지난주에는 데이터베이스 및 테이블 만들기로 전체 구성에 대해 맛보기로 경험해보았다면 이제 SQL 문법들을 하나씩 알아보고자 한다.
SELECT ~ FROM ~WHERE
먼저, SELECT문은 테이블에서 데이터를 추출하는 기능을 하며, 아무리 많이 사용해도 기존 데이터가 변경되지는 않는다.
SELECT를 실습하기 위해서는 데이터베이스가 있어야한다.
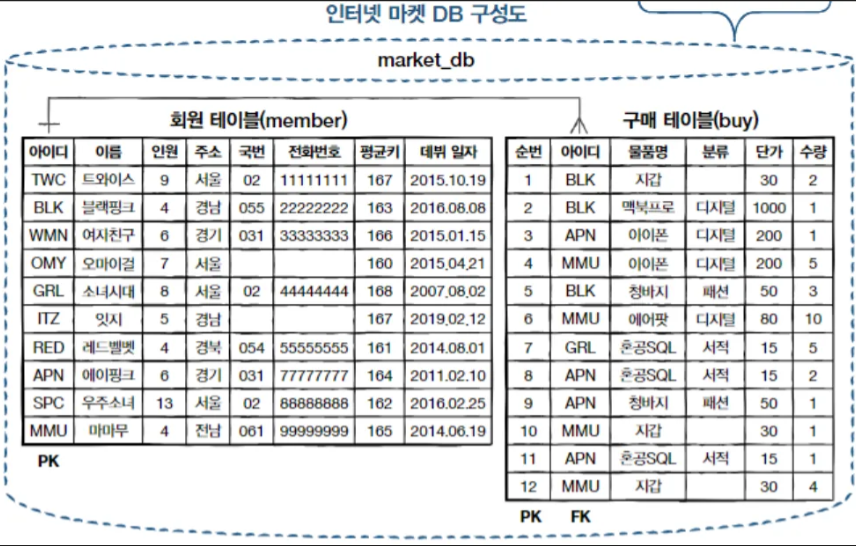
다음 '인터넷 마켓 DB 구성도'는 인터넷 마켓에서 운영하는 데이터베이스를 단순화한 것이다.
혼공자료실에서 market_db.sql파일을 다운로드 하여 미리 작성된
SQL문을 활용하여 하나씩 알아보자.
<기본 조회하기>
'인터넷 마켓 DB 구성도'를 활용하여 SELECT문을 배워보자.
USE문
USE문은 사용할 데이터베이스를 지정할때 사용한다.
USE 데이테베이스이름;
여기서 우리는 market_db를 활용할 것이기에
USE market_db;
라고 쓰면 된다.
보통 SELECT문의 기본 형식은 아래와 같다.
SELECT 열 이름
FROM 테이블 이름
WHERE 조건식
GROUP BY 열 이름
HAVING 조건식
ORDER BY 열 이름
LIMIT 숫자
그렇다면
USE market_db;
SELECT * FROM member;
라는 쿼리를 쓴다면 market_db안에 있는 member라는 테이블 전체 데이터들이 출력 될것이다.
여기서 특정 조건만 조회하고 싶다 하면 WHERE 문이 사용된다.
WHERE이 없으면 테이블의 모든 행들이 출력되지만, WHERE문을 사용하면 내가 지정한 조건에 맞게 데이터를 출력할 수 있다.
SELECT * FROM member
WHERE mem_name= '블랙핑크';
라는 쿼리를 작성하면, member테이블에서 mem_name이라는 열 데이터 값이 블랙핑크인 데이터들만 출력하게 된다.
추가적으로 관계연산자와 논리 연산자를 활용하여
SELECT mem_id, height, mem_number
FROM member
WHERE height >=165 and mem_number>6;
이런식으로 쿼리를 작성할 수 있는데
그렇게 되면 키가 165 이상이고 멤버수가 6초과인 데이터들의 mem_id, height,mem_number 열들의 데이터를 출력하여 확인할 수 있다.
BETWEEN~AND
BETWEEN A AND B로 보통 사용이 되는데,
이때 의미는 A보다 크거나 같고,B보다 작거나 같은 수치들을 의미하며, WHERE뒤에서 부등호 대신 유용하게 사용할 수 있다.
IN()
IN은 OR로 연결한 데이터를 더 간결하게 표기할수 있다.
예를들어
SELECT mem_name, addr
FROM member
WHERE addr IN('경기', '전남', '경남');
이라는 쿼리가 있다고 가정하자.
그러면 여기서 경기 또는 전남 또는 경남 이라는 addr 데이터값을 가진 정보들을 출력할수 있다.
따라서 단순하게 보면 IN에 묶여있는 값중에 하나라도 속하면 출력되는 구조이다.
LIKE
문자열의 일부 글자를 검색하는데 사용한다.
SELECT *
FROM member
WHERE mem_name LIKE '우%'
%의 의미는 무엇이든 허용한다이며
우로 시작하고 뒤에 어떤것이 올수 있는 단어가 mem_name에 들어있는 정보를 출력하는 것이다.
또한 다른 방법으로는 LIKE '__ 핑크';
로 언더바를 활용하여 앞의 두글자가 오며 뒤에 핑크가 붙은 데이터를 출력할때도 활용한다.
ORDER BY절
ORDER BY절은 결과의 값이나 개수에 영향을 미치지는 않지만,
결과가 출력되는 순서를 조절하는 역할을 한다.
SELECT mem_id, mem_name, debut_date
FROM member
ORDER BY debut_date;
라는 쿼리가 있다면
member라는 테이블에서 위 3개의 열의 데이터를 출력하고,
ORDER BY문을 통해 debut_date를 기준으로 오름차순으로 정렬하여 출력한다.
따라서 데뷔날짜가 빠른순으로 출력이 될것이다.
데뷔를 늦게한 순서대로 출력하고 싶으면 내림차순으로 출력해야 되며,
ORDER BY debut_date DESC;
라고 표기하면 된다.
위에 오름차순을 표기하지 않은 이유는 ASC는 기본값이며 아무것도 쓰지 않으면 오름차순으로 출력된다.
LIMIT
출력 개수를 제한하는 역할을 한다.
SELECT mem_id, debut_date
FROM member
ORDER BY debut_date
LIMIT 3;
이면 데뷔를 일찍한 3개의 팀의 데이터가 출력이 된다.
DISTINCT
중복된 결과를 제외하는 역할을 한다.
기본적으로
SELECT addr FROM member;
하면 member테이블에 있는 addr의 모든 정보, 즉 모든 주소를 출력할 것이다.
이때 겹치는 주소를 한번만 출력하고 싶을때
SELECT 뒤에 DISTINCT를 붙이면, 한번씩만 출력해준다.
GROUP BY절
GROUP BY절은 말 그대로 그룹으로 묶어주는 역할을 한다.
집계함수를 활용하기도 하며, 집계함수는 아래와 같다

SELECT mem_id, COUNT(*) as member_counts
FROM buy
GROUP BY mem_id;
다음 쿼리를 보면 mem_id를 기준으로 grouping을 한다.
id가 5인거끼리묶고, 2인거끼리 묶고 이런식으로..
그 다음 SELECT에서 집계함수를 활용하면 MEM_ID와 MEM_ID별로 멤버들이 몇명있는지를 알아낼수 있다.
이래서 집계함수를 활용하는 것이다.
HAVING절
Having절도 WHERE절과 기능적으로는 같은 조건절이지만,
HAVING은 Group by문 뒤에 붙어 grouping한것들에 조건을 건다는 점에서 차이가 있다.
따라서 GROUP BY절에서 했던 대로 집계함수를 활용하여 조건을 정할 수 있다.
WHERE절에서는 집계함수를 사용할 수 없다
그렇다면 이번엔 좀더 긴 쿼리를 작성해보자.
SELECT mem_id AS 회원 아이디, SUM(price amount) AS 총 구매 금액
FROM buy
GROUP BY mem_id
HAVING SUM(price amount)>1000
ORDER BY SUM(price*amount) DESC;
쿼리를 작성하는 것도 중요하지만 작성된 쿼리를 읽고 어떤 데이터를 표현하고자 하는 쿼리인지
해석하는 능력도 중요하다.
위 쿼리를 보면 buy테이블에서
mem_id별로 grouping을 하고 그룹힝한 데이터들 중에 price와 amount를 곱하고 더한 값이 1000초과인 mem_id를 기준으로 하여, 그 mem_id와 sum값을 출력할것이고
sum값은 내림차순이니까 큰값부터 쓰겠다라는 의미이다.
이때 나는 가장 큰 값만 출력하고 싶다 하면 LIMIT 1;을 추가로 작성하여 최댓값까지 산출할 수 있다.

문제 해설) SELECT-FROM-WHERE-(GROUP BY-HAVING)-ORDER BY-LIMIT 이 순서도를
기억하고 문제를 풀면된다.
참고로 LIMIT뒤에 숫자 두개가 나오면, LIMIT 시작, 개수라는 의미를 가진다.
