객체 연관관계 UML

Writer 객체는 여러 개의 DiabetesDiary(혈당 일지) 객체를 리스트 형태로 보유한다.
Writer→DiabetesDiary 로만 단방향 참조가 일어난다. DiabetesDiary에서 Writer를 참조할 필요가 없어보인다.
DiabetesDiary 객체는 Diet(식단) 객체를 리스트 형태로 보유한다. 이 역시 Diet에서 DiabetesDiary로 참조할 이유가 굳이 없어보여 단방향 참조로 정했다.
Diet(식단) 객체는 Food 객체를 리스트 형태로 보유한다. 여기서는 양방향 참조로 정했다. 왜냐하면 '음식'의 경우 거꾸로 '식단'의 혈당을 참조할 필요가 있어 보였기 때문이다.
Writer 객체를 보면, ListfoodList 이라는 자신이 먹은 음식에 관한 리스트가 있다. 이 리스트는 Food 객체들에 대한 '참조'를 담고 있다. (이름을 저장하는 것이 아니기 때문에 Set으로 만들지 않았다.)
Writer는 foodList와 해시 테이블(또는 딕셔너리)를 활용하여 음식별 혈당을 알아낼 수 있을 것이다.
단, 이 방식의 문제점은 혈당 일지 하나 당 작성되는 음식의 양이 많기 때문에 foodList가 비대해질 가능성이 크다는 것이다. 나중에 최적화할 필요가 있어 보인다.
DB ERD
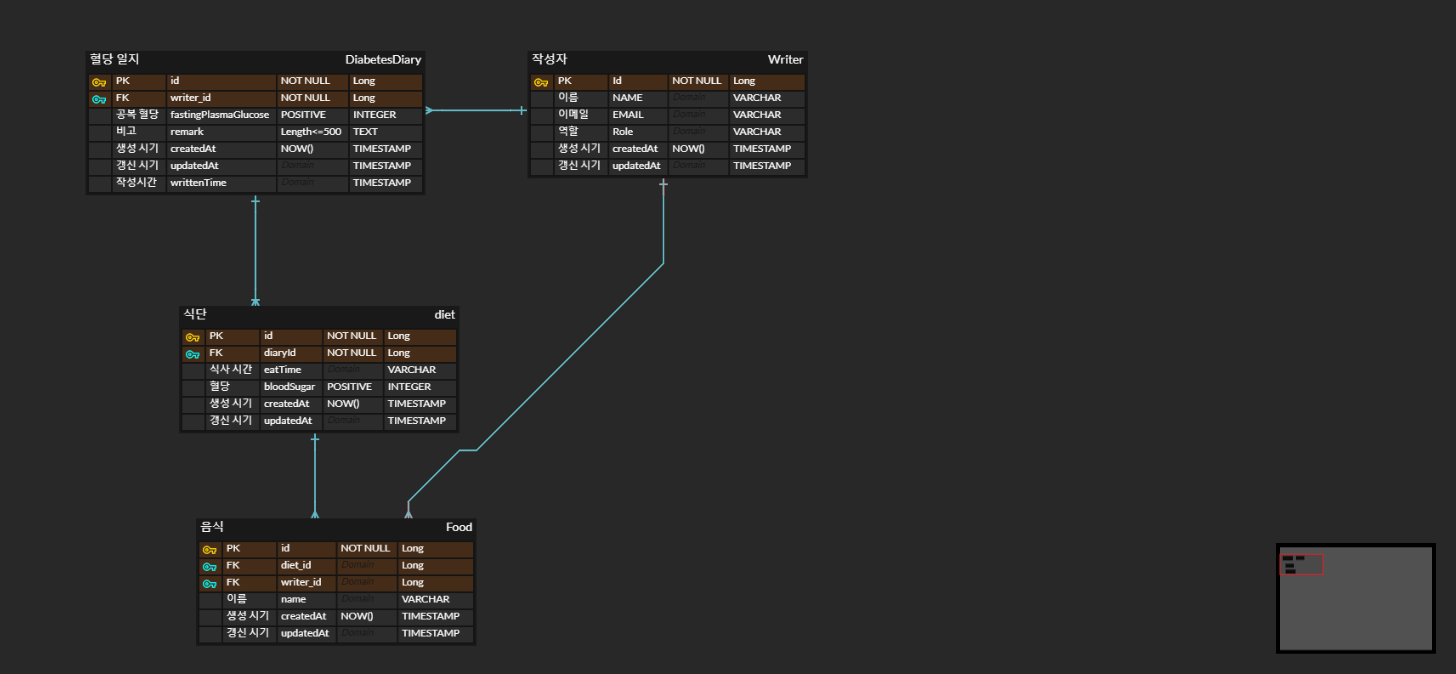
JPA 엔티티 다대일 양방향 매핑으로 변경
객체 연관관계 UML의 UML을 보면, DiabetesDiary 엔티티와 Diet 엔티티는 1:N 단방향 관계를 맺고 있다.
일대다 단방향은 외래키가 없는 "일" 엔티티가 "다"의 외래키를 관리해야 한다는 단점을 갖고 있다.
이러한 경우에는 연관 관계 처리를 위해 update Sql이 추가적으로 실행되야 하는 비용이 존재한다. 해결책으로는 다대일 양방향 매핑을 사용하는 것이다.
이렇게 하면 관리해야 하는 외래키가 "다"쪽 엔티티에 존재하게 되므로 추가 비용이 발생하지 않는다.
Writer → DiabetesDiary와 Writer→Food 에도 일대다 단방향이다. 따라서 다대일 양방향 매핑으로 변경한다.
UML 및 ERD 수정
작성자 -> 음식 연관 관계를 삭제하였다. 이유는 다음과 같다.
작성자의 음식 컬렉션에서 음식 엔티티를 삭제해도 식단의 음식 엔티티를 조회해보면, 음식 엔티티에 작성자 정보가 남아 있다.
이유는 아직 알 수 없지만, db 설계랑 맞지 않으므로 연관 관계를 삭제한다.
db 설계랑 맞으려면, 작성자에서 음식 엔티티를 제거하면 db 내에서는 음식 튜플의 작성자에 대한 외래키가 null이 되야 한다.

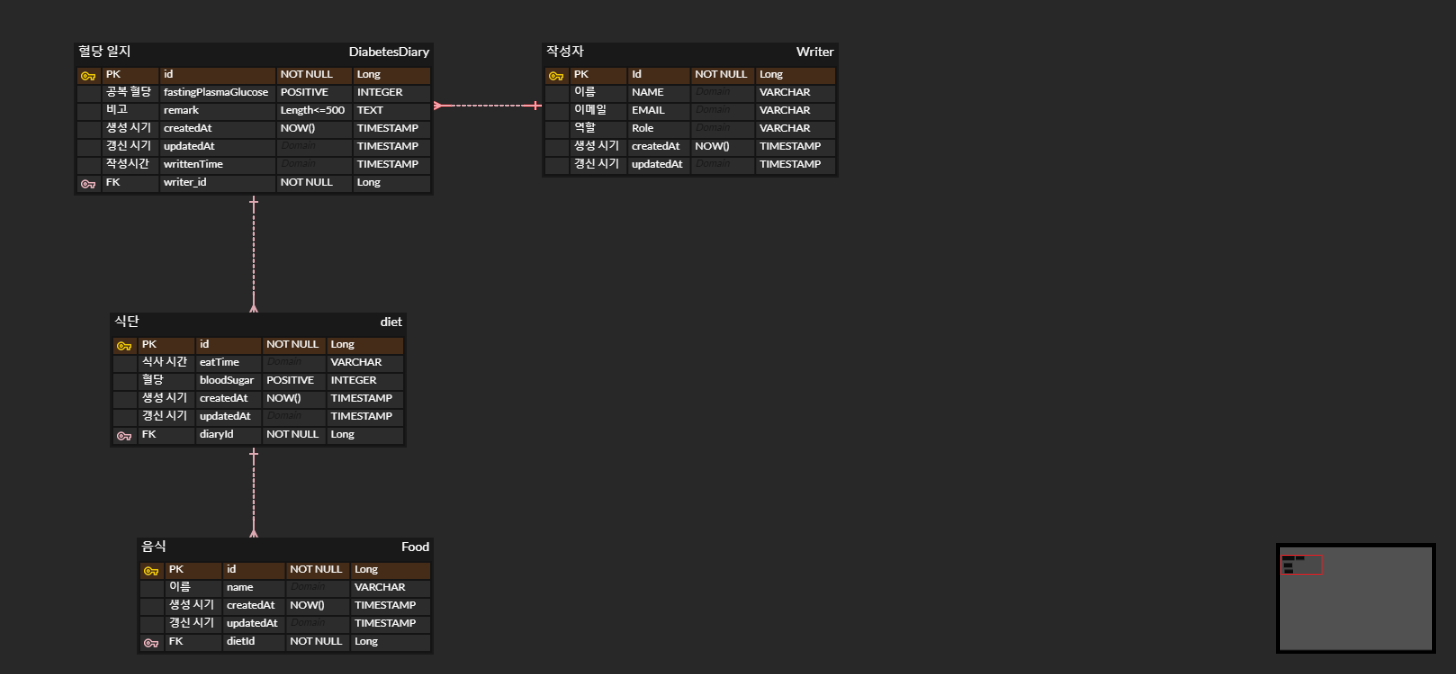
이렇게 하면 작성자가 먹은 음식을 알고 싶을 경우, 조인(내부 조인)이 너무 많아지는 문제가 발생한다.
UML 및 ERD 수정 2차 (식별관계로 수정)
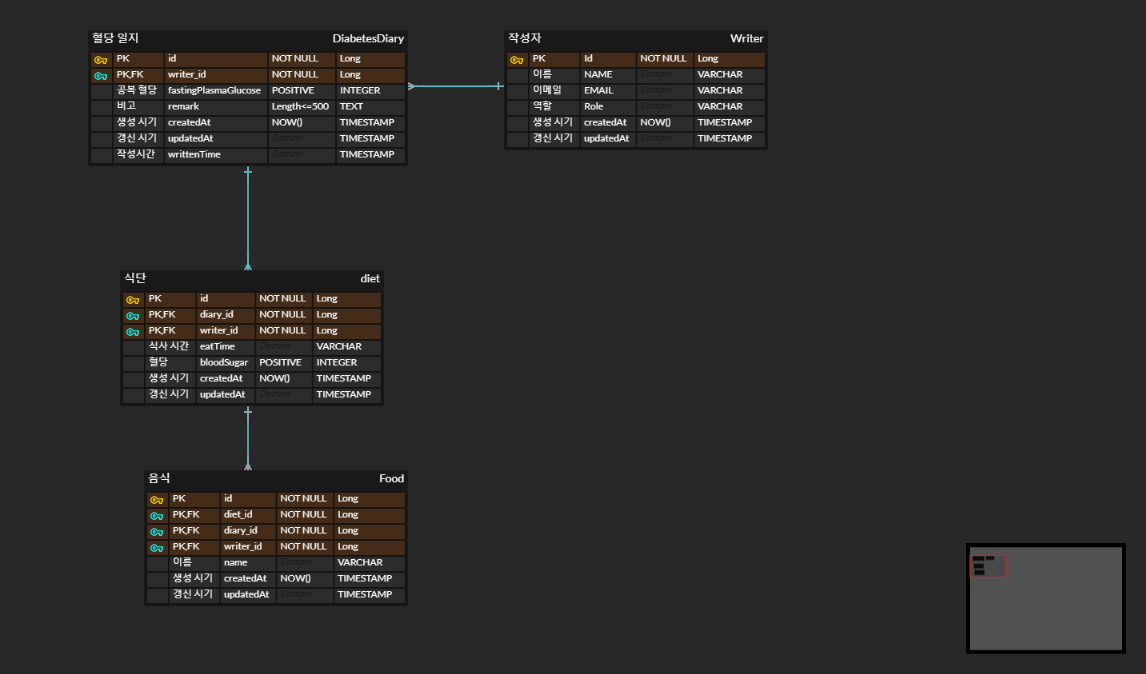
이 문제를 해결하기 위해 "비식별 관계" → "식별 관계"로 바꿨다. (대부분의 설계의 경우 비식별 관계가 추천되긴 한다.)
식별관계로 바꾸면, 요구사항이 바꿀 경우 유연하게 구조를 바꾸기 어렵다. 왜냐하면 기본키를 자식 테이블들이 계속 물려받기 때문이다.
위 그림에서 식별관계를 사용하면 음식 테이블은 복합키의 구성이 무려 4개가 된다.
하지만, 위 다이어그램의 테이블들은 모두 상위 테이블이 "반드시" 존재해야만 하위 테이블이 존재할 수 있는 관계이다.
(작성자가 없으면 혈당 일지가 있을 수 없다. 혈당 일지가 없으면 식단이 있을 수 없다. 식단이 없으면 식단에 적은 음식이 있을 수 없다.)
그리고 비즈니스 로직을 짜려고 하니 음식, 식단, 일지와 관련된 로직에서 "작성자"가 누구인가가 중요함을 알게 되었다.
음식, 식단과 관련된 로직에서도 "일지"와 "작성자"가 어떤 것인지가 중요하다. (비식별이면 조인을 여러번 해야 한다.)
따라서 대부분의 경우 비식별 관계가 추천되긴 하지만, 혈당일지 테이블 설계에는 식별관계가 더 적합하다고 생각해서 식별관계로 바꿧다.
QueryDSL 적용 후 발생한 문제 및 해결
먼저, QueryDSL은 명시적으로 join (innerJoin(), leftJoin() 등..)을 작성하지 않으면 크로스 조인이 발생한다.
크로스 조인은 모든 경우의 수를 나타내므로 성능 상 좋지 않다. 따라서 join을 명시적으로 작성하는 게 좋다.
해결책
그래서 아래 코드처럼 innerJoin()을 명시적으로 작성해서 위 문제를 해결하였다.
@Override
public List<Food> findFoodsInDiet(Long writerId, Long dietId) {
// @Query(value = "SELECT food FROM Food as food WHERE food.diet.diary.writer.writerId = :writer_id AND food.diet.diary.diaryId = :diaryId AND food.diet.dietId = :diet_id")
return jpaQueryFactory.selectFrom(QFood.food)
.innerJoin(QFood.food.diet, QDiet.diet)
.on(QDiet.diet.diary.writer.writerId.eq(writerId).and(QDiet.diet.dietId.eq(dietId)))
.fetch();
}Hibernate: select food0_.diary_id as diary_id0_2_, food0_.writer_id as writer_i0_2_, food0_.diet_id as diet_id0_2_, food0_.food_id as food_id1_2_, food0_.diary_id as diary_id3_2_, food0_.writer_id as writer_i4_2_, food0_.diet_id as diet_id5_2_, food0_.food_name as food_nam2_2_
from food food0_
inner join (diet diet1_
inner join diabetes_diary diabetesdi2_
on diet1_.diary_id=diabetesdi2_.diary_id and diet1_.writer_id=diabetesdi2_.writer_id)
on food0_.diary_id=diet1_.diary_id and food0_.writer_id=diet1_.writer_id and food0_.diet_id=diet1_.diet_id and (diabetesdi2_.writer_id=? and diet1_.diet_id=?)평가
대신 inner join이 2번 발생한다.
비식별 관계로 했을 때 내부조인이 3번 일어날 거라 예상했고, 지금 식별 관계에서 내부조인이 2번 일어났으므로 조인 연산이 줄어들기는 했다.
