순차탐색
- 순차탐색Seqiential Search란 리스트 안에 있는 특정한 데이터를 찾기 위해 앞에서부터 데이터를 하나씩 차례대로 확인하는 방법
def sequential_search(n, target, array):
# 각 원소 하나씩 확인하여
for i in range(n):
# 현재의 원소가 타겟값과 일치할 경우
if array[i] == target:
# 현재위 위치 반환 (인덱스 이므로 +1)
return i + 1
print('생성할 원소 갯수, 타겟 문자열 입력하세요')
input_data = input().split()
n = int(input_data[0])
target = input_data[1]
print('앞서 적은 원소 갯수만큼 문자열을 입력하세요')
array = input().split()
# 순차탐색 결과 출력
print(sequential_search(n, target, array))- 순차탐색은 데이터 정렬 여부와 상관없이 하나씩 확인해야 하므로, 데이터의 개수가 N개일 때, 최악의 시간복잡도는
이진탐색 : 반으로 쪼개면서 탐색하기
- 이진탐색Binary Search는 내부의 데이터가 정렬되어 있어야만 사용할 수 있음
- 탐색범위를 절반씩 좁혀가며 데이터를 탐색하기 때문에 매우 빠르게 데이터를 찾을 수 있음
- 이진탐색은 위치를 나타내는 변수 3개 사용 : 탐색하고자 하는 범위의 시작점, 끝점, 중간점
- 찾으려는 데이터와 중간점 위치에 있는 데이터를 반복적으로 비교하여 원하는 데이터를 찾음
- 중간점이 float형일 경우, 소수점 이하를 버려서 중간점을 설정
- 이진탐색은 한번 확인 시 확인하는 원소의 개수가 절반씩 줄어든다는 점에서 시간복잡도가
- 이진탐색을 구현하는 방법에는 재귀함수, 단순반복문 2가지 경우가 있음
- 재귀함수로 구현한 코드
def binary_search(array, target, start, end):
# 종료조건
if start > end:
return None
mid = (start + end) // 2
# 찾은 경우 중간값 인덱스 반환
if array[mid] == target:
return mid
# 중간값이 타겟값보다 큰 경우
elif array[mid] > target:
# 왼쪽 확인 (start ~ mid-1)
return binary_search(array, target, start, mid-1)
# 중간값이 타겟값보다 작은 경우
else:
# 오른쪽 확인 (mid+1 ~ end)
return binary_search(array, target, mid+1, end)
n, target = list(map(int, input().split()))
array = list(map(int, input().split()))
# 인덱스 값이므로 n - 1 ex)원소의 개수가 10개면 인덱스는 0~9
result = binary_search(array, target, 0, n-1)
if result == None:
print('원소가 존재하지 않습니다.')
else:
# 몇 번째 원소인지 반환해야하므로 인덱스에 더하기 1
print(result + 1)- 반복문으로 구현한 코드
def binary_search(array, target, start, end):
# start가 end보다 작거나 같을 때만 실행
while start <= end:
# 중간값 설정
mid = (start + end) // 2
# 같으면 mid 반환
if array[mid] == target:
return mid
# 중간값이 타겟값보다 크면 왼쪽 확인
elif array[mid] > target:
end = mid-1
# 중간값이 타겟값보다 작으면 오른쪽 확인
else:
start = mid + 1
# start가 end보다 크면 None 반환
return None
n, target = list(map(int, input().split()))
array = list(map(int, input().split()))
# 인덱스 값이므로 n - 1 ex)원소의 개수가 10개면 인덱스는 0~9
result = binary_search(array, target, 0, n-1)
if result == None:
print('원소가 존재하지 않습니다.')
else:
# 몇 번째 원소인지 반환해야하므로 인덱스에 더하기 1
print(result + 1)- 탐색범위가 2,000만을 넘어가면 이진탐색으로 접근해보자
- 처리해야 할 데이터의 개수나 값이 1,000만 단위 이상으로 넘어가면 이진탐색과 같이 의 속도를 내야하는 알고리즘 떠올려야 함
트리 자료구조
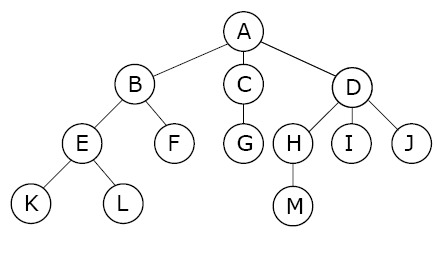
- 이진탐색은 전제조건이 데이터 정렬
- 데이터베이스는 내부적으로 대용량 데이터 처리에 적합한 트리 자료구조를 이용하여 항상 데이터가 정렬되어 있음
- 트리 자료구조 특징
1. 트리는 부모노드와 자식노드의 관계로 표현
2. 트리의 최상단 노드를 루트노드라고 함
3. 트리의 최하단 노드를 단말노드라고 함
4. 트리에서 일부를 떼어내도 트리구조이며 이를 서브 트리라고 함
5. 트리는 파일 시스템과 같이 계층적이고 정렬된 데이터를 다루기에 적합 - 트리구조로 데이터 저장 -> 이진탐색과 같은 기법 활용해 빠르게 데이터 탐색 가능
이진 탐색 트리
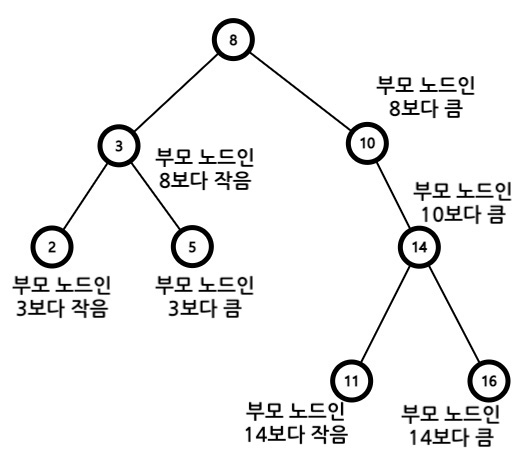
- 이진 탐색 트리란 이진탐색이 동작할 수 있도록 고안된, 효율적인 탐색이 가능한 자료구조
- 이진 탐색 트리 특징
1. 부모노드보다 왼쪽 자식노드가 작음
2. 부모노드보다 오른쪽 자식노드가 큼 - 즉, 왼쪽 자식노드 < 부모노드 < 오른쪽 자식노드
빠르게 입력받기
- 이진탐색 문제는 입력 데이터가 많거나, 탐색범위가 매우 넓은 편
- 데이터 개수가 1,000만 개를 넘어가거나 탐색범위가 1,000억 이상이라면 이진탐색 알고리즘을 떠올려보자
- 입력 데이터의 개수가 많은 문제에 input() 함수를 사용하면 동작 속도가 느려서 시간초과 판정을 받을 수 있음
- 입력 데이터가 많은 문제는 sys 라이브러리의 readline()함수를 이용하면 시간초과 피할 수 있음
import sys
input_data = 'hello, coding, test!'
# 하나의 문자열 데이터 입력받기
input_data = sys.stdin.readline().rstrip()
# 입력받은 문자열 그대로 출력
print(input_data)- rstrip() 꼭 호출해야 함, readline()으로 입력하면 입력 후 엔터Enter가 줄 바꿈 기호로 입력되는데, 이 공백 문자를 제거하려면 rstrip()을 사용해야 함

来日方长 : 앞길이 구만리 같다; 앞길이 희망차다. 장래의 기회가 많다.