🚩 심화주차 아웃소싱 프로젝트 완성
이번 팀 프로젝트로는 카카오 맵 API를 메인으로 한 캠핑장 정보 제공 사이트를 제작했다.
완성된 프로젝트의 배포 링크나 기획 등은 위에 연결해둔 깃허브를 통해 확인이 가능하다.
블로그에서는 내가 담당했던 Youtube API를 사용해서 캠핑 관련 영상들을 모아둔 가이드 페이지에 대해 작성해보려고 한다.
Youtube API
유튜브에서는 각종 영상과 채널에 관련한 데이터를 API로 제공하고 있다.
💥 사소한 트러블 슈팅
가이드가 친절하게 나와있어서 순서대로 API키를 발급받고 환경변수로 설정하여 영상을 요청해봤는데 403 forbidden 에러가 떴다.
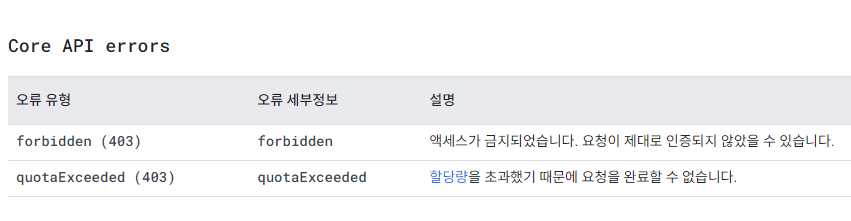
가이드 페이지에 나와있는 오류 메세지에서 403 코드는 두 가지 경우가 있고, 나는 forbidden 이니까 api키가 연결이 안 되고 있는 것 같았다. import도 잘 했는데 뭐가 문제인가 싶어 먼저 KAKAO MAP API를 연결한 팀원분의 환경변수 이름이랑 import 부분을 살펴봤는데
VITE_KAKAO_API_KEY = 키
YOUTUBE_API_KEY = 키이렇게 되어 있길래 앞에 똑같이 'VITE_'를 추가했더니 해결되었다.
🖥️ 특정 키워드로 검색한 영상 목록 받기 / Search 사용하기
API 공식 페이지에서 참고자료 - 검색 - list 페이지에 들어가면 오른쪽에 API 탐색기가 뜬다.
전체화면 버튼을 누르면 이런식으로 어떻게 요청을 보내는지 볼 수 있는 창이 뜨는데 나한테는.. 별 도움은 안 됐다.
나는 이 블로그에서 도움을 많이 받았다.
const params = {
part: "snippet",
q: searchKeyword,
maxResults: 15,
type: "video",
regionCode: "KR",
key: YOUTUBE_API_KEY
};
const getYoutubeData = async () => {
const response = await axios.get(
"https://www.googleapis.com/youtube/v3/search",
{ params }
);
return response.data.items;
};원래는 쿼리 스트링으로 검색 조건을 받는데, axios에서는 쿼리 파라미터를 추가하는 params 옵션이 있기 때문에 이게 보기 더 편할 것 같아서 분리해서 작성했다.
params
- part : 필수 매개변수, id 혹은 snippet을 문자열로 지정해야한다.
- q : 검색어. (나는 카테고리별 검색어를 쿼리스트링으로 받고 있기 때문에 변수로 지정했다)
- maxResults : 결과 집합에 반환해야 하는 최대 항목 수. 기본값은 5, 최소 0부터 최대 50까지
- type : 선택한 유형의 검색 결과만 반환. channel, playlist, video 중에서 선택
- regionCode : 지정된 국가에서 볼 수 있는 동영상의 검색결과를 반환
- key : 발급받은 API KEY
그 외 추가적인 옵션은 API 문서에서 볼 수 있다! 설명도 친절하게 적혀 있음.
이렇게 요청한 데이터는
{
"kind": "youtube#searchListResponse",
"etag": etag,
"nextPageToken": string,
"prevPageToken": string,
"regionCode": string,
"pageInfo": {
"totalResults": integer,
"resultsPerPage": integer
},
"items": [
search Resource
]
}이런 형태로 반환된다. 실질적으로 내가 사용할 정보들은 받아온 비디오들의 정보였기 때문에 items만 추출하여 반환했다.
그리고 그 각각의 비디오 items는 이렇게 반환된다.
{
"kind": "youtube#searchResult",
"etag": etag,
"id": {
"kind": string,
"videoId": string,
"channelId": string,
"playlistId": string
},
"snippet": {
"publishedAt": datetime,
"channelId": string,
"title": string,
"description": string,
"thumbnails": {
(key): {
"url": string,
"width": unsigned integer,
"height": unsigned integer
}
},
"channelTitle": string,
"liveBroadcastContent": string
}
}처음엔 바로 items를 받아서 썼는데, 불필요한 데이터가 너무 많아 콘솔 찍을 때마다 헷갈리고 굳이 안 쓰는 정보까지 들어간 값을 쓸 이유가 없어서 사용할 정보만 추려낸 비디오 정보들을 videos 라는 새 배열로 만들었다.
const videos = data?.map((video) => ({
videoId: video.id.videoId,
...video.snippet
}));🖥️ useQuery 사용하여 API 요청 조금이라도 줄이기
Youtube API는 하루에 사용할 수 있는 일일 할당량이 존재한다. 기본 값은 10,000 그리고 search의 경우 요청 한 번에 100의 할당량을 사용한다. 만약 한 명의 사용자가 바베큐 가이드 봤다가 텐트 가이드 봤다가 다시 바베큐 가이드 봤다가 캠핑 입문 가이드 페이지를 보게되면 벌써 400의 비용이 발생하는 것이었다.
물론 useQuery 또한 캐시 데이터에 저장하는 것이라 새로고침을 하거나 페이지를 아예 껐다가 다시 들어올 경우 최초 요청 한 번은 계속 발생하겠지만, staleTime과 cacheTime을 설정함으로써 이런 부분을 조금이라도 해결하고 싶었다.
const { data, isLoading, isError, isPending } = useQuery({
queryKey: ["youtube", searchKeyword],
queryFn: getYoutubeData,
staleTime: 1000 * 60 * 60 * 12, // 할당량 최적화를 위해 12시간 동안 유지
cacheTime: 1000 * 60 * 60 * 12,
enabled: !!searchKeyword && searchKeyword.trim() !== "", // 검색어가 있을 때만 쿼리 실행
refetchOnWindowFocus: false, // 포커스 변경 시 재요청 방지
refetchOnReconnect: false, // 네트워크 재연결 시 재요청 방지
retry: 1
});검색어의 경우 카테고리를 선택하면 카테고리에 해당하는 검색어를 쿼리스트링으로 보내고 있기 때문에 거기서 따온 키워드를 쿼리 키로도 사용했다. 중복되지 않고, 카테고리마다 다른 캐시 데이터를 유지할테니까...
✅ 프로젝트를 마치며
사실 이 프로젝트 전까지 useQuery랑 axios가 어떻게 써야하는 건지? 조금 헷갈렸는데 youtube API를 사용하면서 이것저것 검색해보고, 직접 설정해보니 바로 이해가 됐다. youtube API도 생각보다 사용하기 너무 쉬웠다. 다음 프로젝트때 또 써보고 싶을 만큼... 다만 로직 자체를 작성하는 건 잘한 것 같은데 컴포넌트 내부에서 작성한 함수를 분리하거나 API 요청 최적화 등의 리팩토링을 하지 못해서 이 부분에 크게 아쉬움이 남는다. 함수 분리하는 게 제일 어렵다...🥹
