
learning rate가 클 경우, 경사면을 따라 내려가는 스텝이 크면 왔다 갔다 이동하게 되고, 함수 바깥으로 튀어나갈 수 있다. 이것을 오버슈팅이라고 부름.
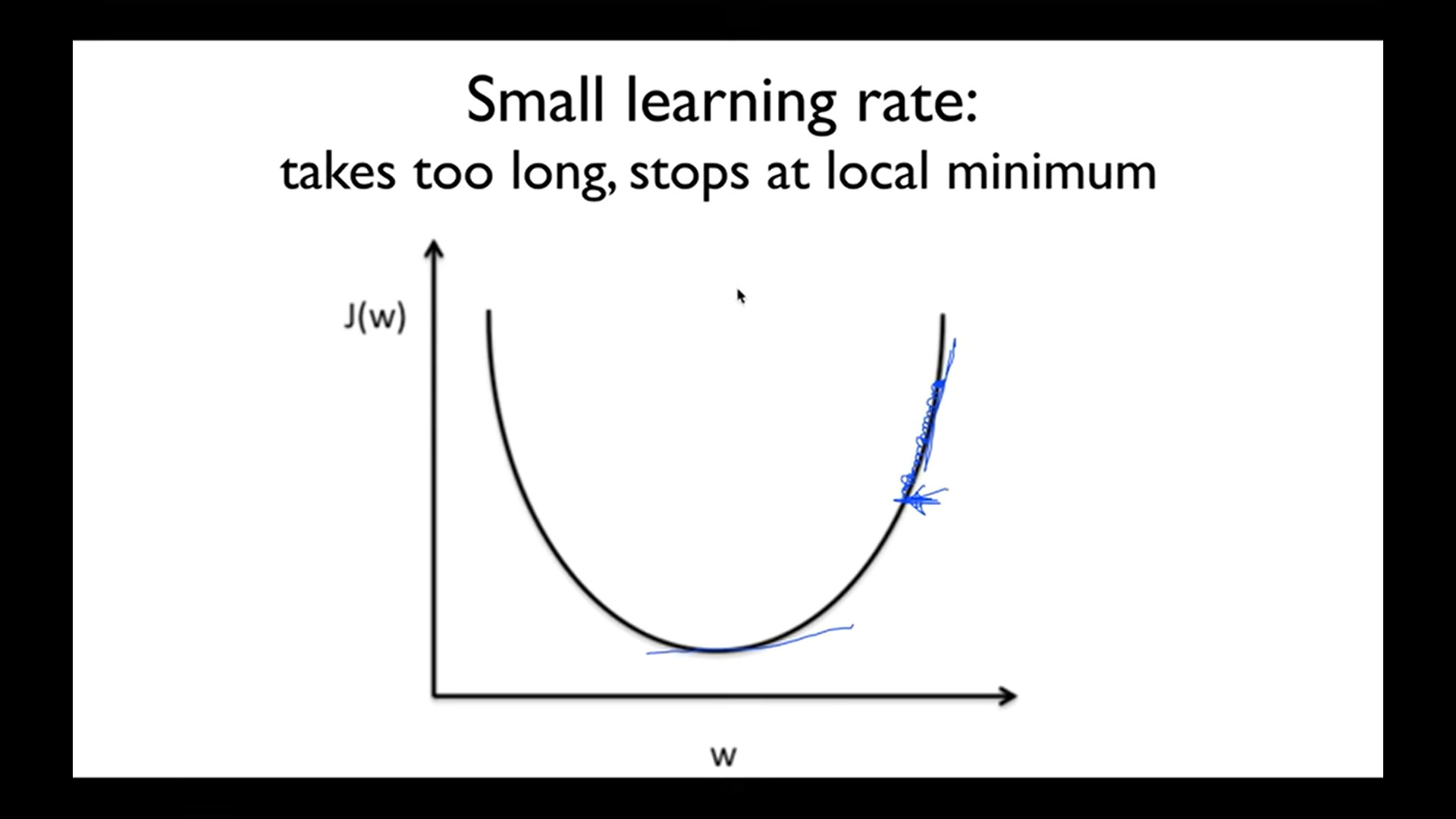
경사면을 아주 조금씩 내려가게 되면 시간이 오래걸림. (해질 때까지도 하산하지 못하는 것에 비유) 최저점이 아닌 곳에서 멈출 가능성이 있음.
- Learning rates 정하기
명확한 정답은 없음. 0.01로 두고 관찰하면서 너무 큰 것같음 줄이고, 반대로 너무 작은 것 같으면 크게 마들면 된다.
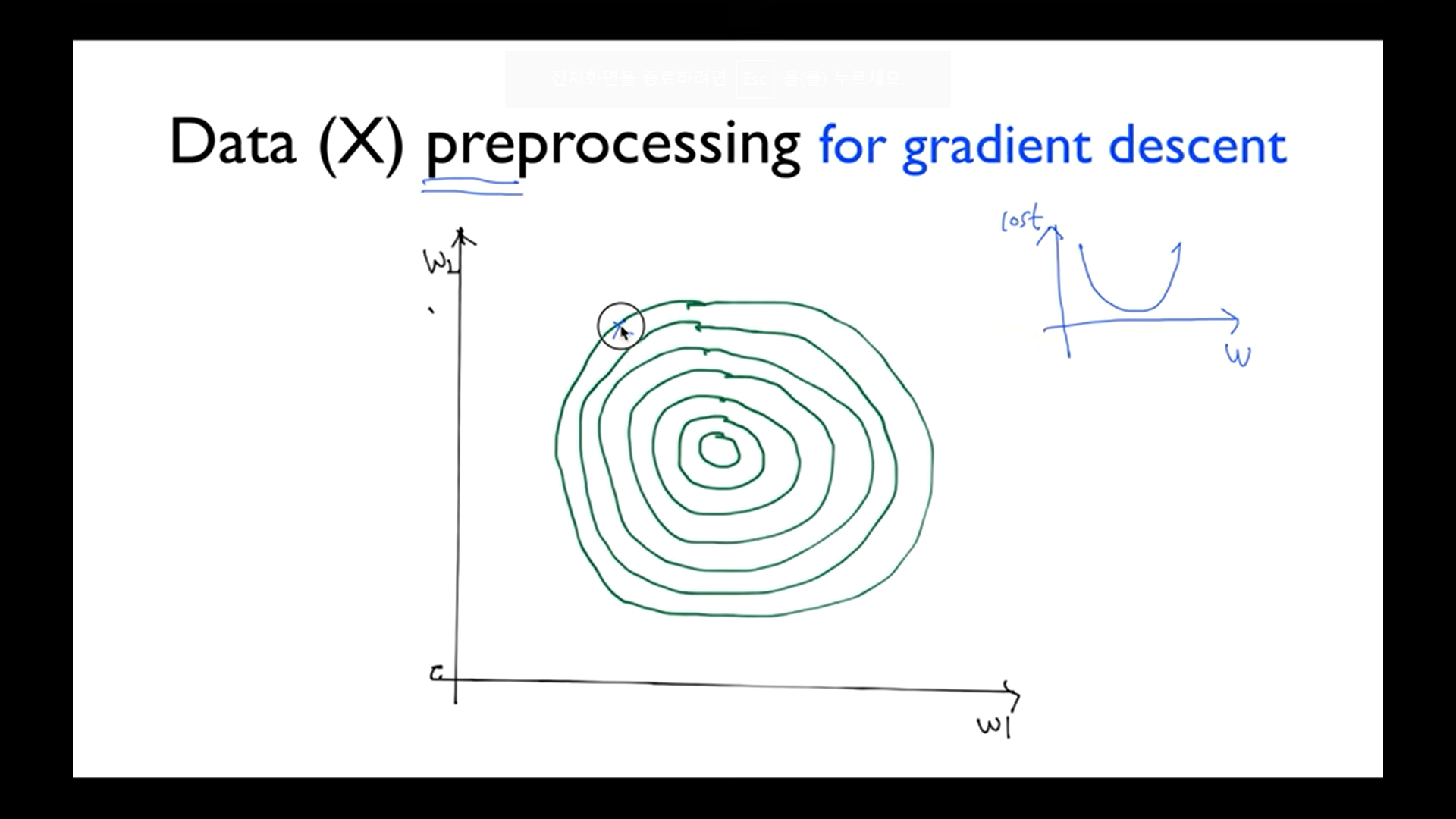
가장 높은 지점에서 낮은 지점으로 내려감 (바깥쪽 원 부분에서 안쪽으로)
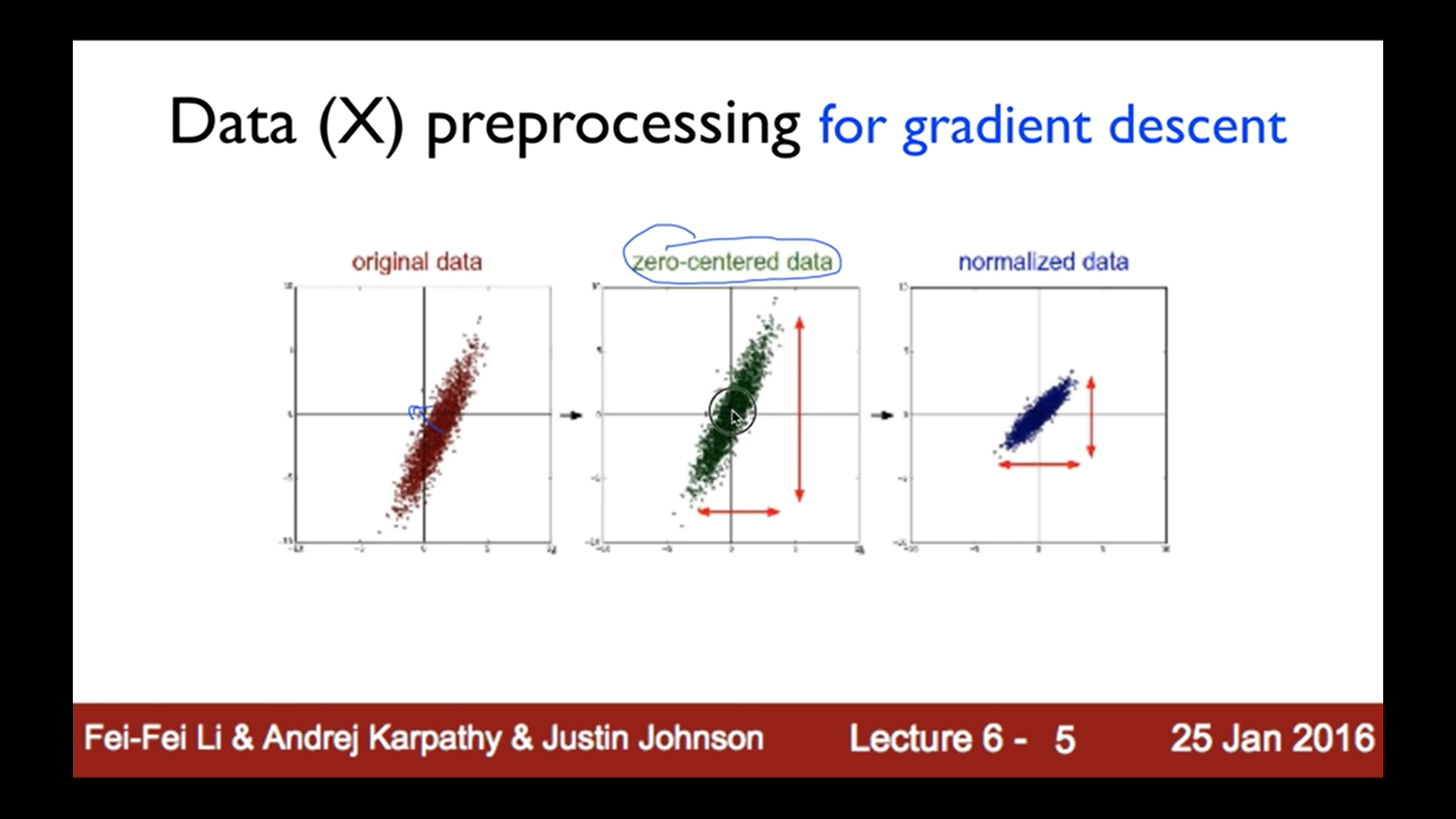
데이터 차이가 크면 표준화하는 과정이 필요함.

값에서 평균을 뺀 것을 표준편차로 나눠주면 됨. 이 과정은 파이썬에서
X_std[:,0] = (X[:,0] - X[:,0].mean()) / X[:,0].std()이렇게 입력해주면 됨!
-
Overfitting
우리의 모델은 학습 데이터에 아주 잘 맞지만, 테스트 데이터나 실사용에서는 잘 안 맞을 수 있음
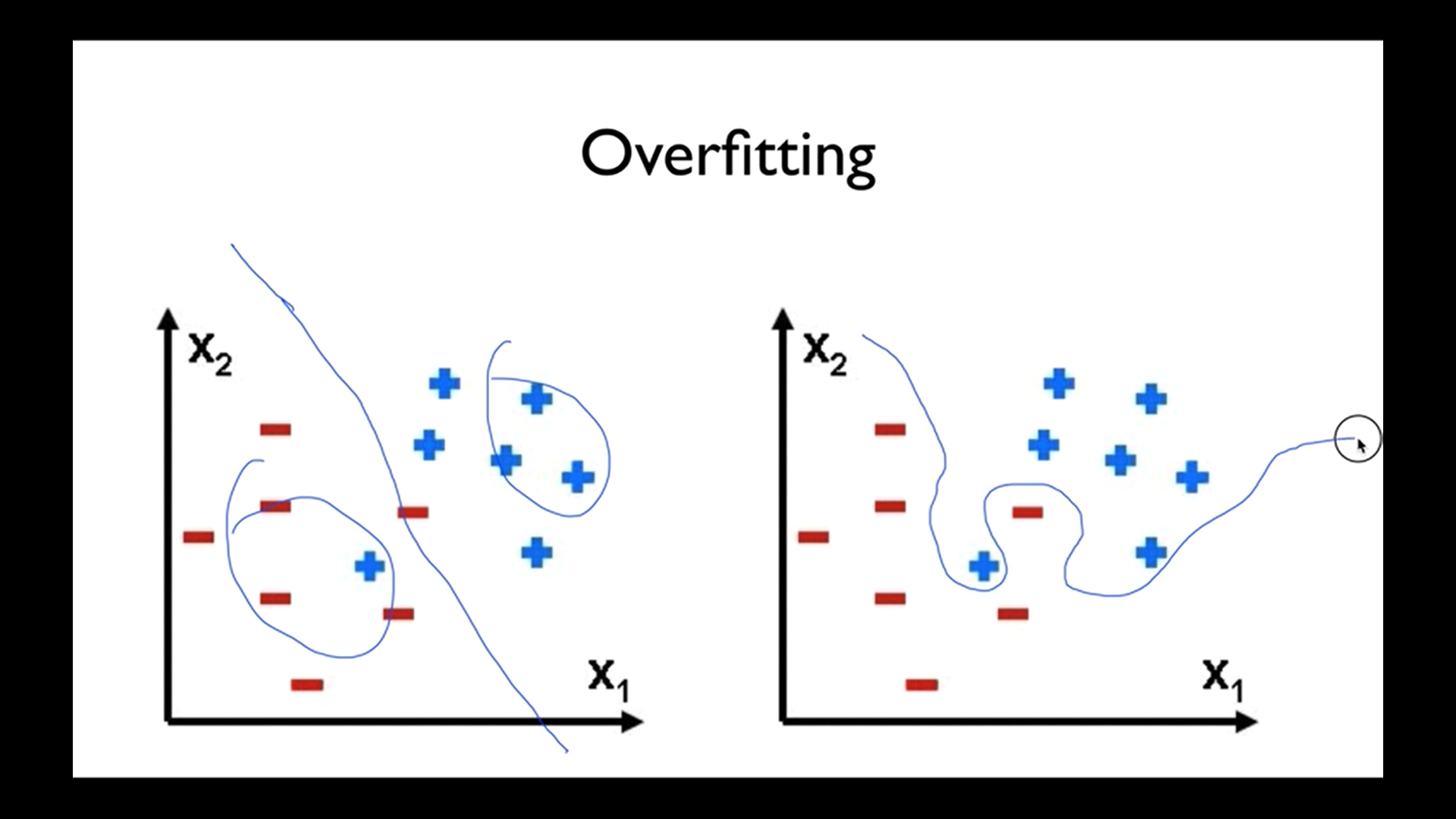
왼쪽과 오른쪽을 비교했을 때 왼쪽 것이 더 좋음. 오른쪽 것은 너무 데이터에만 치중함. 여기엔 잘 맞지만 실제로 사용했을 때 정확도가 떨어질 수 있다. 이렇게 되어있는 모델이 바로 오버피팅이다. -
Overfitting 해결법
학습 데이터가 많을 수록 좋고, 피쳐의 개수를 줄이기, Regularization(일반화)

각각의 element를 제곱해서 더해주고 앞에 상수를 곱해줌. 그 상수가 0이면 regularzation을 안 더해주겠다, 크면 중요하게 생각하겠다는 의미.
l2reg = 0.001*tf.reduce_sum(tf.square(W))로 표현할 수 있음.

공부한 거 정리하는 용도로 씁니다.