
1. 서브쿼리 (Subquery)
: 하나의 SQL 문 내에 포함된 또 다른 SQL 문으로, 주로 내부 쿼리의 결과를 외부 쿼리에서 사용합니다.
• 종류:
단일 행 서브쿼리: 한 개의 행을 반환하며, =과 같은 단일 비교 연산자를 사용.
다중 행 서브쿼리: 여러 개의 행을 반환하며, IN, ANY, ALL 등의 연산자를 사용.
상관 서브쿼리: 외부 쿼리의 각 행에 대해 실행되는 쿼리로, 외부 쿼리의 데이터를 참조.
• 사례: 특정 부서의 사원 목록을 조회할 때, 상관 서브쿼리를 통해 각 사원의 부서명을 조회할 수 있습니다.
2. 조인 (Join)
: 두 개 이상의 테이블을 특정 조건에 따라 연결하여 데이터를 조회하는 방식입니다.
• 종류:
INNER JOIN: 조건이 일치하는 데이터만 반환, 공통 키가 반드시 있어야 함.
LEFT OUTER JOIN: 왼쪽 테이블의 모든 행을 반환하며, 오른쪽 테이블의 일치하는 데이터가 없으면 NULL로 표시.
RIGHT OUTER JOIN: 오른쪽 테이블의 모든 행을 반환하며, 왼쪽 테이블의 일치하지 않는 데이터는 NULL.
FULL OUTER JOIN: 양쪽 테이블의 모든 데이터를 반환하며, 일치하지 않는 데이터는 NULL로 표시.
• 사용 사례: 사원 테이블과 부서 테이블을 JOIN하여 사원의 부서명을 함께 조회하는 방식.
3. 그룹 함수 (Group Functions)
: 특정 기준에 따라 데이터를 그룹화하고 요약 통계를 계산하는 함수입니다.
• 주요 함수
SUM: 합계.
AVG: 평균.
COUNT: 개수.
MAX/MIN: 최대값과 최소값.
• 사용법: GROUP BY 구문을 통해 특정 열에 대해 그룹화 후 집계함수를 적용.
• 사례: 부서별 평균 급여를 계산할 때 GROUP BY 부서와 AVG(급여)를 사용
4. 윈도우 함수 (Window Functions)
: 데이터의 특정 윈도우(범위)에 대해 계산을 수행하는 함수로, 행의 순서나 그룹 내에서 계산이 가능합니다.
• 주요 함수:
ROW_NUMBER(): 각 행에 고유 번호를 부여.
RANK(): 값에 순위를 부여하며 동점 시 순위를 건너뜀.
DENSE_RANK(): 값에 순위를 부여하되 건너뛰지 않음.
NTILE(n): 데이터를 n개의 구간으로 나눔.
• 사례: 사원별 급여 순위를 계산할 때 RANK()를 사용하여 순위를 매길 수 있습니다.
5. TOP N 쿼리
: 상위 N개의 데이터를 조회하는 방식으로, 예를 들어 상위 10위까지의 상품 또는 사원을 조회할 때 사용됩니다.
• 사용법: ROWNUM (Oracle), LIMIT (MySQL), TOP (SQL Server) 등으로 구현.
• 사례: 급여가 높은 상위 5명의 사원을 조회할 때 ORDER BY 급여 DESC LIMIT 5와 같은 쿼리를 사용합니다.
6. 계층형 조회 (Hierarchical Query)
: 계층 구조를 가진 데이터를 트리 형식으로 조회하는 방법입니다.
• 키워드:
CONNECT BY: 계층 구조를 정의.
PRIOR: 상위와 하위 데이터를 지정.
LEVEL: 계층 레벨을 나타내는 가상 열.
• 사례: 회사 조직도를 표현하기 위해 상위 부서와 하위 부서 간의 관계를 설정하고 조회합니다.
7. PIVOT과 UNPIVOT
PIVOT: 특정 열의 값을 행으로 변환하여 데이터를 요약하는 방식입니다.
• 사례: 월별 매출 데이터를 열로 변환하여 한 눈에 보기 쉽게 할 때.
UNPIVOT: 행의 데이터를 열로 변환하여 세부 데이터로 확장
• 사례: 여러 열로 나뉘어진 데이터를 하나의 열로 결합하여 분석할 때.
예제: 제품별 월 매출 데이터를 PIVOT을 사용하여 각 월이 열로 나타나게 합니다.
8. 테이블 파티션 (Table Partition)
: 큰 테이블을 논리적으로 분할하여 관리함으로써 성능을 향상시키는 방법입니다.
• 파티션 종류:
범위 파티션: 특정 범위에 따라 파티션.
해시 파티션: 해시 함수를 사용하여 균등하게 분할.
리스트 파티션: 특정 값 목록에 따라 분할.
• 사례: 연도별로 데이터를 파티션하여 관리하여, 특정 연도의 데이터만 빠르게 조회할 수 있도록 합니다.
9. 정규 표현식 (Regular Expressions)
: 문자열 검색과 매칭을 위해 패턴을 정의하는 방식으로, 복잡한 문자열 패턴을 쉽게 다룰 수 있습니다.
• 주요 함수:
REGEXP_LIKE : LIKE 연산과 비슷하며 정규식 패턴을 검색합니다.
REGEXP_REPLACE : 정규 표현식을 대상으로 다른 문자로 대체합니다.
REGEXP_INSTR : 문자열을 검색하고 일치 항목의 위치를 반환합니다.
REGEXP_SUBSTR : 정규식 패턴과 일치하는 문자열을 반환합니다.
REGEXP_COUNT : 정규식 패턴을 검색하여 발견된 횟수를 반환합니다
• 사례: 이메일 형식 검사, 전화번호 형식 검사 등
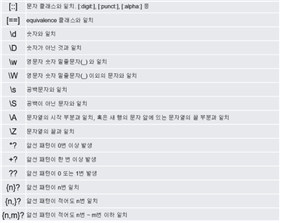
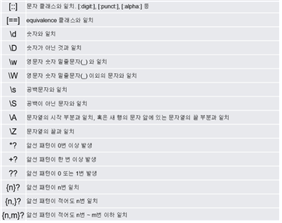
• 정규표현식을 사용하기 위한 메타문자
학습후기
이번 학습에서는 SQL의 고급 함수와 그룹화, 집계에 대한 다양한 기능을 깊이 있게 이해하고 적용하는 방법을 배웠습니다. SQL이 단순히 데이터를 조회하는 데 그치지 않고, 복잡한 계산과 정교한 분석 작업에 강력한 도구임을 다시 한번 깨닫게 되었습니다. 특히 순위 함수, 집계 함수, 행 순서 관련 함수, 비율 관련 함수는 대규모 데이터 집합을 다루거나 데이터의 흐름을 파악할 때 매우 유용한 기능들이었습니다.
순위 함수와 비율 함수는 데이터를 정렬하고, 각 데이터가 전체에서 차지하는 비중을 쉽게 파악할 수 있도록 돕는데, 예를 들어 RANK()와 DENSE_RANK()의 차이점을 통해 데이터를 정렬하는 방식의 중요성을 알게 되었고, RATIO_TO_REPORT() 함수를 사용해 특정 값이 전체에서 차지하는 비율을 계산하는 것이 상대적인 중요성을 평가하는 데 매우 유용하다는 점을 깨달았습니다. 또한 윈도우 함수는 특정 구간 내에서 누적 합계나 평균 등을 계산하는 데 효과적이며, 시계열 데이터 분석에 특히 적합하다는 점이 인상 깊었습니다. LAG와 LEAD 함수는 현재 행을 기준으로 이전이나 다음 행의 값을 참조할 수 있어, 순차적인 데이터 분석에 매우 유용하다는 점도 배웠습니다.
한편 집계 함수들은 데이터 요약에 탁월한 성능을 발휘해, 대규모 데이터를 간단히 요약하고 인사이트를 도출하는 데 큰 도움이 되었습니다. SUM, AVG, MAX, MIN 등의 함수와 GROUP BY 구문을 통해 다수의 데이터를 간편하게 집계할 수 있어 데이터 보고서나 분석 작업에 필요한 핵심 정보를 효과적으로 얻을 수 있다는 점을 배웠습니다. 이런 집계와 요약 작업을 통해 SQL이 데이터를 정제하고 인사이트를 추출하는 강력한 도구라는 것을 다시 한 번 실감했습니다.
결국 이번 학습은 SQL을 활용한 데이터 분석 능력을 한층 더 향상시키는 계기가 되었고, 앞으로 실무에서 복잡한 데이터 분석 시나리오에 SQL을 자신 있게 적용해보고 싶다는 생각이 들었습니다. 이 과정을 통해 SQL이 데이터 처리와 분석에서 얼마나 중요한 역할을 하는지, 그리고 이를 잘 활용하면 얼마나 효율적으로 데이터를 다룰 수 있는지 깊이 느낄 수 있었습니다.
