K-means vs DBSCAN
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans, DBSCAN
# 샘플 데이터 생성
X, _ = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)
# K-Means 클러스터링
kmeans = KMeans(n_clusters=4, random_state=0)
kmeans_labels = kmeans.fit_predict(X)
# DBSCAN 클러스터링
dbscan = DBSCAN(eps=0.5, min_samples=5)
dbscan_labels = dbscan.fit_predict(X)
# 시각화
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
# K-Means 시각화
axes[0].scatter(X[:, 0], X[:, 1], c=kmeans_labels, cmap='viridis')
axes[0].set_title("K-Means Clustering")
# DBSCAN 시각화
axes[1].scatter(X[:, 0], X[:, 1], c=dbscan_labels, cmap='viridis')
axes[1].set_title("DBSCAN Clustering")
plt.show()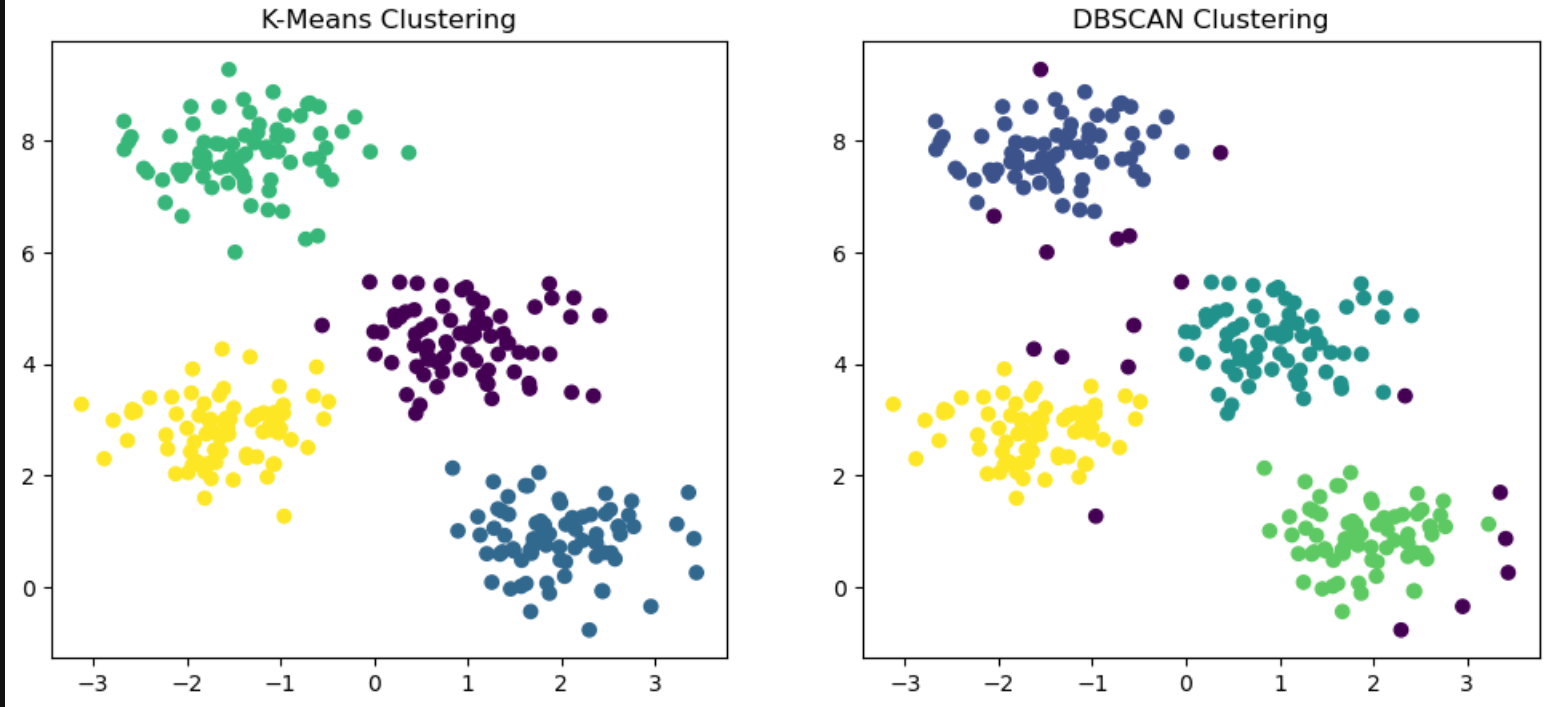
DBSCAN은 Outlier도 잡아낼 수 있고 Clustering Phase에 큰 영향을 가지지 않는다. 반면 K-means Centroid가 움직이는데 영향을 줄 수 있음.
그렇다면 Non-Globular Shape는?
import os
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from sklearn.cluster import KMeans, DBSCAN
import warnings
# 경고 제거
os.environ["OMP_NUM_THREADS"] = "2"
os.environ["LOKY_MAX_CPU_COUNT"] = "8" # 사용 중인 코어 수로 수정 가능
warnings.filterwarnings("ignore")
# 비구형 데이터 생성
X, _ = make_moons(n_samples=300, noise=0.05, random_state=42)
# K-Means 클러스터링
kmeans = KMeans(n_clusters=2, random_state=42)
kmeans_labels = kmeans.fit_predict(X)
# DBSCAN 클러스터링
dbscan = DBSCAN(eps=0.2, min_samples=5)
dbscan_labels = dbscan.fit_predict(X)
# 시각화
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
# K-Means
axes[0].scatter(X[:, 0], X[:, 1], c=kmeans_labels, cmap='viridis')
axes[0].set_title("K-Means (Fails on Non-Globular Shapes)")
# DBSCAN
axes[1].scatter(X[:, 0], X[:, 1], c=dbscan_labels, cmap='viridis')
axes[1].set_title("DBSCAN (Good on Non-Globular Shapes)")
plt.tight_layout()
plt.show()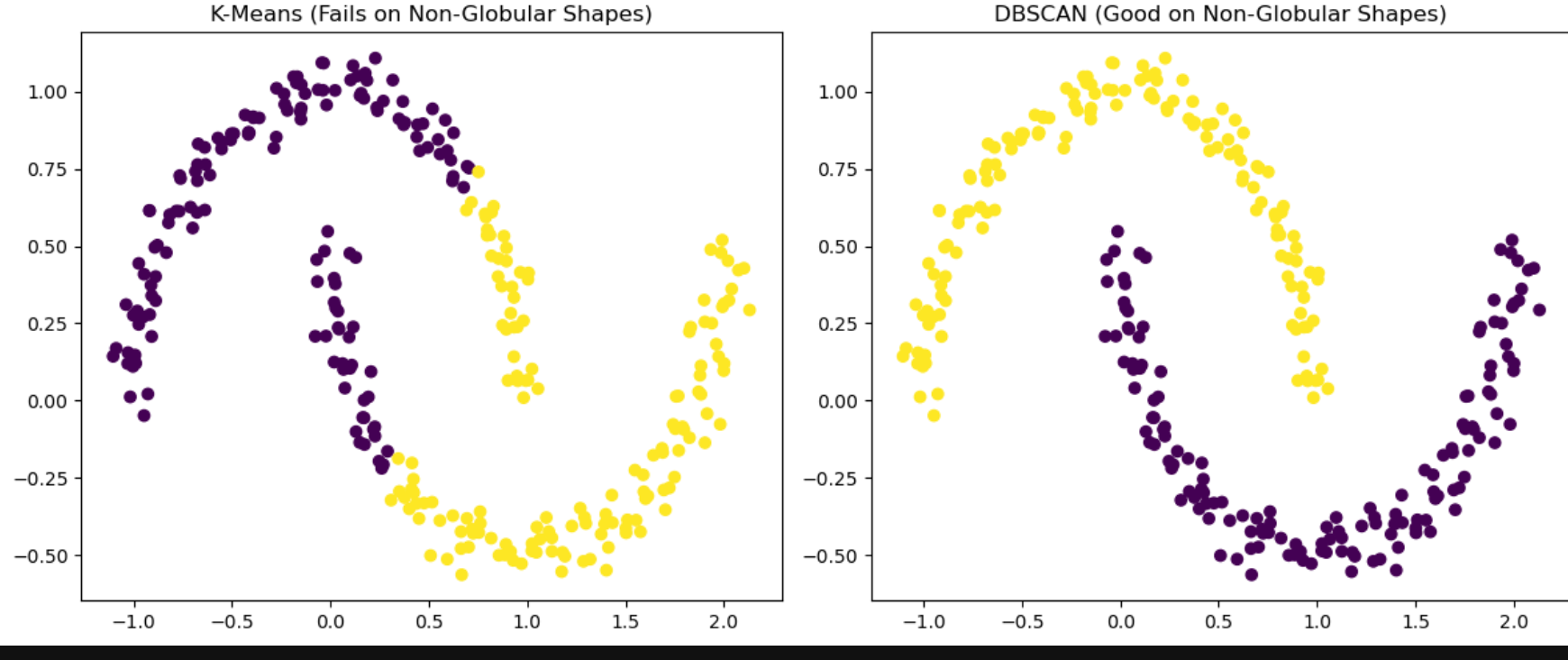
- K-means는 Non-globular shape의 데이터를 탐지하기 힘들다!(억지로 Centroid를 만들기 때문에)

안녕하세요! 강민수입니다.