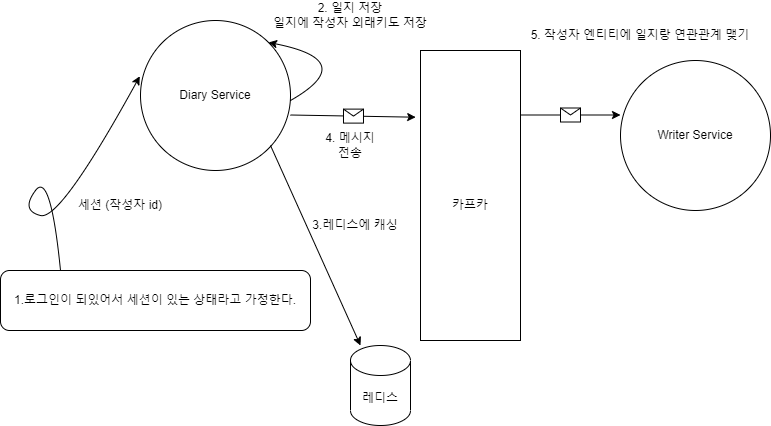
기존 시퀀스 다이어그램
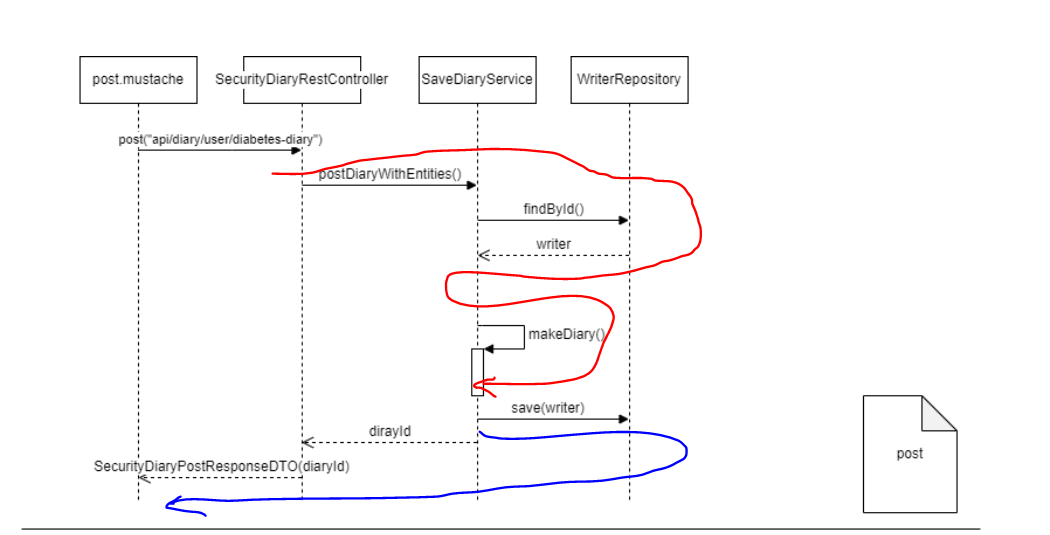
붉은 색 부분은 대략 구현하였고 파란색 부분을 마저 구현해야 한다.
물론, writer를 find 하기 전에 writer를 save 해야 하는 선행 작업이 필요하다. 그런데 이 작업은 spring security와 msa를 같이 고려해야 하므로 현 시점에선 진행하기 어렵다. 이는 세 번째 iteration 쯤에나 진행해야 겠다.
파란색에서 save(writer)는 Writer 엔티티 내의 DiaryId 리스트에 추가하는 요청으로 바뀔 것이다. 그리고 이 작업은 아파치 카프카를 이용할 예정이다. 왜냐하면 이 작업의 경우 작성자 서비스에서도 JPA 양방향 관계를 비스무리하게 구현하는 게 목적인데, 일지 서비스에서 makeDiary()를 하고 나서 곧바로 작성자 서비스에서 작업을 할 필요가 없기 때문이다.
비동기 통신을 이용하면 바로 당장은 데이터의 일관성은 보장할 수 없다고 한다.
그런데 최종적으로는 데이터가 일관되게 된다. (데이터 중심 애플리케이션 설계 164p 참고)
그리고 비동기 통신을 활용하면 일지 서비스가 작성자 서비스의 작업을 처리하는 것을 기다릴 필요 없이 다른 일을 하고 있어도 된다. 즉, 스레드 풀 내의 스레드 자원이 하염 없이 기다리고 있는 것을 방지할 수 있다. (반면, 동기 방식이면 일지 스레드가 작성자 서비스의 작업이 끝마치는 것을 계속 기다리고 있어야 한다! 물론 데이터의 일관성은 확실히 보장한다.)
레디스는 메모리에서 작동하는 캐시이다. 그리고 메모리 조회는 디스크 조회보다 훨씬 빠르다.
내 생각에 방금 작성한 일지는 곧바로 조회할 확률이 클 것 같다.
그래서 makeDiary()에서 레디스를 사용할 것이다.
물론 이 작업이 실제로 쓸모 있을 지는 실제 성능 측정이 필요할 거다.
그리고 updateDiary()나 deleteDiary()가 발생하면 레디스 내 캐시도 무효화해야 하는 후처리도 필요할 것이다.
유한 상태 기계 다이어그램
FSM을 그려보니까 findById(writerId)가 굳이 필요한가 싶기도 하다. 해당 사항은 spring security를 구현하면서 생각해야겠다.
구현
회복성 패턴 추가
클라이언트 측 회복성 소프트웨어 패턴들은 에러나 성능 저하로 원격 자원이 실패할 때, 클라이언트가 고장 나지 않고 빨리 실패하게 하며 데이터 베이스 커넥션이나 스레드 풀 등의 자원 낭비를 방지할 수 있게 한다.
-스프링 마이크로 서비스 코딩 공작소 247p
의존성 추가하기
<!-- resilience -->
<dependency>
<groupId>io.github.resilience4j</groupId>
<artifactId>resilience4j-spring-boot2</artifactId>
<version>${resilience4j.version}</version>
</dependency>
<dependency>
<groupId>io.github.resilience4j</groupId>
<artifactId>resilience4j-circuitbreaker</artifactId>
<version>${resilience4j.version}</version>
</dependency>
<dependency>
<groupId>io.github.resilience4j</groupId>
<artifactId>resilience4j-timelimiter</artifactId>
<version>${resilience4j.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>속도 제한기 패턴 추가하기
일지 저장은 주어진 시간 동안 총 호출 수가 제한될 필요가 있다고 판단해서 속도 제한기 패턴을 넣었다. 한 순간에 저장을 많이 누를 이유도 없고, 오히려 그러한 행위는 서버만 피곤하게 할 것이기 때문이다.
일지 서비스 bootstrap.yml
resilience4j:
ratelimiter:
instances:
diaryService:
timeOutDuration: 1000ms
limitRefreshPeriod: 1000
limitForPeriod: 1일지 서비스에 어노테이션 부착
@RateLimiter(name="diaryService")
public Long postDiaryWithEntities(SecurityDiaryPostRequestDTO dto) {
logger.info("post diary in diary service");
logger.info("call writer micro service for finding writer id...");
Long writerId=findWriterFeignClient.findWriterById(dto.getWriterId());
logger.info("saving diary...");
DiabetesDiary diary = new DiabetesDiary(writerId, dto.getFastingPlasmaGlucose(), dto.getRemark());
diaryRepository.save(diary);
return diary.getId();
}회로 차단기와 폴백 패턴 추가하기
특정 마이크로 서비스가 원격 자원 호출할 때, 너무 많은 시간을 소요하면 사용자에게 짜증을 선사하며 스레드풀도 낭비시킨다. 그래서 회로 차단기를 활용해 빨리 실패시키고 폴백으로 지정된 메서드 결과를 리턴해준다.
작성자 서비스 호출에 회로 차단기 추가하기
@FeignClient("writer-service")
public interface FindWriterFeignClient {
@CircuitBreaker(name="writerService")
@RequestMapping(method= RequestMethod.GET,value="/writer/{writerId}",consumes = "application/json")
Long findWriterById(@PathVariable("writerId")Long writerId) throws TimeoutException;
}원래는 일지 서비스 -> 작성자 서비스로 직접 호출이였다. 그러나 회로 차단기 어노테이션을 추가함으로써 일지 서비스 -> 회로 차단기 -> 작성자 서비스로 변경되었다. 회로 차단기는 중간에서 지켜보다가 어떤 문제가 발생하면 미리 설정해놓은 방식에 따라 처리를 실시한다.
throws TimeoutException을 명시함으로써 시간이 오래 걸릴 경우 클라이언트 메서드에 예외를 전파한다.
일지 서비스에서 DB 호출할 때 회로 차단기 및 폴백 추가하기
@RateLimiter(name="diaryService")
public Long postDiaryWithEntities(SecurityDiaryPostRequestDTO dto) throws TimeoutException {
logger.info("call writer micro service for finding writer id. correlation id :{}",UserContextHolder.getContext().getCorrelationId());
Long writerId=findWriterFeignClient.findWriterById(dto.getWriterId());
return makeDiary(writerId,dto).orElseThrow(TimeoutException::new);
} @CircuitBreaker(name="diaryService",fallbackMethod = "fallBackMakeDiary")
private Optional<Long> makeDiary(Long writerId, SecurityDiaryPostRequestDTO dto)throws TimeoutException{
logger.info("saving diary... correlation id :{}",UserContextHolder.getContext().getCorrelationId());
DiabetesDiary diary = new DiabetesDiary(writerId, dto.getFastingPlasmaGlucose(), dto.getRemark());
diaryRepository.save(diary);
return Optional.of(diary.getId());
}makeDiary()를 할 때 원격 자원인 db에 접근한다.
@SuppressWarnings("unused")
private Optional<Long> fallBackMakeDiary(Long writerId, SecurityDiaryPostRequestDTO dto,Throwable throwable){
logger.error("failed to call DB in makeDiary. correlation id :{} , exception : {}",UserContextHolder.getContext().getCorrelationId(),throwable.getMessage());
return Optional.empty();
}회로차단기 패턴을 구현할 때 폴백 메서드를 지정해줄 수 있다. 그러면 문제 발생 시 폴백 메서드가 일을 대신해준다. 단, 매개 변수와 리턴 값등 메서드 시그니쳐는 원본 메서드와 동일해야 한다.
컨트롤러에서 예외 처리하기
@PostMapping
public ApiResult<?> postDiary(@RequestBody @Valid SecurityDiaryPostRequestDTO dto) {
Long diaryId;
try {
diaryId = saveDiaryService.postDiaryWithEntities(dto);
return ApiResult.OK(new SecurityDiaryPostResponseDTO(diaryId));
} catch (TimeoutException e) {
return ApiResult.ERROR("Failed to save diary.", HttpStatus.INTERNAL_SERVER_ERROR);
}
}만약 폴백 메서드 리턴 값인 null(Optional로 감싸져있음)이면 500에러 리턴 해주었고, 아니면 200을 리턴해주었다.
포스트맨으로 테스트해보니, findWriterById 원격 호출, makeDiary 원격 호출에서 TimeoutException이 발생할 경우 동일한 폴백 메서드인 fallBackMakeDiary를 호출함을 알게 되었다.
적용해보며 느낀 점
어노테이션 부착과 구성 정보 저장은 쉽다.
그런데 어려웠던 것은, 어떤 상황에 특정 회복성 패턴을 집어 넣고 어떠한 처리 로직을 작성하느냐였다.
개인 프로젝트를 하고 있는 지금, 이 메서드가 호출하는 경로에서 어떤 문제가 많이 발생하는지에 대한 데이터와 경험이 매우 부족하다. 게다가 회복성 패턴만 따져도 자료가 많더라... 아예 따로 공부해야 할 만큼 깊이가 필요한 영역으로 보인다.
책 보다가 발견한 것
책과 그 소스코드를 보다가 발견한 것은, Jpa를 사용하는 서비스임에도 @Transactional이 없다는 것이었다. 흠... 다른 마이크로 서비스의 일관성까지는 바로 지킬 수 없기에 사용하지 않은 것일까? 이유를 따로 찾아볼 필요가 있겠다.
ThreadLocal 추가하기
자바 ThreadLocal을 사용하면, 동일한 스레드에서만 읽고 쓸 수 있는 변수를 사용할 수 있다. 즉, 동기화 없이 스레드 안전을 보장해줄 수 있다.
이는 HTTP 헤더에 상관 관계 ID나 JWT 토큰을 담아서 마이크로 서비스들에 전달될 때 사용된다. 둘다 식별자역할을 하기 때문에 값이 오염되는 것을 방지 하기 위해 ThreadLocal을 사용 해주는 것 같다.
UserContext 작성
ThreadLocal에 저장하기 위한 POJO. 나중에 JWT 토큰으로 바꿀 때 써야 할 것 같다.
@Getter
@Setter
@Component
public class UserContext {
public static final String CORRELATION_ID = "diary-correlation-id";
public static final String AUTH_TOKEN = "Authorization";
public static final String USER_ID = "writer-id";
public static final String DIARY_ID = "diary-id";
private String correlationId = "";
private String authToken = "";
private String userId = "";
private String diaryId = "";
}
UserContextHolder 작성
UserContext를 스레드 안전하게 저장할 수 있도록 ThreadLocal로 담는 랩퍼에 해당한다.
public class UserContextHolder {
private static final ThreadLocal<UserContext> userContext = new ThreadLocal<>();
public static UserContext getContext() {
UserContext context = userContext.get();
if (context == null) {
context = createEmptyContext();
setUserContext(context);
}
return userContext.get();
}
public static void setUserContext(UserContext context) {
userContext.set(context);
}
private static UserContext createEmptyContext() {
return new UserContext();
}
}
Filter 작성 및 컨트롤러에 로깅 추가
서비스 호출이 컨트롤러에 들어가기 전에 필터가 가로채서 Http Header를 분석한다. 그리고 Header 중에서 스레드 별로 안전하게 보장해줘야 하는 변수에 해당되는 것은, ThreadLocal에 저장해서 값 오염을 방지해준다.
@Component
public class UserContextFilter implements Filter {
private static final Logger logger = LoggerFactory.getLogger(UserContextFilter.class);
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
HttpServletRequest request = (HttpServletRequest) servletRequest;
UserContextHolder.getContext().setCorrelationId(request.getHeader(UserContext.CORRELATION_ID));
UserContextHolder.getContext().setAuthToken(request.getHeader(UserContext.AUTH_TOKEN));
UserContextHolder.getContext().setUserId(request.getHeader(UserContext.USER_ID));
UserContextHolder.getContext().setUserId(request.getHeader(UserContext.DIARY_ID));
logger.debug("correlation id : {} ", UserContextHolder.getContext().getCorrelationId());
filterChain.doFilter(servletRequest, servletResponse);
}
}컨트롤러 메서드에도 로깅 명령을 추가해준다.
logger.debug("SecurityDiaryRestController correlation id :{}", UserContextHolder.getContext().getCorrelationId());이렇게 하면 로깅이 필터 -> 컨트롤러 -> 회복성 패턴 어노테이션이 적용된 서비스 순서로 출력된다.
참고
https://javacan.tistory.com/entry/ThreadLocalUsage
게이트웨이 추가
의존성 추가
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-config</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-ribbon</artifactId>
</exclusion>
<exclusion>
<groupId>com.netflix.ribbon</groupId>
<artifactId>ribbon-eureka</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency>
유레카 클라이언트 등록 및 컨피그 서버 정보 등록
@EnableEurekaClient
@SpringBootApplication
public class GatewayServerApplication {
public static void main(String[] args) {
SpringApplication.run(GatewayServerApplication.class, args);
}
}bootstrap.yml에는 컨피그 서버 위치를 알 수 있도록 정보를 기재한다.
spring:
application:
name: gateway-server
cloud:
config:
uri: http://configserver:8071도커 컴포즈 업데이트
gatewayserver:
image: msa/gateway-server:0.0.1-SNAPSHOT
ports:
- "8062:8062"
environment:
PROFILE: "default"
SERVER_PORT: "8062"
CONFIGSERVER_URI: "http://configserver:8071"
CONFIGSERVER_PORT: "8071"
EUREKASERVER_URI: "http://eurekaserver:8070/eureka/"
EUREKASERVER_PORT: "8070"
depends_on:
- configserver
- eurekaserver
networks:
backend:
aliases:
- "gateway"gateway는 유레카 서버와 컨피그 서버 둘다 알아야 되기 때문에 두 서버 기동 이후에 실행되야 하며 두 서버의 정보를 모두 알고 있어야 한다.
Rest url 더 간략하게 변경
@RestController
@RequestMapping("/diabetes-diary")
public class SecurityDiaryRestController {
...
}매핑 경로 설정
외부 구성 정보 gateway-server.yml에 다음과 같이 작성했다.
spring:
cloud:
loadbalancer.ribbon.enabled: false
gateway:
discovery.locator:
enabled: true
lowerCaseServiceId: true
routes:
- id: diary-service
uri: lb://diary-service
predicates:
- Path=/diary/**
filters:
- RewritePath=/diary/(?<path>.*), /$\{path}
...예를 들어, http://localhost:8062/diary/diabetes-diary url은 필터에 의해 원래 url인http://localhost:8062/diary-service/diabetes-diary로 매핑된다. 이렇게 하면 url 길이를 더 짧게 줄일 수 있다.
actuator로 확인
http://localhost:8062/actuator/gateway/routes로 확인해보면 다음과 같은 결과를 얻는다.
[
{
"predicate": "Paths: [/diary-service/**], match trailing slash: true",
"metadata": {
"management.port": "8081"
},
"route_id": "ReactiveCompositeDiscoveryClient_DIARY-SERVICE",
"filters": [
"[[RewritePath /diary-service/(?<remaining>.*) = '/${remaining}'], order = 1]"
],
"uri": "lb://DIARY-SERVICE",
"order": 0
},
{
"predicate": "Paths: [/writer-service/**], match trailing slash: true",
"metadata": {
"management.port": "8082"
},
"route_id": "ReactiveCompositeDiscoveryClient_WRITER-SERVICE",
"filters": [
"[[RewritePath /writer-service/(?<remaining>.*) = '/${remaining}'], order = 1]"
],
"uri": "lb://WRITER-SERVICE",
"order": 0
},
{
"predicate": "Paths: [/gateway-server/**], match trailing slash: true",
"metadata": {
"management.port": "8062"
},
"route_id": "ReactiveCompositeDiscoveryClient_GATEWAY-SERVER",
"filters": [
"[[RewritePath /gateway-server/(?<remaining>.*) = '/${remaining}'], order = 1]"
],
"uri": "lb://GATEWAY-SERVER",
"order": 0
},
{
"predicate": "Paths: [/diary/**], match trailing slash: true",
"route_id": "diary-service",
"filters": [
"[[RewritePath /diary/(?<path>.*) = '/${path}'], order = 1]"
],
"uri": "lb://diary-service",
"order": 0
},
{
"predicate": "Paths: [/writer/**], match trailing slash: true",
"route_id": "writer-service",
"filters": [
"[[RewritePath /writer/(?<path>.*) = '/${path}'], order = 1]"
],
"uri": "lb://writer-service",
"order": 0
}
]postman으로 확인
http://localhost:8062/diary-service/diabetes-diary와
http://localhost:8062/diary/diabetes-diary 모두 동일한 경로로 갔음을 확인했다.
상관 관계 id 추적하기
상관 관계 id를 헤더에 추가하게 되면, 특정 호출이 어떤 마이크로 서비스들을 경유했는지를 추적해낼 수 있다.
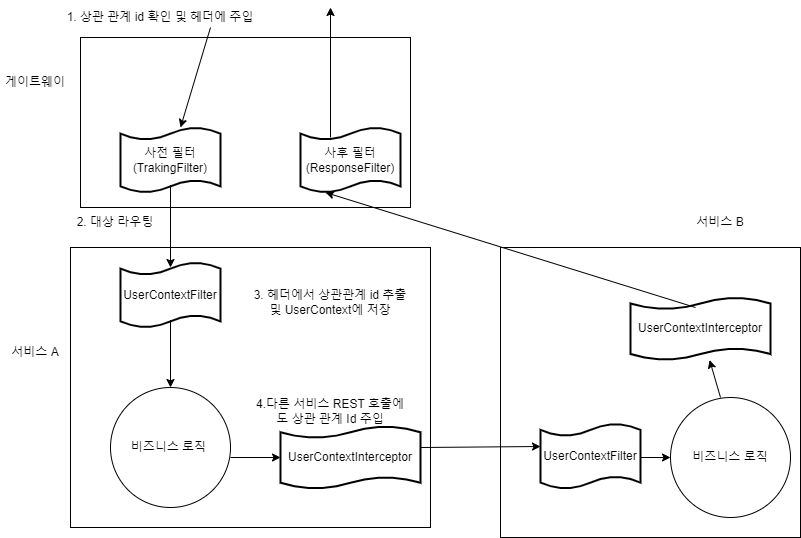
게이트웨이에 사전 필터 만들기
사전 필터의 경우, request에서 상관 관계 id가 헤더에 있는 지 확인한다. 없으면 상관 관계 id를 발급해준다.
@Order(1)
@Component
public class TrackingFilter implements GlobalFilter {
private static final Logger logger = LoggerFactory.getLogger(TrackingFilter.class);
private final FilterUtils filterUtils;
public TrackingFilter(FilterUtils filterUtils) {
this.filterUtils = filterUtils;
}
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
HttpHeaders requestHeaders = exchange.getRequest().getHeaders();
if (isCorrelationIdPresent(requestHeaders)) {
logger.debug("diary-correlation-id found in tracking filter :{} .", filterUtils.getCorrelationId(requestHeaders));
} else {
String correlationId = generateCorrelationId();
exchange = filterUtils.setCorrelationId(exchange, correlationId);
logger.debug("diary-correlation-id generated in tracking filter: {}.", correlationId);
}
return chain.filter(exchange);
}
private boolean isCorrelationIdPresent(HttpHeaders httpHeaders) {
return filterUtils.getCorrelationId(httpHeaders).isPresent();
}
private String generateCorrelationId() {
return java.util.UUID.randomUUID().toString();
}
}마이크로 서비스들에 상관관계 ID 전파용 인터셉터 작성
각각의 마이크로 서비스들에 헤더 인식 필터(UserContextFilter)와 UserContextInterceptor를 만들어준다.
public class UserContextInterceptor implements ClientHttpRequestInterceptor {
@Override
public ClientHttpResponse intercept(HttpRequest httpRequest, byte[] bytes, ClientHttpRequestExecution clientHttpRequestExecution) throws IOException {
HttpHeaders httpHeaders = httpRequest.getHeaders();
httpHeaders.add(UserContext.CORRELATION_ID, UserContextHolder.getContext().getCorrelationId());
httpHeaders.add(UserContext.AUTH_TOKEN, UserContextHolder.getContext().getAuthToken());
return clientHttpRequestExecution.execute(httpRequest, bytes);
}
}
이 인터셉터는 마이크로 서비스에서 다른 마이크로 서비스를 호출할 때 상관관계 id를 헤더에 추가해준다.
UserContextInterceptor 빈 넣기
RestTemplate를 생성할 때, 자동으로 UserContextInterceptor을 넣도록 설정 클래스를 만들고 DI 했다.
@Configuration
public class RestTemplateConfiguration {
@LoadBalanced
@Bean
public RestTemplate getRestTemplate(){
RestTemplate template=new RestTemplate();
List<ClientHttpRequestInterceptor> interceptors=template.getInterceptors();
interceptors.add(new UserContextInterceptor());
template.setInterceptors(interceptors);
return template;
}
}사후 필터 추가하기
요청에 대한 최종 응답을 처리 및 로깅할 수 있도록 게이트 웨이에 사후 필터를 추가했다.
@Configuration
public class ResponseFilter {
private final Logger logger = LoggerFactory.getLogger(ResponseFilter.class);
private final FilterUtils filterUtils;
public ResponseFilter(FilterUtils filterUtils) {
this.filterUtils = filterUtils;
}
@Bean
public GlobalFilter postGlobalFilter() {
return ((exchange, chain) -> {
return chain.filter(exchange).then(Mono.fromRunnable(() -> {
HttpHeaders requestHeaders = exchange.getRequest().getHeaders();
String correlationId = String.valueOf(filterUtils.getCorrelationId(requestHeaders));
logger.debug("adding correlation id to the outbound headers.{}", correlationId);
exchange.getResponse().getHeaders().add(FilterUtils.CORRELATION_ID, correlationId);
logger.debug("complete outgoing request for {}.", exchange.getRequest().getURI());
}));
});
}
}