): #자산, 부채, 자본총계
record = [stock_name, y] #스탁코드, 연도
for ind in ind_list:
# account_nm이 indic인 행의 c 컬럼 값을 가져옴
if sum(report["account_nm"] == ind) > 0: # 기수별 당기순이익의 총합으로 계산해야 함
value = report.loc[report["account_nm"] == ind, c].iloc[0]
else:
value = np.nan
record.append(value)
data.append(record)
return pd.DataFrame(data, columns=["기업", "연도"] + ind_list) # 한 프레임에 담기 위해 + 사용
find_fins_ind_list 함수
def find_fins_ind_list(stock_code, stock_name, year, ind_list):
try: # 데이터 가져오기
report = None
report = dart.finstate(stock_code, year) # 스탁코드와 연도
except:
stock_code (주식 코드), stock_name (주식 이름), year (연도), ind_list (재무 지표 목록)을 인자로 받는다.
try 블록에서 dart.finstate(stock_code, year)를 호출하여 주식 코드와 연도로 재무제표를 가져온다.
except 블록에서 예외 발생 시 아무 것도 하지 않고 패스한다. (pass)
report & 연결재무제표
if report is None: # 리포트가 없다면 (참고: 리포트가 없으면 None을 반환함)
# 리포트가 없으면 당기, 전기, 전전기 값 모두 제거
data = [[stock_name, year] + [np.nan] * len(ind_list)] # 당기
data.append([stock_name, year - 1] + [np.nan] * len(ind_list)) # 전기
data.append([stock_name, year - 2] + [np.nan] * len(ind_list)) # 전전기
else:
report = report[report["account_nm"].isin(ind_list)] # 관련 지표로 필터링
if sum(report["fs_nm"] == "연결재무제표") > 0:
# 연결재무제표 데이터가 있으면 연결재무제표를 사용
report = report.loc[report["fs_nm"] == "연결재무제표"]
else:
# 연결재무제표 데이터가 없으면 일반재무제표를 사용 (그냥 제무제표)
report = report.loc[report["fs_nm"] == "재무제표"] #
data = []
for y, c in zip([year, year - 1, year - 2], #2023 ~ 2021
["thstrm_amount", "frmtrm_amount", "bfefrmtrm_amount"]): #자산, 부채, 자본총계
[if문]
report가 None이면,
해당 연도와 이전 두 연도 ( year, year - 1, year - 2 )의 재무 데이터를 NaN 값으로 채운다.
len(ind_list) 을 곱하면 0 이 된다.
[np.nan] * len(ind_list)
재무지표 리스트(ind_list)의 길이만큼 NaN 값을 생성한다.
ind_list가 ['자산총계', '부채총계', '자본총계', '매출액', '영업이익', '당기순이익']와 같이 6개의 지표를 포함하고 있다면,
[np.nan] * len(ind_list)는 [np.nan, np.nan, np.nan, np.nan, np.nan, np.nan]과 동일한다.
따라서, [[stock_name, year] + [np.nan] * len(ind_list)]는
[[stock_name, year, np.nan, np.nan, np.nan, np.nan, np.nan, np.nan]]을 생성한다.
모든 연도에 대해 동일한 수의 열을 가지도록 함으로써 데이터프레임의 형식을 일관되게 유지할 수 있다.
if report is None: # 리포트가 없다면 (참고: 리포트가 없으면 None을 반환함)
# 리포트가 없으면 당기, 전기, 전전기 값 모두 제거
data = [[stock_name, year] + [np.nan] * len(ind_list)] # 당기
data.append([stock_name, year - 1] + [np.nan] * len(ind_list)) # 전기
data.append([stock_name, year - 2] + [np.nan] * len(ind_list)) # 전전기[else문]
report가 존재하면, ind_list에 있는 재무 지표들로 필터링한다.
else:
report = report[report["account_nm"].isin(ind_list)] # 관련 지표로 필터링[작은 if/else문]
연결재무제표가 존재하면 이를 사용하고,
그렇지 않으면(연결재무제표가 없으면) 일반재무제표를 사용한다.
if sum(report["fs_nm"] == "연결재무제표") > 0:
# 연결재무제표 데이터가 있으면 연결재무제표를 사용
report = report.loc[report["fs_nm"] == "연결재무제표"]
else:
# 연결재무제표 데이터가 없으면 일반재무제표를 사용 (그냥 제무제표)
report = report.loc[report["fs_nm"] == "재무제표"]
반복과 저장
각 연도별 (year, year - 1, year - 2)로 반복하면서
재무 지표(ind_list) 값을 추출하여 data 리스트에 저장한다.
data 리스트를 데이터프레임으로 변환하여 반환한다.
3. ind_list 이름을 정하고, 특정 주식 종목의 재무제표 리스트만 조회하기
ind_list = ['자산총계', '부채총계', '자본총계', '매출액', '영업이익', '당기순이익']
display(find_fins_ind_list("005380", "현대차", 2023, ind_list))
ind_list를 ['자산총계', '부채총계', '자본총계', '매출액', '영업이익', '당기순이익']로 설정한다.
find_fins_ind_list 함수를 stock_code "005380", stock_name "현대차", year 2023, ind_list를 인자로 호출한다.
결과를 display 함수를 통해 화면에 표시한다.
다. FOR 문을 통한 특정 데이터 추출
1. time 임포트 & for 문 사용
import time
data = pd.DataFrame() # 이 데이터프레임에 각각의 데이터를 추가할 예정
for code, name in stock_list[['Symbol', 'Name']].values:
print(name)
for year in [2015, 2018, 2023]:
result = find_fins_ind_list(code, name, year, ind_list) # 재무지표 데이터
data = pd.concat([data, result], axis = 0, ignore_index = True) # data에 부착
time.sleep(0.5)
출력된 결과를 보면, '조회된 데이터가 없습니다' 라는 메세지가 뜨면서 패스한다.
다음으로 넘어가야 원하는 데이터 프레임을 얻을 수 있다.
for code, name in stock_list[['Symbol', 'Name']].values:
stock_list 데이터프레임의 Symbol 열과 Name 열을 순회함
각 주식 종목의 코드(code)와 이름(name)을 순서대로 가져옴
for year in [2015, 2018, 2023]:
2015년, 2018년, 2023년 각각에 대해 루프를 돌며 재무제표 데이터를 추출
result = find_fins_ind_list(code, name, year, ind_list)
주식 코드(code), 주식 이름(name), 연도(year), 재무 지표 목록(ind_list)을 인자로 전달하여 해당 주식의 재무제표 데이터를 가져옴
data = pd.concat([data, result], axis=0, ignore_index=True)
pd.concat 함수를 사용하여 기존의 data와 새로 가져온 result을 세로로(axis=0) 연결함
ignore_index=True옵션을 사용하여 인덱스를 무시하고, 새로운 연속 인덱스를 생성함
결과적으로 data 데이터프레임에 새로운 재무제표 데이터가 추가됨
time.sleep(0.5)
각 요청 사이에 0.5초 동안 대기함
- API 호출이나 데이터 수집 시 서버에 과도한 부하를 주지 않기 위해 일정 시간 간격을 둔다.
2. 자료 파일로 만들어 저장하기
data = pd.read_csv(
"C:/Users/내이름/Desktop/폴더1/폴더2/재무지표.csv",
encoding = "euc-kr")3. 데이터 인포확인
data.info()
4. 특정 값을 숫자로 변환하기
#숫자로 모두 변환
def convert_str_to_float(value):
if type(value) == float: # nan의 자료형은 float임
return value
elif value == '-':
return 0
else:
return float(value.replace(',',''))convert_str_to_float 함수는 주어진 값을 숫자로 변환한다.
조건 1: 입력값이 float 타입인 경우
만약 입력값이 float 타입이라면, 해당 값을 그대로 반환함.
NaN(Not a Number) 값의 자료형이 float 이기 때문에, 이미 float 타입인 경우 변환할 필요가 없다.
조건 2: 입력값이 '-'인 경우
만약 입력값이 문자열 '-'이라면, 숫자 0으로 변환하여 반환한다.
(당시 리포트에서는 - 이 0 을 의미했을 것이다.)
조건 3: 입력값이 문자열인 경우
위의 두 조건을 만족하지 않는 경우,
입력값이 문자열이라면 쉼표(',')를 제거한 후 float 타입으로 변환하여 반환함
5. 컨버트한 항목 담기
for ind in ind_list:
# print(ind)
data[ind] = data[ind].apply(convert_str_to_float)for ind in ind_list:
ind_list에 포함된 각 재무 지표(열 이름)를 순회한다.
['자산총계', '부채총계', '자본총계', '매출액', '영업이익', '당기순이익']인 경우,
이 루프는 각 항목에 대해 반복됨
data[ind]
data 데이터프레임에서 현재 재무 지표(ind)에 해당하는 열을 선택함
.apply(convert_str_to_float)
apply 메소드를 사용하여 data[ind] 열의 각 값에 convert_str_to_float 함수를 적용함
각 값이 함수에 의해 숫자로 변환된다.
결과적으로, data 데이터프레임의 각 재무 지표 열이 문자열에서 숫자로 변환됨.
data.head(5)
6. 컨버트한 항목만 조회해보기
data[ind].apply(convert_str_to_float)
convert_str_to_float(data[ind][0])-5599032927.0
[0] <-- 이런식으로 코딩하면 특정 항목만 조회할 수도 있다.
7. 중복 제거, 기업/연도로 정렬하기
data.drop_duplicates(inplace = True) # inplace= True 바뀐상태로 적용 / 똑같은 값 중복 제거(같은 행이 여러번 쌓일 때 처리)
data.sort_values(by = ['기업', '연도'], inplace= True) # inplace= True 바뀐상태로 적용
data
8. 재무제표 안에서 원하는 비율 계산해서 열 만들기
data['부채비율'] = data['부채총계'] / data['자본총계'] * 100
display(data['부채비율'].head())
#인덱스가 이미 틀어진 상태2 41.618347
1 65.869563
0 77.544311
5 66.878947
4 84.055918
Name: 부채비율, dtype: float64라. 사용자 정의 함수를 통해 적자/흑자전환 여부 추출
1. 사용자 정의 함수 만들기
# 상태를 나타내는 함수 정의
def add_state(data, col):
data[col + "_상태"] = np.nan # 상태를 결측으로 초기화
value = data[col].values
cur_value = value[1:] # 현재
pre_value = value[:-1] # 과거
# 흑자지속
cond1 = (cur_value > 0) & (pre_value > 0)
cond1 = np.insert(cond1, 0, np.nan) #nan이 나온다면 0으로 전환
# 적자지속
cond2 = (cur_value <= 0) & (pre_value <= 0)
cond2 = np.insert(cond2, 0, np.nan)
# 흑자전환
cond3 = (cur_value > 0) & (pre_value <= 0)
cond3 = np.insert(cond3, 0, np.nan)
# 적자전환
cond4 = (cur_value <= 0) & (pre_value > 0)
cond4 = np.insert(cond4, 0, np.nan)
# 조건에 따른 변환
data.loc[cond1, col + "_상태"] = "흑자지속"
data.loc[cond2, col + "_상태"] = "적자지속"
data.loc[cond3, col + "_상태"] = "흑자전환"
data.loc[cond4, col + "_상태"] = "적자전환"data[col + "_상태"] = np.nan
데이터프레임 data에 새로운 열을 추가하고, 초기값을 NaN으로 설정함.
새로운 열의 이름은 col 열 이름 뒤에 "상태"를 붙인 형태임 (예: 매출액 상태).
value = data[col].values
데이터프레임 data의 col 열 값을 value 에 저장함.
cur_value = value[1:]
cur_value는 현재 값을 나타내며, value 배열에서 첫 번째 값을 제외한 나머지 값을 가져옴.
pre_value = value[:-1]
pre_value는 과거 값을 나타내며, value 배열에서 마지막 값을 제외한 나머지 값을 가져옴.
np.insert(cond??, 0, np.nan)
첫 번째 위치에 NaN 값을 삽입하여 길이를 맞춤.
조건에 따른 변환
data.loc[cond1, col + "_상태"] = "흑자지속": cond1이 참인 위치에 "흑자지속"을 설정함.
data.loc[cond2, col + "_상태"] = "적자지속": cond2이 참인 위치에 "적자지속"을 설정함.
data.loc[cond3, col + "_상태"] = "흑자전환": cond3이 참인 위치에 "흑자전환"을 설정함.
data.loc[cond4, col + "_상태"] = "적자전환": cond4이 참인 위치에 "적자전환"을 설정함.
2. add_state 를 통해 매출액, 영업이익, 당기순이익 추가하기
add_state(data, "매출액")
add_state(data, "영업이익")
add_state(data, "당기순이익")add_state 함수를 호출하여
data 데이터프레임의 매출액, 영업이익, 당기순이익 열에 대해 각각 상태 정보를 추가함.
각 호출은 해당 열에 "_상태" 열을 추가하여, 흑자지속, 적자지속, 흑자전환, 적자전환 상태를 설정함.
3. 데이터 확인
data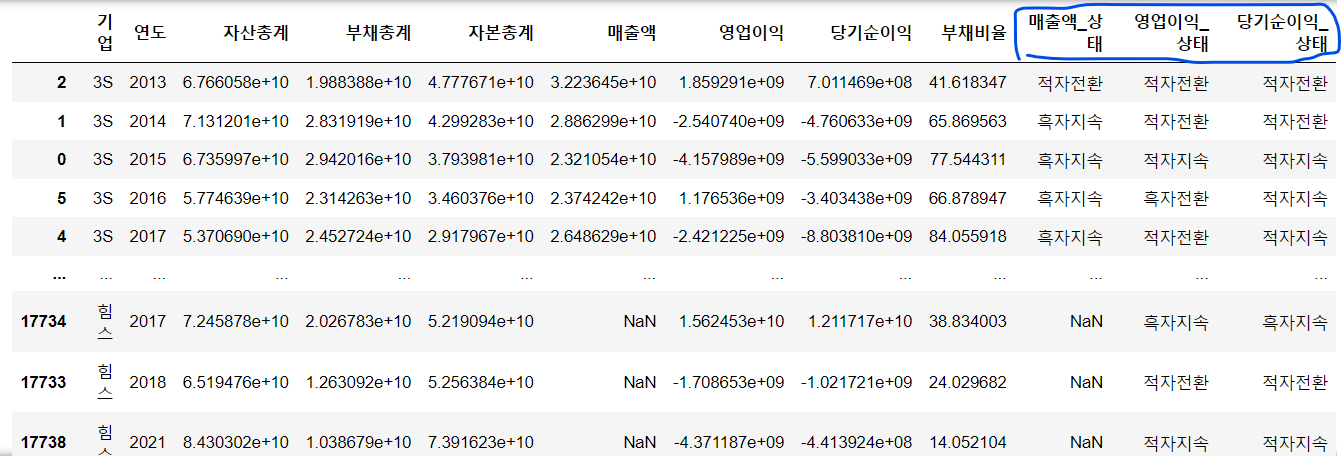
마. ROE / ROA 구하기
1. ROA 구하기
ROA = 당기순이익 / 자산총계 * 100
(자산 대비 당기순이익의 비율)
data['ROA'] = (data['당기순이익'] / data['자산총계']) * 1002. ROE 구하기
average_equity = data['자본총계'].rolling(2).mean()
data['ROE'] = (data['당기순이익'] / average_equity ) * 100average_equity는 자본총계의 이동평균(2개 행을 기준으로 평균)을 계산한다.
ROE = 당기순이익 / average_equity * 100
3. 특정 연도(2013년)만 추출하여 ROE 값을 NaN으로 설정
data.loc[data['연도'] == 2013, 'ROE'] = np.nan
data.loc[data['연도'] == 2013, 'ROE'] 2 NaN
11 NaN
20 NaN
29 NaN
44 NaN
..
17687 NaN
17696 NaN
17705 NaN
17717 NaN
17726 NaN
Name: ROE, Length: 1681, dtype: float642013년의 ROE 값이 NaN으로 설정되어 해당 값들이 NaN으로 출력된다.
4. 데이터 저장
data.to_csv("주요재무제표_수정.csv", index= False, encoding="euc-kr")