메모리 할당에 가장 기본적으로 쓰이는 묵시적 가용 리스트 (Implicit free list) 에 대해서 정리해보자.
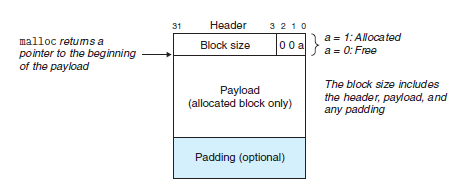
위 블록은 하나의 힙 블록의 이미지다. header, payload, padding 으로 구성된다.
- Header: 1word(4바이트) 짜리 블록 한 칸에 헤더를 배정한다. 헤더는 블록 크기와 블록이 할당된 상태인지 가용 가능한 상태인지에 대한 정보를 담고있다. 사진에서 오른 쪽 위에 00a 라고 되어있는 부분이 블록의 할당/ 가용 상태를 표시하고 있다. Allocator는 32비트 gcc컴파일러에서 8바이트 더블 워드 정렬을 기준으로 구현한다. 즉, 블록의 크기는 항상 8의 배수이며, 그렇기 때문에 끝 세 자리가 항상 0이된다.(2진수기준) a값이 0이면 사용 가능한 상태, 1이면 이미 할당되어있는 상태이다.
- Payload: 우리가 담으려는 실제 데이터가 담기는 영역이다. 만일 데이터를 요청하면 이 payload 영역만을 가져온다.
- Paddindg: 데이터를 payload에 담고 나면 남는 공간을 패딩으로 채운다. 패딩의 크기는 가변적이며 외부단편화를 막기 위해서/정렬요건을 만족시키기 위해서 이다.
할당한 블록의 배치(Placing allocated blocks)
응용 프로그램에서 메모리 할당을 요청하면, allocator는 free list를 검색해서 요청한 만큼의 데이터를 담을 수 있는 가용블록을 찾는다. 블록을 찾는 방법은 3가지 인데 다음과 같다.
First Fit
First fit은 free 리스트를 힙 영역의 가장 맨 처음 헤더에서부터 찾아서 가장 첫 번째로 fit이 맞는 블록을 선택한다. list의 끝쪽에 큰 free 블록을 유지할 수 있다는 장점이 있으나 매번 찾을 때마다 가장 앞쪽에서 부터 검색을 시작하니 효율이 좋지 않다.
Next Fit
Next fit은 first fit과 시작은 동일하나 first fit은 매 서치마다 list의 처음부터 시작하는데 next fit은 이전에 서치했던 영역은 pass하고 그 다음부터 출발한다. first fit보다는 훨씬 빠르나 더 나쁜 memory utilization을 가진다.
Best Fit
모든 free 블록을 조사해 가장 작은 애들 중에서 fit이 맞는 block을 선택한다. 더 나은 utilization을 가지나 훨씬 많이 서치해야 한다. Implicit 방식에서는 비효율적이나, 나중에 배울 segregated free list 방식에서는 가장 효율적으로 찾을 수 있다고 한다.
위의 세 가지 방법으로데이터를 할당할때 주의할 점은, 내부 단편화가 존재하지 않도록 하는 것이다. 가장 처음의 상태를 생각해보면 하나의 큰 가용공간에 작은 데이터를 하나 집어넣는 것은 비효율적인 메모리 사용방법이므로, 내부 단편화가 발생할때, 또 다른 데이터를 넣을 수 있을 만큼의 최소공간을 가진다면 분할해주는 것이 바람직하다.
추가적인 힙 메모리 획득(Extend Heap)
만약 allocator가 요청한 크기 만큼의 가용 블럭을 못 찾는다면 어떻게 할까? 정답은 "추가적인 메모리 공간을 요청해서 추가"이다. 메모리를 최대한 효율적으로 활용하기 위해서 allocator는 자동적으로 연속된 가용블럭들을 합쳐서 큰 가용블럭의 상태로 유지하지만, 이런 상태임에도 불구하고 공간이 모자란 경우에는 추가요청을 한다.(feat. sbrk)
Coalescing
이 작업이 바로 가용 블럭들을 합체해주는 방법이다. allocate 해줄 때도 실행해서 연속된 가용블럭들이 최대한 크게 유지되도록 한다. 아래의 그림을 보면
coalescing 전 나눠진 두 블록.text_center

coalescing 후 합쳐진 두 블록

그렇다면 실제로 합체를 구현하기 위한 방법은 무엇일까? 위의 그림을 보면 바로 뒤의 정보는 쉽게 찾을 수 있다. 하지만 만일 바로 앞의 블록이 가용블록이라면 어떻게 해야할까. 이를 위한 방법은 바로 경계태그로 Footer를 추가해주는 것이다. 헤더와 동일한 형태이며 4바이트의 값이 들어가 있는 블록을 매 블록마다 추가해준다. 메모리의 용량에 관해서는 조금 비효율적인 것처럼 보이나, 정렬과 할당의 효율 면에서는 매우 훌륭하다.
