파이썬머신러닝완벽가이드
1.[ML] K-Fold Cross Validation
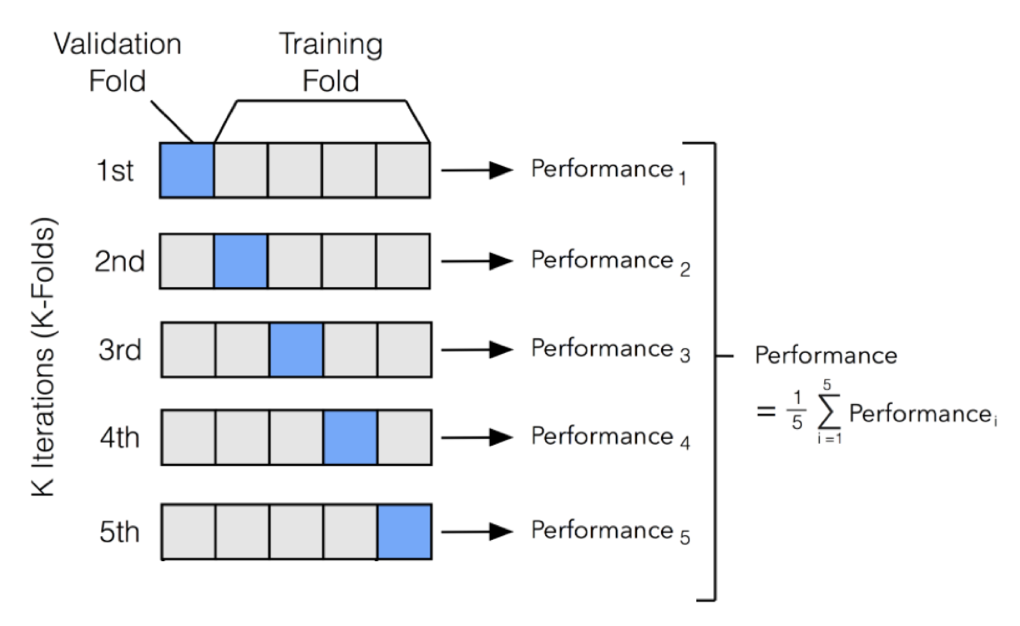
2023년 7월 16일
2.[ML] 적절한 스케일링 방법

우선, 표준화와 정규화를 통칭하여 '스케일링'이라고 표현함데이터 컬럼별로 분포를 뽑아서 분포에 맞는 스케일링을 적용하려고 하는데 어떤 분포에 어떤 스케일링이 효과적일까?일반적으로 스케일링은 개별 feature내에서 데이터들이 skew되었거나, 서로 다른 feature들
2023년 10월 7일
우선, 표준화와 정규화를 통칭하여 '스케일링'이라고 표현함데이터 컬럼별로 분포를 뽑아서 분포에 맞는 스케일링을 적용하려고 하는데 어떤 분포에 어떤 스케일링이 효과적일까?일반적으로 스케일링은 개별 feature내에서 데이터들이 skew되었거나, 서로 다른 feature들