지도 시각화
단계 구분도
- 지역별 통계치를 색깔의 차이로 표현한 지도
- 인구나 소득 같은 특성이 지역별로 얼마나 다른 이해하기가 쉽다.
패키지설치
install.packages('ggiraphExtra')
library(ggiraphExtra)
미국 주별 범죄 데이터 준비
str(USArrests)
'data.frame': 50 obs. of 4 variables:
$ Murder : num 13.2 10 8.1 8.8 9 7.9 3.3 5.9 15.4 17.4 ...
$ Assault : int 236 263 294 190 276 204 110 238 335 211 ...
$ UrbanPop: int 58 48 80 50 91 78 77 72 80 60 ...
$ Rape : num 21.2 44.5 31 19.5 40.6 38.7 11.1 15.8 31.9 25.8 ...library(tibble)
head(USArrests)
Murder Assault UrbanPop Rape
Alabama 13.2 236 58 21.2
Alaska 10.0 263 48 44.5
Arizona 8.1 294 80 31.0
Arkansas 8.8 190 50 19.5
California 9.0 276 91 40.6
Colorado 7.9 204 78 38.71. 행 이름을 state 변수로 바꿔서 데이터 프레임 생성
crime <- rownames_to_column(USArrests, var='state')
crime
> crime
state Murder Assault UrbanPop Rape
1 Alabama 13.2 236 58 21.2
2 Alaska 10.0 263 48 44.5
3 Arizona 8.1 294 80 31.0
4 Arkansas 8.8 190 50 19.5
5 California 9.0 276 91 40.6
6 Colorado 7.9 204 78 38.7
7 Connecticut 3.3 110 77 11.1
8 Delaware 5.9 238 72 15.8
9 Florida 15.4 335 80 31.9
10 Georgia 17.4 211 60 25.8
11 Hawaii 5.3 46 83 20.2
12 Idaho 2.6 120 54 14.2
13 Illinois 10.4 249 83 24.0
14 Indiana 7.2 113 65 21.0
15 Iowa 2.2 56 57 11.3
16 Kansas 6.0 115 66 18.0
17 Kentucky 9.7 109 52 16.3
18 Louisiana 15.4 249 66 22.2
19 Maine 2.1 83 51 7.8
20 Maryland 11.3 300 67 27.8
21 Massachusetts 4.4 149 85 16.3
22 Michigan 12.1 255 74 35.1
23 Minnesota 2.7 72 66 14.9
24 Mississippi 16.1 259 44 17.1
25 Missouri 9.0 178 70 28.2
26 Montana 6.0 109 53 16.4
27 Nebraska 4.3 102 62 16.5
28 Nevada 12.2 252 81 46.0
29 New Hampshire 2.1 57 56 9.5
30 New Jersey 7.4 159 89 18.8
31 New Mexico 11.4 285 70 32.1
32 New York 11.1 254 86 26.1
33 North Carolina 13.0 337 45 16.1
34 North Dakota 0.8 45 44 7.3
35 Ohio 7.3 120 75 21.4
36 Oklahoma 6.6 151 68 20.0
37 Oregon 4.9 159 67 29.3
38 Pennsylvania 6.3 106 72 14.9
39 Rhode Island 3.4 174 87 8.3
40 South Carolina 14.4 279 48 22.5
41 South Dakota 3.8 86 45 12.8
42 Tennessee 13.2 188 59 26.9
43 Texas 12.7 201 80 25.5
44 Utah 3.2 120 80 22.9
45 Vermont 2.2 48 32 11.2
46 Virginia 8.5 156 63 20.7
47 Washington 4.0 145 73 26.2
48 West Virginia 5.7 81 39 9.3
49 Wisconsin 2.6 53 66 10.8
50 Wyoming 6.8 161 60 15.61-2. 지도 데이터와 동일하게 맞추기 위해 state 값을 소문자로 수정
crimestate)
str(crime)
'data.frame': 50 obs. of 5 variables:
$ state : chr "alabama" "alaska" "arizona" "arkansas" ...
$ Murder : num 13.2 10 8.1 8.8 9 7.9 3.3 5.9 15.4 17.4 ...
$ Assault : int 236 263 294 190 276 204 110 238 335 211 ...
$ UrbanPop: int 58 48 80 50 91 78 77 72 80 60 ...
$ Rape : num 21.2 44.5 31 19.5 40.6 38.7 11.1 15.8 31.9 25.8 ...2. 미국 주 지도 데이터 준비
library(ggplot2)
ggplot2 패키지를 로드합니다.
states_map <- map_data('state')
미국 주 지도를 그릴 수 있는 데이터셋을 로드합니다.
str(states_map)
지도 데이터의 구조를 확인합니다
3. 단계 구분도 생성
ggChoropleth(data=crime, # 지도에 표시할 데이터
aes(fill=Murder, # 색깔로 표현할 변수
map_id=state), # 지역 기준 변수
map = states_map) # 지도 데이터
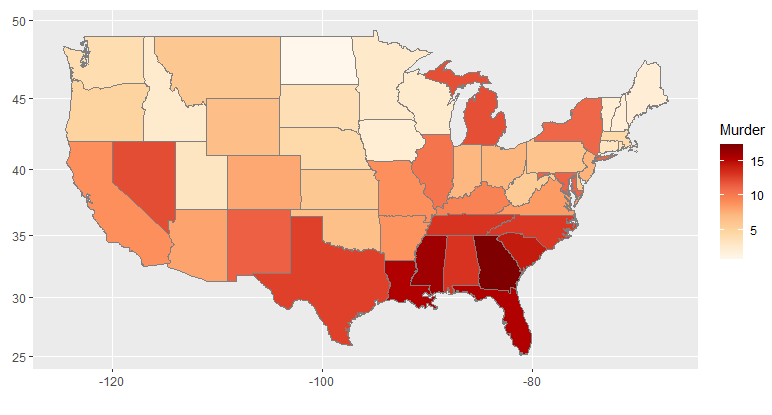
ggChoropleth()
ggiraphExtra 패키지를 사용하여 단계 구분도를 생성한다.
data=crime
범죄 데이터(crime)를 사용한다.
aes(fill=Murder, map_id=state)
Murder(살인율) 변수를 색깔로 나타내고,
state 변수를 지도 구역과 매핑한다.
map=states_map
states_map 지도를 사용한다.
4. 인터렉티브 단계 구분도 생성
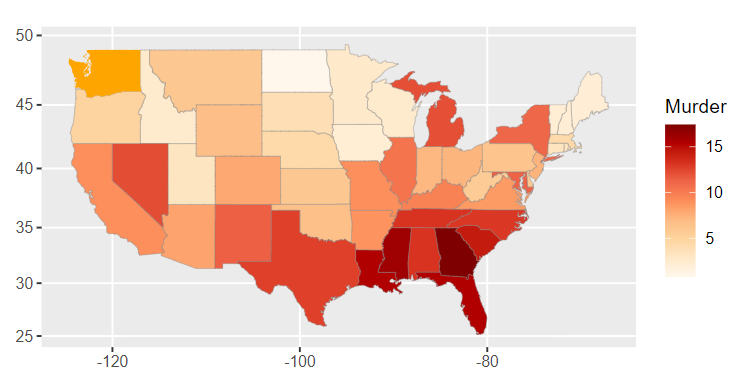
ggChoropleth(data=crime,
aes(fill=Murder,
map_id=state),
map = states_map,
interactive = T)
interactive=T:
인터렉티브 지도를 생성합니다.
지도 위에 올리면 추가 정보를 확인할 수 있습니다.
대한민국 시도별 인구, 결핵 환자 수 단계 구분도
install.packages('stringi')
stringi 패키지를 설치합니다.
한글 텍스트를 처리하기 위한 패키지입니다.
devtools::install_github('cardiomoon/kormaps2014')
kormaps2014 패키지를 GitHub에서 설치합니다.
대한민국 지도 데이터와 관련된 정보(인구, 결핵 환자 수 등)를 제공합니다.
library(kormaps2014)
kormaps2014 패키지를 로드합니다.
str(korpop1)
korpop1 데이터셋의 구조를 확인합니다.
이 데이터는 대한민국 시도별 인구 정보를 포함합니다.
library(dplyr)
데이터 전처리를 위해 dplyr 패키지를 로드합니다.
korpop1 <- rename(korpop1,
pop = 총인구명,
name = 행정구역별읍면동)
변수명을 pop(총인구)과 name(행정구역)으로 변경합니다.
대한민국 단계 구분도 생성
library(ggiraphExtra)
library(ggplot2)
ggChoropleth(data=korpop1,
aes(fill=pop,
map_id = code,
tooltip = name),
map=kormap1)
대한민국 시도별 인구 단계 구분도를 생성합니다.
data=korpop1: korpop1 데이터셋을 사용합니다.
aes(fill=pop, map_id=code, tooltip=name)
인구(pop)를 색깔로 표현하고, code로 지도를 매핑하며,
tooltip으로 행정구역 이름(name)을 표시합니다.
map=kormap1: 대한민국 시도별 지도를 사용합니다.
시도별 결핵 환자 수 단계 구분도 생성
str(tbc)
tbc 데이터셋의 구조를 확인합니다.
이 데이터는 대한민국 시도별 결핵 환자 수를 포함합니다.
ggChoropleth(data=tbc,
aes(fill=NewPts,
map_id = code,
tooltip = name),
map=kormap1,
interactive = T)
대한민국 시도별 결핵 환자 수를 단계 구분도로 시각화합니다.
data=tbc: tbc 데이터셋을 사용합니다.
aes(fill=NewPts, map_id=code, tooltip=name):
결핵 환자 수(NewPts)를 색깔로 표현하고,
code로 지도를 매핑하며,
tooltip으로 행정구역 이름(name)을 표시합니다.
interactive=T:
인터렉티브 지도 기능을 활성화하여
마우스로 지역별 데이터를 확인할 수 있습니다.
