<목차>
ㅇ DB 개념 이해
- 데이터 무결성
- 중복 최소화
ㅇ 무결성 디테일
- 프라이머리키
- 포린키
<데이터베이스>
ㅇ 학습 목표
- 데이터베이스가 뭔지
- sql 이라는 언어를 사용하는 방법
cf. 이론적인 디테일 부분은 정보처리기사에서 봐
ㅇ 빅데이터/인공지능 고객에게 서비스를 제공하는 과정
- 수집 - 저장 - 분석 - 예측 - 서비스
- 수집 (예) 동창회 주소록을 엑셀파일로 만들려고 할 때, 각각 사용자들에게 야 너희 주소 줘~ 라고 해.
- 저장 (예) 마트에서 사 온 여러 물건을 냉동은 냉동실, 냉장은 냉장실, 실온은 펜트리 - 각각의 특성에 맞게 저장
- 즉, 데이터도 특성에 맞는 것끼리 저장
- 분석, 예측 (예) 냉동식품 사용할 때 해동, 조리, 양념 등 가공을 해
- 서비스 : 만든 음식을 사용자에게 내보내
- 데이터베이스는 저장과 관련된 것
- 데이터베이스(DB) : data를 모아놓은 집합, 저장공간
ㅇ data (vs) 정보
- 데이터를 '가공'하면 정보가 돼
- 데이터는 가공되지 않은 것
정보는 데이터를 가공해서 얻어낸 결과 - 예) 1+1 = 2 는 정보일까?
- 1은 데이터
- +라는 가공을 해서 2라는 결과를 얻어낸 것
- 즉, 2는 정보
- 예) 1+1 = 3 이러면?
- 1은 데이터
- 3은 정보는 맞아. 잘못된 정보
ㅇ 데이터 무결성
예) 주식이야기
- 내일 어떤 회사 주식 상장된대 천프로튄다해서 샀는데 회사 망함
- 알고 봤더니 1년 전에 신기술 개발. 이게 1년 전에 멈춰버린 거야
- 이 1년 전 데이터를 가지고 가공해서 상장이라는 잘못된 정보를 뽑아버린 거야
- 오늘 시점의 데이터였다면 주식상장이 아니라 회사 부도라는 정보를 얻어냈을 거야
- 즉, 데이터가 가치와 신뢰를 가지려면 최신 것을 알려줘야 해 = 데이터가 정확해야 해
ㅇ 데이터 무결성
- 데이터베이스는 단순히 데이터를 저장해 놓은 곳이 아니라
- 그 안에 들어있는 데이터들은 무결성이 보장되어 있어야 해
- 정확한 데이터들을 모아놔야. 정보를 활용했을 때 정확한 정보를 돌려줄 수 있다.
- 데이터베이스의 구조 또한 '데이터 무결성 보장'을 최우선으로 생각하는 방향으로 만들어져 있어
ㅇ 데이터베이스(DB)
: data의 무결성이 보장된 데이터를 모아놓은(저장) 집합
- '중복을 최소화' 시켜서 무결성을 보장
- DB의 제일 큰 적은 중복이다.
ㅇ 그러면 무결성을 어떻게 보장할 수 있을까?
-
분류, 이정표
예) 땡처리하는 곳에서는 : 자기가 원하는 곳을 찾을 때까지 뒤지고 다녀
마트, 백화점에서는 : 분류가 잘 되어 있어서, 이정표가 있어서 = 쉽다. 편하다. -
우리는 자료를 만들 때 자연스럽게
표를 그리고 제목을 넣어. why? 보기 편하니까
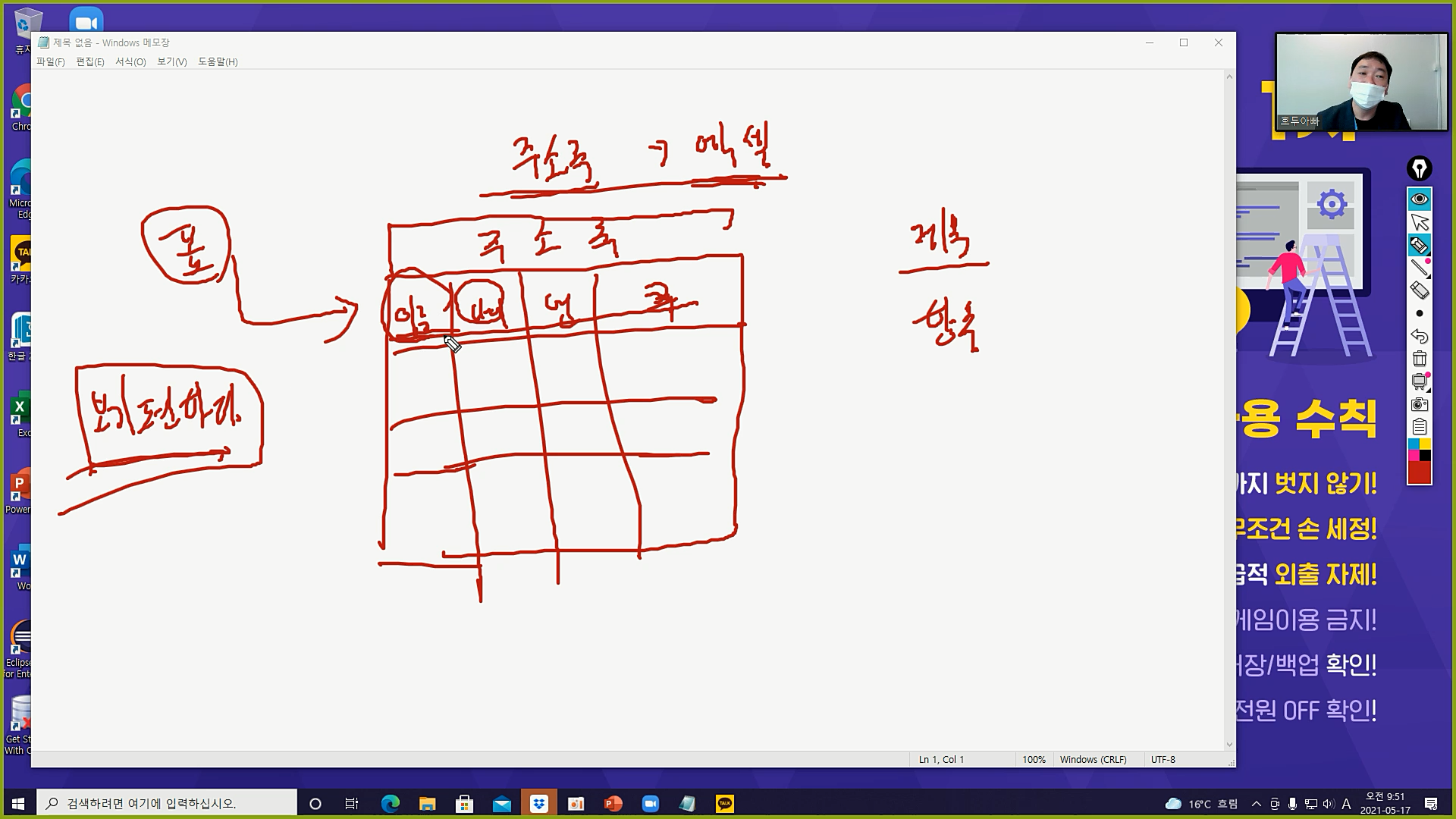
- 이름이라는 열에는 이름만 넣자, 나이에는 나이만 넣자
이런 게 하나의 약속이야 - 제목을 다는 이유 : 어떤 데이터인지 알려주기 위해
- 이름이라는 열에는 이름만 넣자, 나이에는 나이만 넣자
-
즉, DB는 (막 저장하는 게 아니라)
어떤 분류에 따라 정확한 데이터들만 저장할 수 있도록 하는 구조를 가짐- 단순히 데이터 저장할 때 분류 없이 땡처리처럼 저장하는 게 아니라
- 정확한 데이터들을 저장하기 위해 분류라는 걸 만들어서
- 그 분류에 맞게끔 데이터를 모아놓은 곳
ㅇ 최종 정리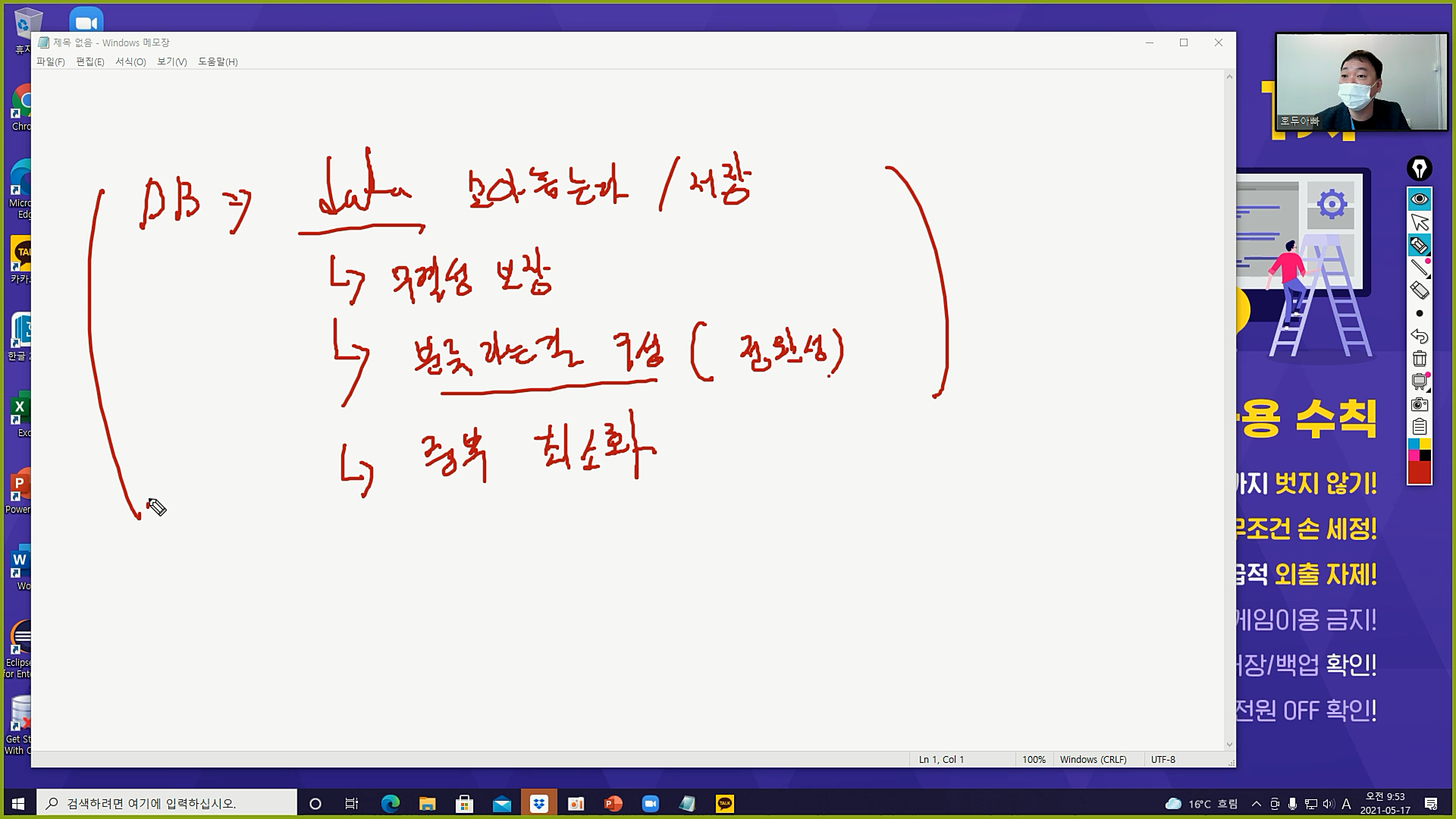
- DB는 무결성이 보장된 데이터를 모아놓은(저장) 집합
- '분류'를 통해 무결성이 보장된 데이터를 저장 (= 정확성 보장)
- 저장할 때 중복을 최소화시키더라
ㅇ 저장한 목적은 뭐야? 사용하려고 !!!
- 냉동식품 저장해뒀어 저장 잘 되는지 저장하는 거야? 냉장고 성능 좋은지 보려고?? 아냐 => 나중에 쓰려고! 사용하려고!
- 단순히 저장하기 위해 저장하는 게 아냐. 그냥 저장만 해두면 공간 낭비야
- 이걸 사용해야지~
- 분석, 결과를 만들어서 웹이든 앱이든 인터페이스를 통해 고객들에게 제공해
∴ 현재 데이터베이스에서 배우는 것이 저장된 데이터 활용하는 방법
( 꺼내서 어떻게 사용하고 분석하는지는 추후에 배울 거야 )
ㅇ 무결성
- 테이블에 저장된 데이터들은 무결성이 보장되어야 한다
- 데이터베이스라는 것 자체가 저장을 하는 곳이긴 하지만
- 무결성을 자동으로 관리하지는 않아
- 그래서 사용되는 것이 프라이머리 키, 포린 키
ㅇ 프라이머리 키 (PRIMARY KEY. PK)
- 여러 개의 컬럼들 중 그 테이블을 대표할 수 있는 속성에 부여하는 키
- 예) 우리나라 전체 국민들이 반드시 가지고 있어야 하는 값... 주민등록번호.없으면 간첩. 똑같은 게 있으면 사기꾼 ㅋㅋ
- 값이 있어야 한다 => NOT NULL
- 중복되면 사기꾼 => UNIQUE
- 예) s대학이라는 대학 학생들의 정보 저장하는 테이블
- 제목 : s대학 학생
- 속성 : 학번, 주민번호, 이름, 나이
- NOT NULL + UK 특성을 가지고 있는 것은?
- 학번과 주민번호
- 이런 걸 후보키라고 해
- (정처기 시험에서 중요한 개념. 실무에서는 쓸모 없... )
- 이 후보들 안에서 주전(프라이머리 키) 뽑아
- 그러면 (학번, 주민번호) 중 어떤 게 프라이머리 키로 지정되는 게 맞을까? 정답) 학번
- 주민등록 번호는 다른 학교 학생도 가질 수 있어
- s대학 학생만 학번을 가지고 있어
- 즉, '낫널+유니크' 조건을 만족하면서 대표하는 속성에 부여
- 가장 이상적인 테이블은 한 개의 컬럼에 한 개의 프라이머리 키가 지정되어 있는 테이블
- 2개 이상 지정하는 경우도 있긴 해 - 슈퍼키, 복합키
- 프라이머리 키는 무결성을 보장해주는 조건이다.
- 즉 무결성 보장을 자동으로 하는 게 아니라 키라는 형태로 조건을 줘
- 조건에 맞는 데이터들만 저장
- 그러면 항상 정확한 데이터만 저장되어 있겠지 ~
(내생각) 그니까 원래 데이터가 있어. 무결성이 자동으로 보장되진 않아.
데이터의 무결성 보장하기 위해 우리가 어떤 대푯값에 프라이머리 키를 설정하면 '낫널+유니크' 라는 조건에 맞는 데이터들만 저장
그니까 프라이머리 키가 이런 특징을 가진다. 가 아니라 / 반대로 그런 용법으로 사용한다는 거지. 어떤 컬럼을 프라이머리키로 설정해 줌으로써 널은 버리고, 중복도 버려
ㅇ 정리 : 무결성 보장을 위해
- 무결성 보장을 위해 테이블의 속성(컬럼)에 키라는 걸 부여(지정)
- 키 라는 건 제약조건. 조건에 맞는 데이터들만 저장하게 하기 위한 규칙이다
- 대표적인 게 프라이머리 키
- 테이블은 프라이머리 키가 없으면 엄청난 문제 발생. 중복 발생. 무결성 깨져
- 예) 학생테이블에 학번.이름.나이.여자친구 컬럼
학번 100 이름 김 ㅇㅇ 나이 19 여자친구 a
학번 100 이름 김 ㅇㅇ 나이 19 여자친구 b
학번 100 이름 김 ㅇㅇ 나이 19 여자친구 c- 현재 여자친구는? 누군지 알 수 없어. 심지어 세 다리 걸친 걸 수도 있지
- 데이터의 중복 = 데이터 불일치 = 무결성이 깨졌다.
- PK로 이런 조건 걸어놓으면 중복 최소화
: 학번이 PK이므로 100이 여러 줄 나오는 게 허용 안 돼
ㅇ 포린키 (외래키 참조키 FOREIGN KEY. FK)
- 다른 테이블에 컬럼 데이터를 참조하는 키
- 테이블과 테이블을 연결
- 무결성이 깨지지 않도록 보장
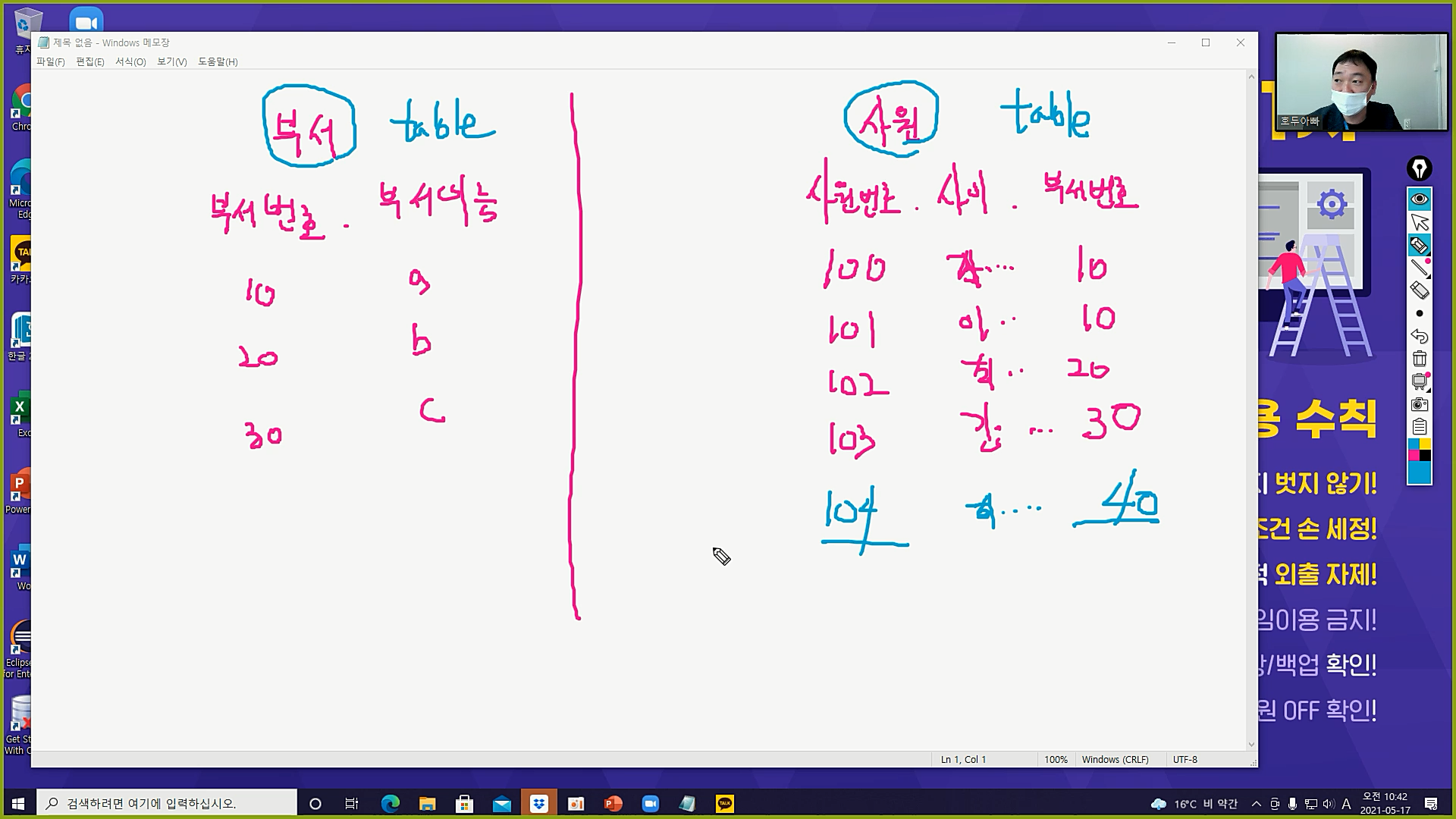
- 104번.최ㅇㅇ.40 이 데이터가 저장될 수 있을까?
- 물리적으로는 저장돼
- 논리적으로는 저장되면 안 되는 데이터
: 그 회사에 근무하는 사원에 대한 거니까 회사에 존재하지 않는 부서번호 40번을 넣어버리면 안 돼 = 데이터 불일치 - 즉, 물리적으로 저장은 될 수 있으나, 저장해 버리는 순간 사원테이블의 무결성이 깨지는 거야
- 즉, 사원테이블의 부서번호는 부서테이블에서 나온 부서번호 10, 20, 30 만 써야 해
=> 사원테이블의 부서번호는 FK
ㅇ 요약
- PK
- 낫널 + 유케이
- 테이블을 구성하는 대표 컬럼에 설치
- 반드시 1개 이상의 프라이머리 키를 가지고 있어야 해
- 가장 이상적인 건 1개만 설치되어 있는 것
- FK
- 참조하는 것
- 다른 테이블에 컬럼 데이터를 참조하는 키
- 테이블과 테이블의 관계를 설정할 때 사용
- 둘 다 무결성 보장하기 위해 사용.
- 무결성 보장 <=> '키'를 사용
Q. 프라이머리 키를 여러 컬럼으로 설정하는 건?
A. '하나의컬럼-하나의PK'가 유발할 수 있는 문제 있을 때
- 예) 쇼핑몰. 장바구니에 담았다가 한 번에 결제
- 주문번호가 프라이머리 키이면 두 행이 다른 주문이야. 즉, 라면사고 결제. 참치 주문하고 결제.. 너무 불편해
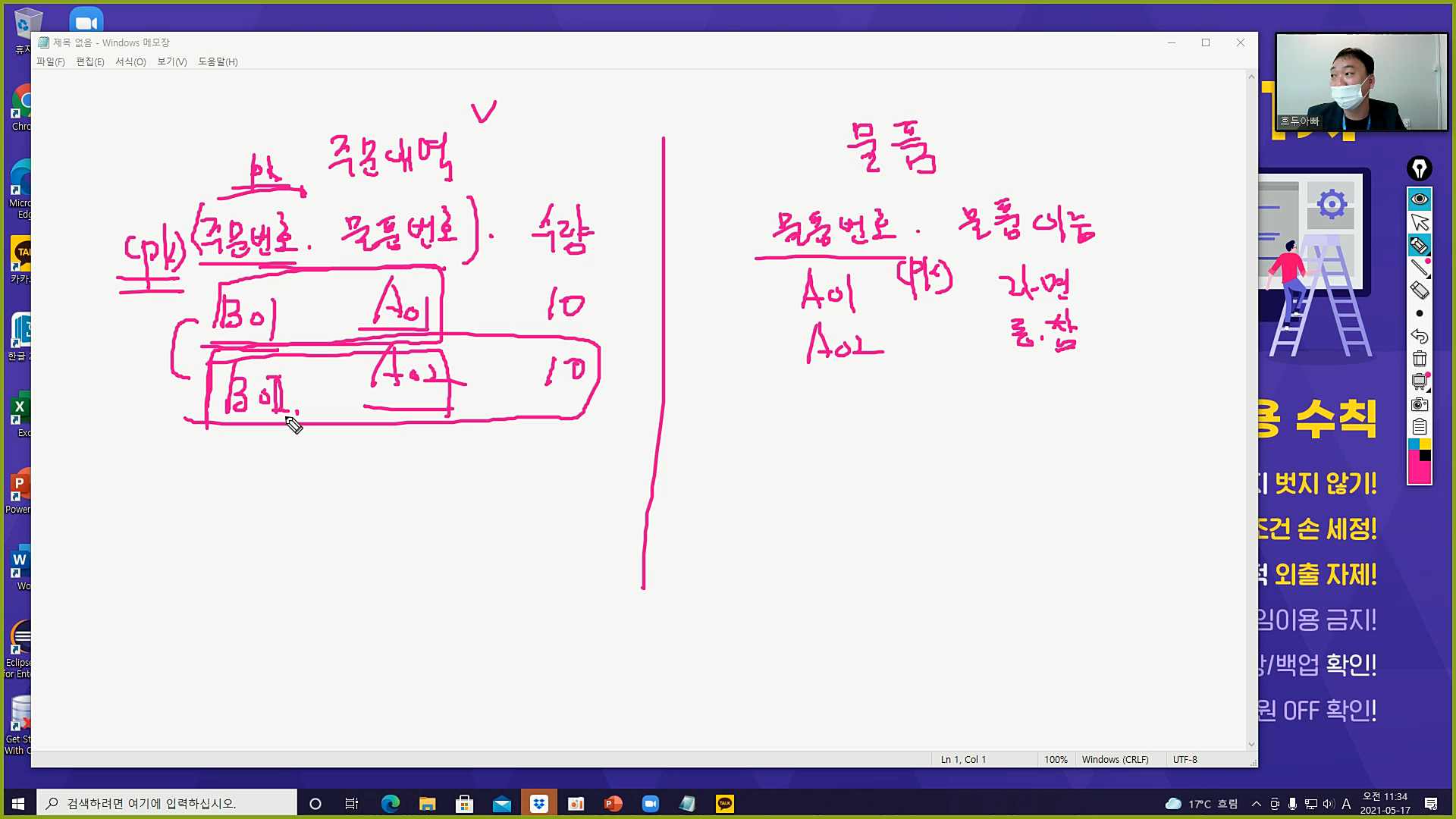
- 주문번호가 프라이머리 키이면 두 행이 다른 주문이야. 즉, 라면사고 결제. 참치 주문하고 결제.. 너무 불편해
- 이럴 때 복합 프라이머리 키 사용
- 주문번호와 물품번호 합쳐서 프라이머리 키 => 슈퍼키
- 이러면 행 단위로는 중복이 일어나지 않아 : (B01, A01) ≠ (B01, A02)
- 컬럼 단위로는 중복 허용 : B01 나오고 또 B01 나올 수 있어
- '하나의컬럼-하나의PK' : 유일성(중복없다), 최소성(1개컬럼)
- 슈퍼키 : 유일성은 만족. 최소성은 만족 못 해 (여러 개의 컬럼이라서)
- 슈퍼키는 기본적으로 중복이 허용돼서 공간의 낭비 있으니
검색속도 떨어지는 부분 있을 수는 있어.
하지만 현실에서 이런 상황이 안 일어날래야 안 일어날 수 없으니 필요할 때 사용
CF. 1차 프로젝트 진행할 때 이걸 만들 수 있게 될 거야
내가 설계한 디비에 이런 구조가 나올 수 있어

STEP BY STEP