Import Dataset
import pandas as pd
import numpy as np
#dataset
data = pd.read_csv("C:\\Users\\datam\\Downloads\\diabetes.csv")Data pre-processing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 특성과 타겟 분리
X = data.drop('Outcome', axis=1)
y = data['Outcome']
#전처리
X = X.replace(0, np.nan)
X.fillna(X.mean(), inplace = True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)ROC Curve
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from xgboost import XGBClassifier
from sklearn.metrics import accuracy_score, confusion_matrix, roc_auc_score, roc_curve, auc
import matplotlib.pyplot as plt
# 모델 초기화
models = {
"Logistic Regression": LogisticRegression(),
"SVM": SVC(probability=True), # SVM에서 확률을 계산하기 위해 probability=True 설정
"Random Forest": RandomForestClassifier(),
"XGBoost": XGBClassifier(use_label_encoder=False, eval_metric='logloss')
}
# 성능 지표를 저장할 딕셔너리
performance_metrics = {}
plt.figure(figsize=(10, 8))
for name, model in models.items():
# 모델 학습
model.fit(X_train_scaled, y_train)
# 예측 및 확률 계산
y_pred = model.predict(X_test_scaled)
y_pred_proba = model.predict_proba(X_test_scaled)[:, 1]
# 혼동 행렬 계산
cm = confusion_matrix(y_test, y_pred)
tn, fp, fn, tp = cm.ravel()
# 성능 지표 계산
sensitivity = tp / (tp + fn)
specificity = tn / (tn + fp)
accuracy = accuracy_score(y_test, y_pred)
auroc = roc_auc_score(y_test, y_pred_proba)
performance_metrics[name] = {
"Sensitivity": sensitivity,
"Specificity": specificity,
"Accuracy": accuracy,
"AUROC": auroc
}
# ROC Curve
fpr, tpr, _ = roc_curve(y_test, y_pred_proba)
plt.plot(fpr, tpr, lw=2, label=f'{name} (AUROC = {auroc:.2f})')
plt.plot([0, 1], [0, 1], linestyle='--', color='gray')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curves')
plt.legend()
plt.show()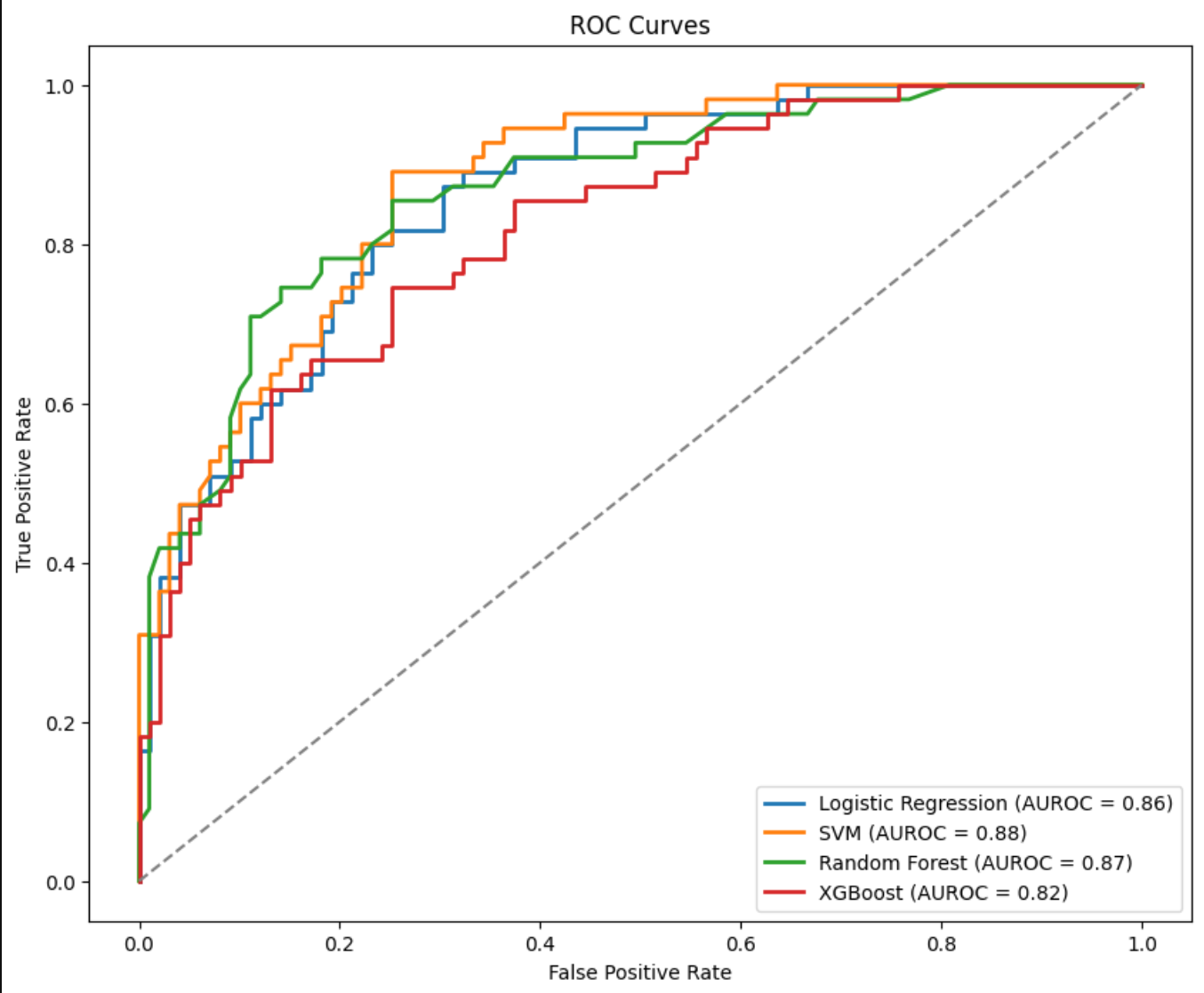
- 서포트 벡터머신이 가장 높은 AUROC
- XGBoost가 대채적으로 낮은 성능
성능지표
# 성능 지표 출력
for model, metrics in performance_metrics.items():
print(f'{model}:')
for metric, value in metrics.items():
print(f' {metric}: {value:.2f}')
print('\n')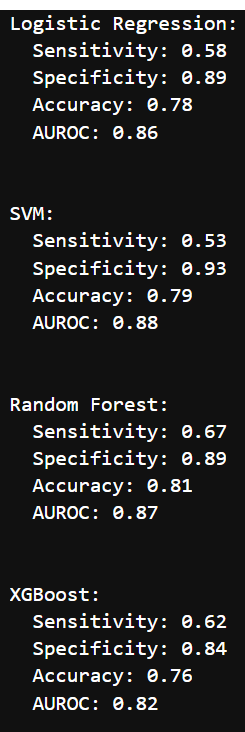
추가적으로 성능지표도 출력해서 볼 수 있음
for loop로 모델마다 돌려서 Confusion metric의 성능들을 볼 수 있었음.
Type I, Type II가 중요한 거에 따라서 모델을 선택하고 절대적인 모델은 없다는걸 항상 염두해두면 좋을 것 같음.
또한, 최적의 theta threshold를 찾는 technique은 argmin(theta)(|sensitivity - specificity|) 지점을 찾으면 된다. sense와 spec의 차이가 가장 적은 threshold(theta)

안녕하세요! 강민수입니다.