국정원 트윗 텍스트 마이닝
국정원 계정 트윗 데이터
-> 국정원 대선 개입 사실이 밝혀져서 논란이 되었던
2013년 6월, 독립 언론 뉴스타파 인터넷을 통해 공개한 데이터
03:55
1. 데이터 로드
twitter <- read.csv('twitter.csv',
header = T,
stringsAsFactors = F,
fileEncoding = 'UTF-8')
'twitter.csv' 파일을 읽어와 twitter 데이터프레임으로 저장합니다.
데이터가 UTF-8 인코딩으로 되어 있으며,
첫 번째 줄은 헤더로 사용됩니다.
head(twitter, 5)
2. 변수명 수정
twitter <- rename(twitter,
no = 번호,
id = 계정이름,
date = 작성일,
tw = 내용)
rename():
twitter 데이터프레임의 변수명을 영어로 변경합니다.
번호는 no, 계정이름은 id, 작성일은 date, 내용은 tw로 수정합니다.
3. 특수문자 제거
twittertw, '\W',' ')
head(twitter$tw)
str_replace_all()
tw 열에서 특수문자('\W')를 공백으로 대체합니다.
head()
특수문자가 제거된 텍스트 데이터를 확인하기 위해 첫 5행을 출력합니다.
4. 단어 빈도표 생성
nouns <- extractNoun(twitter$tw)
extractNoun()
tw 열에서 명사를 추출하여 nouns 리스트에 저장합니다.
- 한글 텍스트에서 명사만을 추출하는 KoNLP 패키지의 기능
5. 추출한 명사 list 를 문자열 벡터로 변환, 단어별 빈도표
wordcount <- table(unlist(nouns))
wordcount
unlist()
리스트 형식의 명사 데이터를 벡터로 변환한다.
table()
명사별로 등장 빈도를 계산하여 wordcount 라는 빈도표를 생성한다.
6. 데이터 프레임으로 변환
df_word <- as.data.frame(wordcount, stringsAsFactors = F)
df_word
as.data.frame()
빈도표를 데이터프레임으로 변환하여 df_word에 저장합니다.
7. 변수명 수정
df_word <- rename(df_word,
word = Var1,
freq = Freq)
rename()
데이터프레임의 변수명을 수정합니다.
단어는 word, 빈도는 freq로 변경합니다.
8. 두 글자 이상으로 된 단어 추출, 빈도 기준 상위 20 추출
df_word <- filter(df_word, nchar(word) >= 2)
filter(): 두 글자 이상(word) >= 2)인 단어만 추출한다.
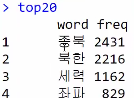
top20 <- df_word %>%
arrange(desc(freq)) %>%
head(20)
빈도를 기준으로 내림차순으로 정렬하고,
상위 20개의 단어를 추출하여 top20 데이터프레임에 저한다
top20
9. 워드 클라우드 생성
pal <- brewer.pal(9, 'Blues')[5:9]
Blues 팔레트에서 5번째부터 9번째까지의 색상을 사용하여 pal에 저장한다.
set.seed(1234)
난수를 고정하여 동일한 결과를 얻을 수 있도록 한다.
wordcloud(words = df_wordfreq,
min.freq = 10,
max.words = 200,
random.order = F,
rot.per = .1,
scale = c(11, 0.2),
colors = pal)
워드 클라우드를 생성한다.
단어는 df_word의 word를 사용한다.
단어 빈도에 따라 크기를 설정하고,
최소 10회 이상 등장한 단어만 포함하며, 최대 200개를 표시한다.
단어는 중앙에 고빈도 단어가 배치되며,
회전 비율은 10%, 크기 범위는 11에서 0.2까지로 한다.
pal 색상 팔레트를 사용해 단어 색상을 지정한다.

결과 분석
워드 클라우드
국정원 계정 트윗에서 많이 사용된 단어들이 중심에 크게 나타나며,
빈도가 낮은 단어들은 작게 표시됩니다.
워드 클라우드는 블루 계열의 색상을 사용해 시각적으로 강조됩니다.
상위 20개 단어
워드 클라우드에서 가장 빈도가 높은 20개의 단어가 크고
중앙에 배치되어 주요 키워드를 파악할 수 있습니다.
