<목차>
ㅇ 데이터베이스 공부할 때 : 분석하는 습관
ㅇ 테이블 살펴보는 법
- 구조 확인 desc
- 사이즈 조절 column
ㅇ SQL문 작성 시 유의점
<공부 방법에 대한 이야기>
ㅇ 프로그래머들이 가져야 할 기본적인 소양
-
성능
- 코드를 짜는 다양한 방법 존재하겠지만
- 비용적 시간적인 부분 감안했을 때 가장 효율적인 방법을 짜는 게 궁극적으로 해야 할 일이야.
- 결과가 나오는 게 중요한 게 아냐.
결과가 나온다고 안심하면 최악의 프로그래머 - 특히 데이터베이스 쪽에서 셀렉트라는 명령문은 성능에 영향 많이 미쳐
-
결과 해석
- DB를 다루는 언어(데이터를 가져와서 보는 언어)라서 결과 자체가 너무 중요해
- ★ 어떤 결과가 떨어지는지 데이터를 분석하는 습관을 가져야 해 ★
ㅇ 실습, 공부할 때 지키면 좋은 프로세스 : 분석하는 습관
- 코드 작성하고 실행하지마
- 코드를 반드시 분석해 : 직역은 기본이고, 의역까지
- 결과를 예측하기
- 그담에 코드 실행
- 그 결과를 비교 분석을 해보기 (예측한 결과와 실제 실행 결과를 비교)
- 이걸 안 지키는 사람은 엔터 땅! 소리가 들려ㅋㅋ 엔터 소리가 안 들려야 해ㅋㅋㅋ
ㅇ 셀렉트 문이 어려운 이유
- DB의 구조를 이해하고 있어야 해
- 떨어지는 결과에 대해 분석할 수 있어야 해 => 이에 대한 이해가 떨어지면 공부가 어려워지는 거야
- 이걸 위해서 저 프로세스대로 공부하라고 하는 거야~
ㅇ 약어 사용할 때 풀네임 알고 쓰기
- conn은 connect
- ed는 edit
- 똑같은 약어인데 환경에 따라 다른 뜻으로 사용될 때도 있어
- desc : describe 디스크라이브
- desc : descending(디센딩) 이건 데스크라고 읽어
- 제일 싫어하는 약자 varchar(베리어블케릭터)
- 바챠라고 읽으면 발로 차 버릴꺼야 ㅋㅋ
<테이블을 살펴보는 방법>
ㅇ 테이블의 구조 확인 : DESC
DESC 테이블이름;
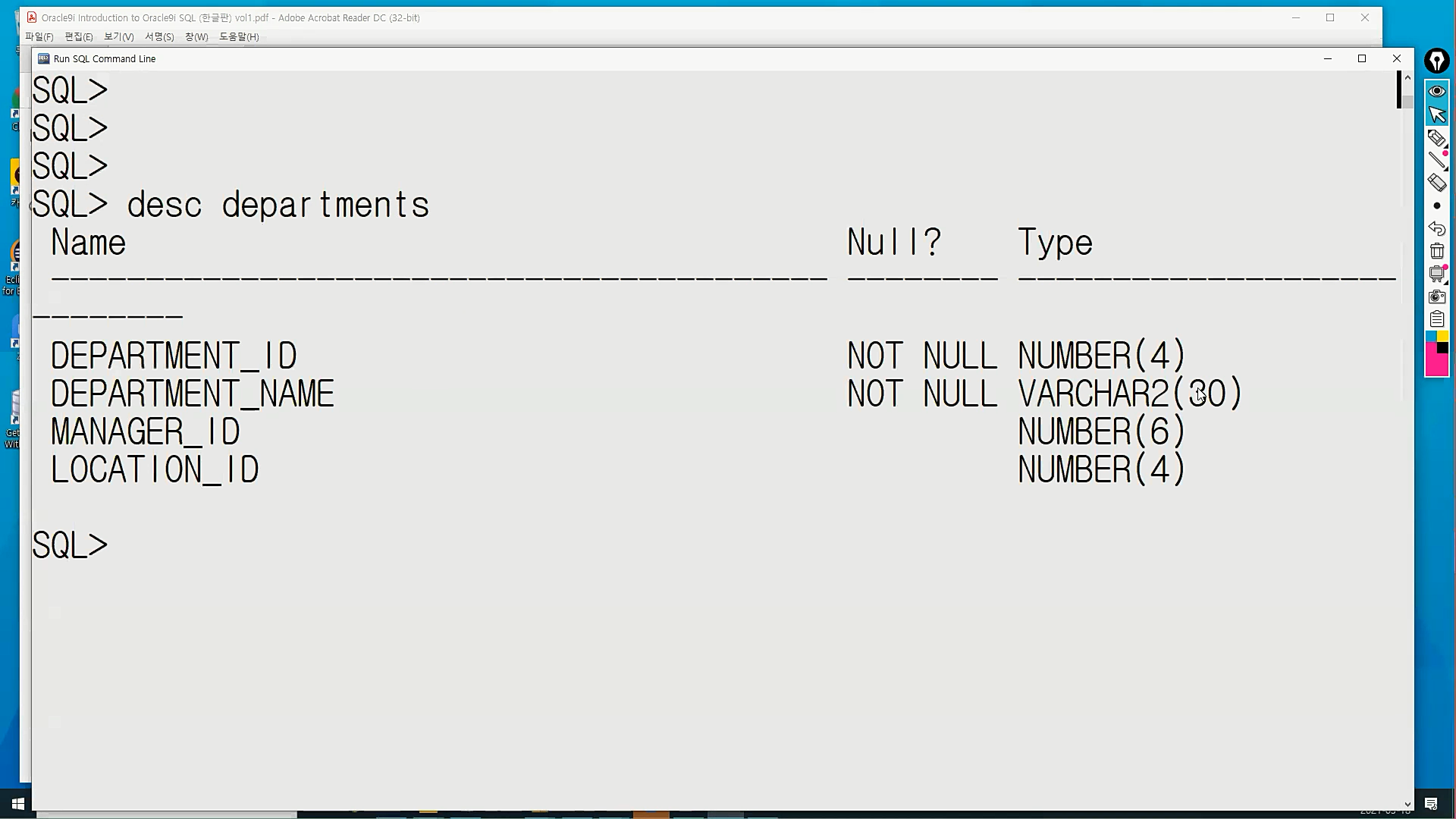
- NUMBER(4) : 숫자타입이고 4개까지 쓸 수 있다.
- VARCHAR(variable characters)(30) : 문자타입이고 30byte까지 쓸 수 있다.
- 영문은 한 글자당 1byte, 한글은 한 글자당 2byte
- 데이터타입 (5월26일필기)
ㅇ 출력되는 컬럼의 사이즈를 조절하는 명령어 : COLUMN
- sql명령어가 아니라 sql+의 편집 명령어 (ed에 남지 않아)
- -------가 여러 줄 생겨서 보기 힘들어
- 사이즈를 점선으로 표현해. 예) 문자 30개 가능한 네임은 -가 30개
- sql+ 는 창이 고정되어 있어서 점선이 창을 넘어가 버리면 여러 개의 열로 출력돼버려
- 출력된 값들을 편안하게 볼 수 있도록 해줘
- 문자와 날짜 : 알파벳(a) 포맷으로 사이즈를 조절
COLUMN department_name format a17명령어 / 수정할 컬럼 이름 / 17자리로 수정을 하겠다
- 만약 숫자 데이터에 a17 사용한다면 : #으로 에러나
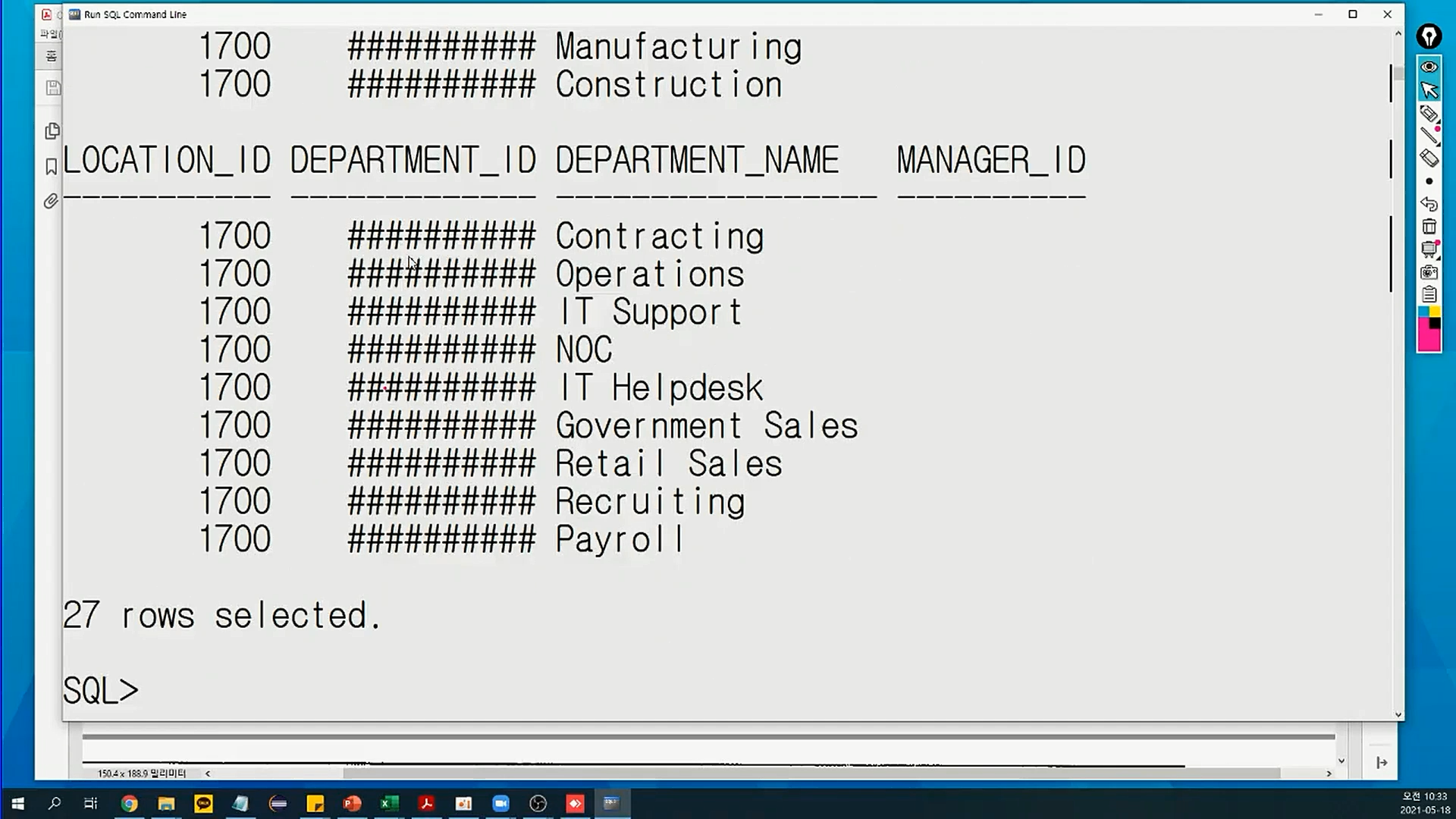
- 숫자는 9를 써
COLUMN department_id format 99999999명령어 / 수정할 컬럼 이름 / 8자리(9의 개수)로 수정을 하겠다
- CF) department_name과 last_name 만 사이즈 짧게 조정해놓으면 대부분 데이터는 한 줄에 보여
ㅇ 사이즈 조절을 취소하는 명령어
COLUMN department_name clear
ㅇ SQL 문 작성할 때 유의점
- sql이 대소문자 구분하진 않아. 하지만 우리는 구분해서 쓰자!
- ∵ 성능상의 이유로
- 현업에서 보통 쓰는 규약
- SELECT 같은 명령문은 대문자
- table이나 column 이름은 소문자

ㅇ 대소문자로 성능 차이가 나는 이유는?
- 메타데이터 : 데이터의 데이터. 데이터를 표현해 놓은 데이터
- 101동 101호는 물리적인 공간. 이 안의 아빠 엄마 누가 무슨 일을 하고 이런 수많은 정보가 있어
- 얘가 어디에 저장되어 있고, 얼마만큼 사이즈 할당, 누구 소유고, 어떤 제약조건을 가지고 있고 등등
- 이런 물리적인 데이터의 수많은 정보들(메타데이터)을 데이터 딕셔너리(D.D)에 저장. 사람의 뇌에 해당
- 비절차적 언어인 SQL
- 명령문 입력하고 엔터 때리면 바로 실행
- 그러나 디비 내부에서 컴파일에 해당하는 파싱 작업이 이루어져
- PARSING
- 위키백과 : 컴퓨터 과학에서 파싱((syntactic) parsing)은 일련의 문자열을 의미 있는 토큰(token)으로 분해하고 이들로 이루어진 파스 트리(parse tree)를 만드는 과정을 말한다.
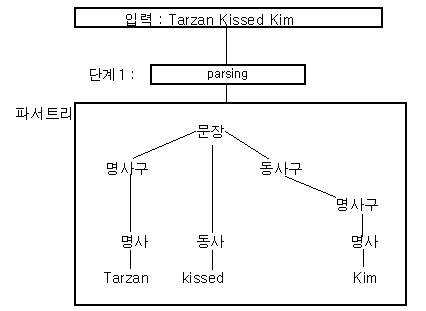
- 위키백과 : 컴퓨터 과학에서 파싱((syntactic) parsing)은 일련의 문자열을 의미 있는 토큰(token)으로 분해하고 이들로 이루어진 파스 트리(parse tree)를 만드는 과정을 말한다.
- 파싱의 과정
- 1 검증 : 디버깅 단계. 테이블,컬럼이 존재하는지, 문법 문제없는지, 무결성 위배 안 되는지
- 2 실행계획 수립 : 테이블(프롬절)로부터 컬럼(셀렉트리스트절)의 데이터를 가져오는 방법을 실행계획으로 수립
- 비용 시간 측면에서 가장 빠른 방법을 실행계획으로 수립해줘
- 가장 빠르게 검색할 수 있는 방법으로
- 3 실행 : 거기에 따라 실행돼서 우리한테 결과가 출력되는 거야
- 실제로는 명령어가 수행되면 파싱작업을 먼저 수행하지 않고 데이터 딕셔너리를 먼저 뒤져
- D.D에 파싱 결과와 그 셀렉트 문장의 문장 텍스트를 저장해둬
- 기록 정보에 똑같은 문장이 없으면 파싱 수행
- 있으면 그냥 재사용 = 파싱 작업을 안 했다는 말 = 검색 속도가 빨라진다
- 뒤질 때의 기준 : asc2(아스키코드)문자를 숫자로 표현 (예)대문자a는 65번)
즉, 대소문자 구분
- 내가 대소문자 왔다 갔다 하면 D.D에서 재사용 못 해서 파싱이 진행돼
ㅇ결론
- 그래서 프로그래머들은 자신만의 규약을 만들어두는 게 좋아. 그러면 성능이 좋아져
(5월 20일 수업) - 실제로 데이터베이스 내에서는 컬럼,테이블 이름들이 대문자로 저장되어 있긴 해
하지만 나만의 규칙 만들어서 사용하는 게 좋아

STEP BY STEP