[논문리뷰] MEON (Multi-task End to end Optimized deep neural Network)

Abstract
저자는 문제가 정해지지 않은(Blind) 이미지의 품질 평가를 위한 딥러닝 신경망인 MEON(Multi-task End to end Optimized deep neural Network)을 제시했습니다. MEON은 왜곡을 식별하는 네트워크 하나와, 품질 예측을 하는 네트워크 하나로 이루어져 있습니다. 기존 다중작업을 하는 네트워크 교육에 사용되는 방법과 다르게 저자의 학습 절차는 두 단계로 구현되어있습니다.
-
왜곡 식별 네트워크를 훈련시킵니다. 이 네트워크는 쉽게 구할 수 있는 대규모 train 샘플로 학습시켰습니다.
-
학습되어있는 layer로 시작해서 첫번째 네트워크로 결과물을 냅니다. 저자들은 품질 예측 layer를 SGD를 사용해 학습했습니다.
기존 딥러닝 신경망과의 차이점은 활성화 함수로 ReLU 대신 생물학에서 영감을 받은 GDN(Generalized divisive normalization)을 사용했습니다. 저자들은 실증적으로 GDN이 모델의 파라미터와 layer를 감소시키고 동시에 품질예측 성능을 달성한다는 것을 증명했습니다. 제안된 MEON 인덱스는 모델 복잡성이 적기 때문에 공개적으로 사용 가능한 4가지 벤치마크에서 최첨단 성능을 달성합니다.
들어가기에 앞서 네트워크 1은 왜곡을 식별하는 네트워크, 네트워크 2는 품질을 예측하는 네트워크로 명명하겠습니다. 많은 부분을 이곳에서 참고했습니다.
특징 분석
-
MEON은 256 x 256 x 3의 raw 이미지를 입력으로 가져와서 인지 품질 점수를 측정합니다.
-
MEON은 두 하위 작업을 두 하위 네트워크에서 수행합니다. 역할은 다음과 같습니다.
- 왜곡 유형을 식별하는 것을 목표로 하는 네트워크
- 왜곡의 가능성을 확률 벡터의 형태로 나타낸다.
- 이미지 품질을 예측하는 네트워크
- 왜곡 유형을 식별하는 것을 목표로 하는 네트워크
-
각각의 하위 작업들은 loss function을 포함합니다.
-
네트워크 2는 네트워크 1에서 나온 결과물에 의존합니다. 두 네트워크의 loss는 독립적이지 않습니다.
-
저자는 MEON의 미리 학습된 공유 layer를 통해 하위 작업 1과 통합된 loss function을 통해 전체 네트워크를 공동으로 최적화합니다.
GDN as Activation Function
-
GDN 변환은 이전에 밀도를 추정하거나 이미지 압축 부분에서 잘 작동하는 것으로 입증되었습니다
-
Generalized Divisive Normalization transform
-
는 spatial location에서 정규화된 활성화 벡터입니다.
-
는 weigth 행렬, 는 GDN에 최적화 될 매개변수입니다.
-
두가지 모두 0에서 의 값을 가집니다.
-
GDN은 ReLU보다 정보를 보존하는 것이 더 나은것으로 입증되었습니다.
-
반면, GDN은 BN과 여러 면에서 다릅니다. GDN은 특히 여러 단계이고 계단식일 때 높은 비선형성을 제공합니다.
Network Architecture
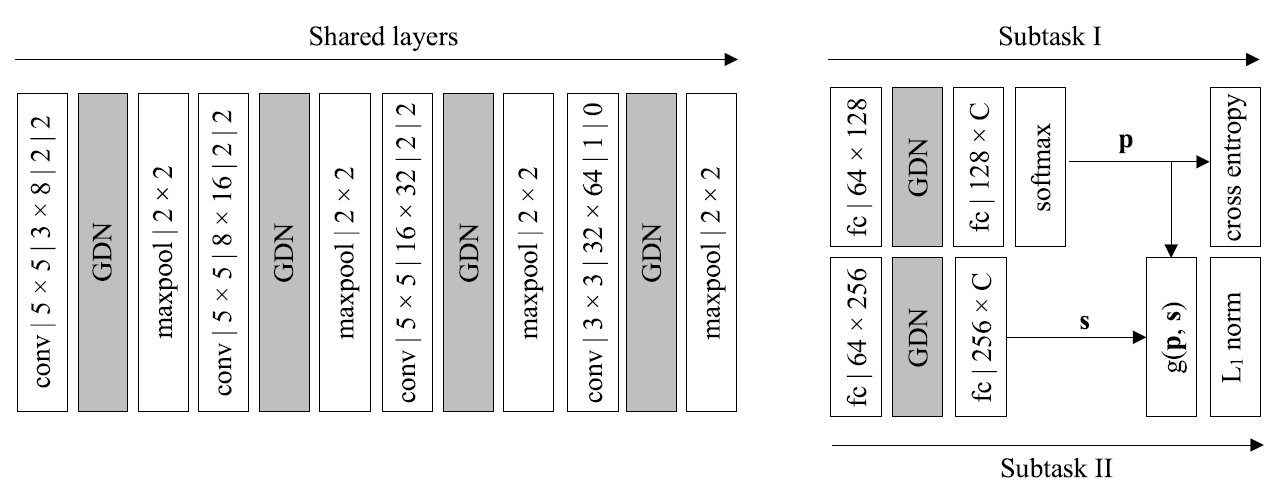
- 저자들은 input으로 들어가는 mini-batch 학습 데이터를 아래와 같이 설정했습니다.
-
는 번째 원본 이미지, 는 실측 값의 왜곡 유형을 인코딩하기 위해 하나의 항목만 활성화된 다중 클래스 지표의 벡터입니다.
-
는 번째 이미지의 MOS 평가 지표입니다.
-
위 그림을 보면 첫번째로 공유 layer에 를 넣습니다.
-
그러면 공유 layer는 raw 이미지 픽셀을 지각적으로 의미 있는 왜곡 관련 feature representation으로 변환합니다.
-
이 단계를 Convolution -> GDN -> Maxpooling 순으로 이루어진 layer를 4단계 통과한다.(Convolution의 채널 수와 커널, 패딩이 조금씩 다르다.)
-
공간의 크기는 2의 stride (혹은 padding이 없는)와 2x2의 최대 풀링을 가진 Convolution을 통해 각 단계 후 4의 factor만큼 감소합니다.
256 x 256 x 3 의 raw 이미지는 64차원의 feature 벡터로 표현됩니다.
네트워크 1
-
공유 layer 위에 네트워크 1은 비선형성을 증가시키기 위해 중간에 GDN 변환으로 fully-connected 된 두 개의 layer를 추가합니다.
-
네트워크 1은 범위를 [0,1]로 인코딩하는 softmax 함수를 통해 각 왜곡 유형의 확률 를 나타냅니다.
-
는 네트워크 2에도 공급됩니다.
-
하위 작업 1을 학습하기 위해 emprical cross entropy loss가 사용됩니다.
- 은 하위 작업 1의 weights입니다.
네트워크 2
-
네트워크 2는 네트워크 1의 공유 Convolution feature와 추정 확률 벡터 를 입력으로 사용합니다.
-
의 지각 품질을 스칼라 값 형태로 예측합니다.
-
두개의 fully-connected layer가 score 벡터 를 생성하는데 사용됩니다.
-
그러고 나서, 와 를 결합해서 전반적인 품질 점수를 산출하는 layer가 나옵니다.
- 확률 가중치의 합계는 단순한 구현으로 다음과 같습니다.
- 하위작업 2에서는 normalization을 사용합니다.
- 그러면 모든 loss는 아래와 같이 표현됩니다.
Training and Testing
-
MEON은 학습을 사전 학습 및 공동 최적화의 두 단계로 나눠 이 문제를 해결합니다.
-
사전 학습 단계에서 loss function은 다음과 같이 최소화됩니다.
- 공동 최적화 단계에서는 전체 loss function이 다음과 같이 최소화됩니다.
-
는 하위 작업 2의 weight입니다.
-
테스트시에는 이미지를 주고 256 x 256 x 3의 sub-image를 U의 stride으로 추출한다.
-
최종 왜곡 유형은 추출된 sub-image의 모든 예측된 왜곡 유형 중에 다수결로 계산됩니다.
-
마찬가지로 최종 품질 점수는 단순히 모든 예측 점수를 평균내서 얻습니다.
