데이터프레임 검토
- 라이브러리 불러오기
판다스, 넘파이, yfinance, matplotlib.pyplot
import pandas as pd
import numpy as np
import yfinance as yf
import matplotlib.pyplot as plt- 옵션 설정
pd.options.display.float_format = '{:.4f}'.format
판다스 데이터프레임을 출력할 때, 부동 소수점 숫자의 형식을 설정한다.
여기서는 소수점 이하 4자리까지 표시하도록 설정한다.
예를 들어, 3.14159265는 3.1416으로 표시된다.
plt.style.use('seaborn')
맷플롯립의 스타일을 'seaborn'으로 설정한다.
pd.options.display.float_format = '{:.4f}'.format
plt.style.use('seaborn')- 가져올 데이터 기간 설정
start = '2020-01-01'
end = '2024-07-02'- 가져올 티커 심볼 설정
symbol = ['NVDA','005930.KS', 'TSM']
df = yf.download(symbol, start, end)symbol = ['NVDA','005930.KS', 'TSM']
주식 티커 심볼의 리스트를 설정한다.
'NVDA'는 엔비디아,
'005930.KS'는 삼성전자,
'TSM'은 Taiwan Semiconductor Manufacturing Company(TSM)의 티커 심볼이다.
df = yf.download(symbol, start, end)
지정된 티커 심볼에 대해 특정 기간 동안의 주식 데이터를
Yahoo Finance에서 다운로드하여 데이터프레임에 저장한다.
예를 들어, start와 end를 '2022-01-01'과 '2022-12-31'로 설정하면,
2022년 한 해 동안의 Nvidia, 삼성전자, TSM의 주식 데이터를 가져온다
- 데이터프레임 확인
df.head()데이터프레임의 각 열은 각 주식의 다양한 속성(가격, 조정종가, 종가, 고가, 저가, 거래량 등)을 나타내며, 인덱스는 날짜이다.
각 행은 특정 날짜의 주식 데이터를 나타낸다.
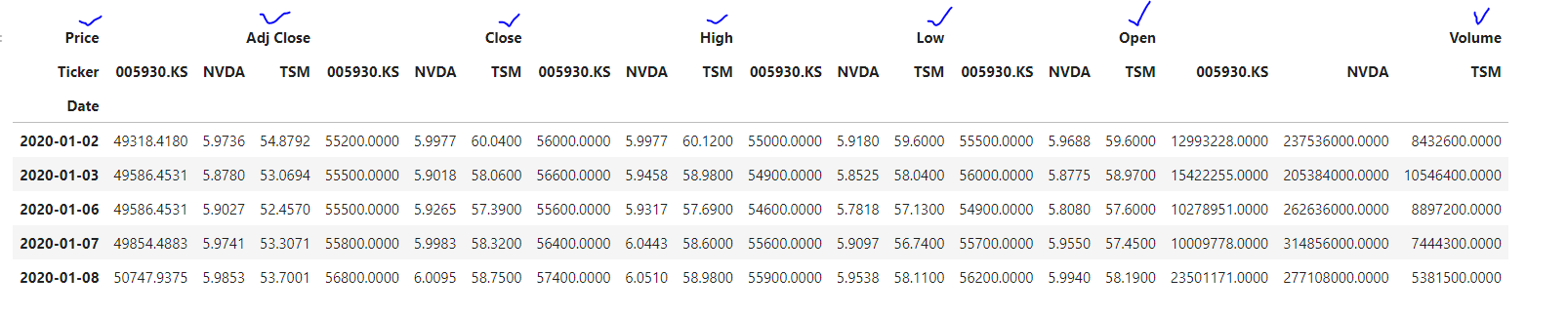
종가의 헤드를 조회한다.
df.Close.head()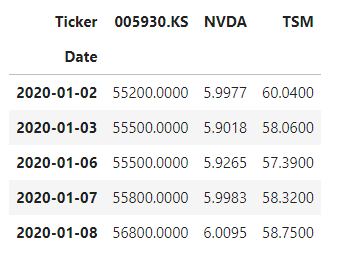
데이터프레임의 종가를 'close'에 담는다.
close = df.Close
close.head(2)
close.head(10)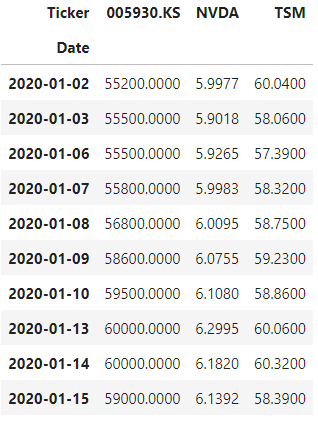
iloc 활용한 데이터 선택
행과 열의 좌표를 나타내는 기본 형식: [행, 열]
예를 들어 [0,0]은 첫 번째 행과 첫 번째 열에 있는 데이터를 의미한다.
즉, 55,200이라는 값을 선택하는 것이다.
콜론(:)의 사용
-
콜론만 사용하면 전체를 의미한다.
[:]는 모든 행 또는 모든 열을 선택하는 것이다. -
숫자 뒤에 콜론이 오면, 그 숫자부터 끝까지 선택한다.
[0,1:]은 첫 번째 행의 두 번째 열부터 마지막 열까지 선택하는 것이다. -
콜론이 숫자 앞에 오면, 처음부터 그 숫자까지 선택한다.
[0,:2]은 첫 번째 행의 첫 번째 열부터 두 번째 열까지 선택하는 것이다.
예제
close.iloc[0,:3]
첫 번째 행의 첫 번째 열부터 세 번째 열까지의 데이터를 선택한다.
--> 첫 번째 행의 처음 세 개 열의 값을 반환한다.
close.iloc[0]은 첫 번째 행의 모든 열을 선택한다.
--> 첫 번째 행의 모든 값을 반환한다.
- 데이터 정규화
norm = close.div(close.iloc[0]).mul(100)
norm
close 데이터프레임의 주식 가격 데이터를 기준 날짜의 주식 가격에 대한 백분율로 정규화한 새로운 데이터프레임 norm을 생성한다.
close.iloc[0]
close 데이터프레임의 첫 번째 행을 선택한다.
이는 기준이 되는 날짜의 주식 가격 데이터를 의미한다.
close.div(close.iloc[0])
close 데이터프레임의 각 값을 첫 번째 행의 값으로 나눈다.
이를 통해 각 주식 가격을 기준 날짜의 주식 가격에 대한 비율로 변환한다.
close 데이터프레임의 첫 번째 행의 값이 100이고, 두 번째 행의 값이 110이라면,
이 비율은 1.1 (110 / 100)이다.
.mul(100)
위에서 계산된 비율에 100을 곱한다.
( 비율이 1.1인 경우, 1.1 * 100 = 110% 가 된다. )
norm = close.div(close.iloc[0]).mul(100)
- 그래프 그리기
norm.dropna().plot(figsize = (20, 15), fontsize = 13, logy = True)
plt.legend(loc = 'upper left', fontsize = 15)
plt.show()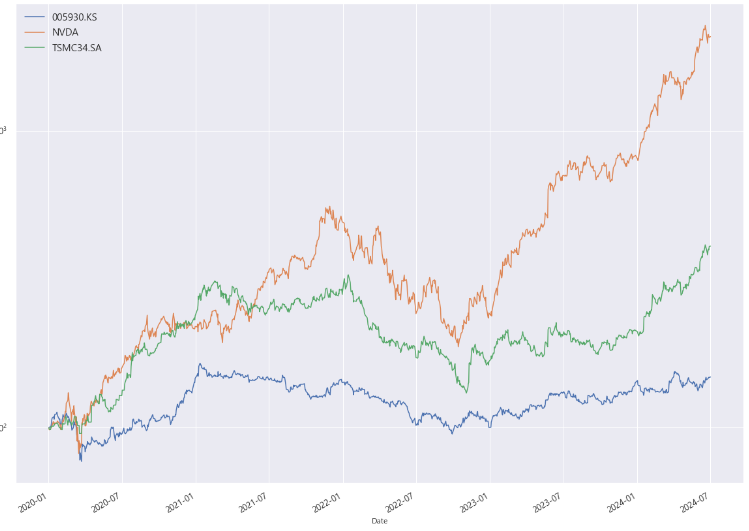
norm.dropna().plot(figsize = (20, 15), fontsize = 13, logy = True)
norm.dropna()는 NaN 값을 제거한 정규화된 데이터프레임을 반환한다.
figsize = (20, 15)는 그래프의 크기를 설정한다.
가로 20인치, 세로 15인치 크기의 그래프를 생성한다.
fontsize = 13은 그래프의 글꼴 크기를 설정한다.
logy = True는 y축을 로그 스케일로 설정한다.
로그 스케일을 사용하면 데이터의 변화를 더 명확하게 비교할 수 있다.
특히 주식 가격의 큰 변화를 시각화할 때 유용하다!
plt.legend(loc = 'upper left', fontsize = 15)
범례를 그래프의 왼쪽 위에 배치하고, 글꼴 크기를 15로 설정한다.
plt.show()
그래프를 화면에 출력한다.
- 그래프 해석
이 그래프는 2020년 1월부터 2024년 7월까지의 기간 동안
엔비디아, 삼성전자(005930.KS), TSM의 주식 가격 변화를 로그 스케일로 시각화한 것이다.
로그 스케일을 사용함으로써 주식 가격의 비율 변화를 명확하게 볼 수 있으며, 이로 인해 주식 가격이 몇 배로 증가했는지를 쉽게 파악할 수 있다.
