얼마전 상업적으로도 사용가능한 llama2가 나왔습니다.🤗
직접 사용해보고싶었기 때문에 오늘은 localGPT라는 프로젝트를에서 llama2를 이용하는 방법을 소개하도록 하겠습니다.
localGPT는 앞서 포스팅했던 privateGPT에서 영감을 얻었다하고, 내용이나 코드적으로 굉장히 유사합니다.
[privateGPT와의 차별점]
- GPT4ALL 모델을 Vicuna-7B 모델로 교체
- LlamaEmbeddings 대신 InstructorEmbeddings를 사용
- 임베딩과 LLM은 모두 CPU 대신 GPU에서 실행 (GPU가 없는 경우 CPU도 지원)
저는 여기서 Vicuna-7B 모델을 다시 llama2-7B-chat 모델로 교체해보도록 하겠습니다.
💡 Setting
- 우선 가상환경을 만들고 활성화 해주세요.
conda create -n localGPT
conda activate [가상환경 이름] pyhton==3.10
- 그리고 git을 clone해주시고,
git clone https://github.com/PromtEngineer/localGPT.git
- 기본 path를 설정하여줍니다.
cd localGPT- 이제 필요한 라이브러리를 설치해주시면 기본 셋팅이 완성됩니다!
pip install -r requirements.txt
💡 문서전처리
이 단계에서는 내가 원하는 문서(dox,pdf,csv 지원)를 chunk단위로 분할하고 임베딩 값으로 변환하는 일을 합니다.
- 우선 검색을 원하는 문서를
SOURCE_DOCUMENTS파일에 넣어주세요.
- 그 후 전처리하는 코드를 돌려줍니다. (cpu를 사용하고 싶다면 'python run_localGPT.py --device_type cpu')
python ingest.py 💡 Model Change(llama2)
-
텍스트이제 드디어 제가 사용할 llama를 넣어보는 시간입니다.
-
llama2같은 경우에는 metaAI와 huggingface에서는 승인 요청이 필요합니다. (자세한 내용은 생략)
-
huggingface에서 키를 발급받으셨다면 llama2사용을 Token에 key를 입력해주세요.
huggingface-cli login
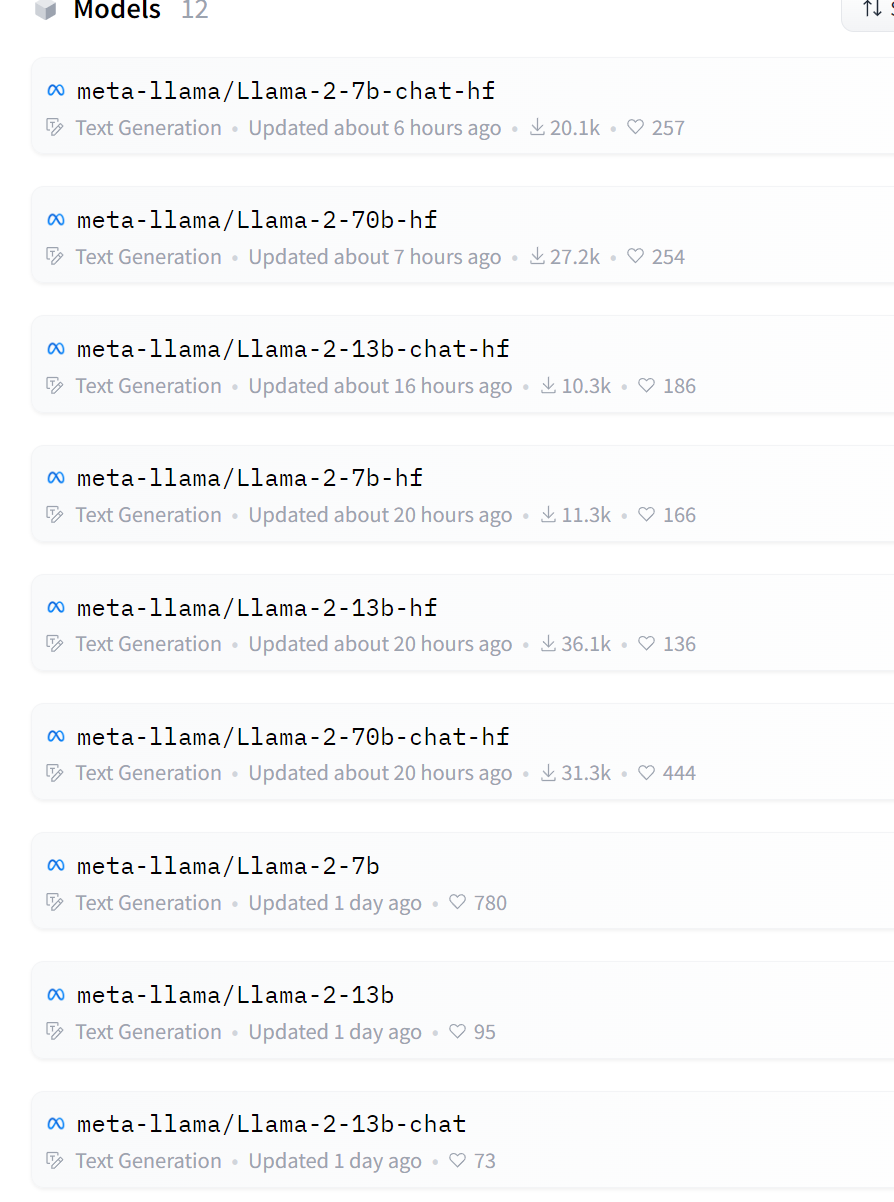
- llama2 모델을 볼 수 있는 곳은 https://huggingface.co/meta-llama 사이트에 들어가셔서 사용하실 모델 이름을 찾고 입력하면 된답니다.
- 단, localGPT를 사용하실거라면, 모델 뒤에 hf가 붙는 걸 사용하는 걸 추천합니다.
- 모델을 선택했다면, run_localGPT.py파일에 들어간 후에 ctrl+f를 눌러서
model_id를 찾아주세요. - 그 후에 사용하실 모델로 바꿔주시고 저장 해주세요.

- 이렇게 모델 이름만 바꿔줬다면 모델을 교체할 준비는 끝이랍니다 !
💡 QARetrieval
- 이제 마지막으로 run_localGPT.py를 돌려주시면 밑에와 같이 질문이 가능해지게 됩니다.
( 마찬가지로 cpu지원을 원하시면 'python run_localGPT.py --device_type cpu'로 입력해주세요.)
python run_localGPT.py
🙏 소감
- 저는 개인적으로 llama2에 굉장한 기대를 걸었는데요...!
- 저의 위 실험에서는 문서에 대해 여러질문들을 했을 때, vicuna-7b가 성능이 더 좋았습니다.
- 또 llama2-13b도 사용해보려고 했으나 메모리 부족으로 못한게 아쉽습니다.
📚 Inference

NLP 파이팅해야지!