CIFAR 10 - PyTorch를 사용하는 CNN
변역본 내가 보기 쉬울려고 정리한 글이다.
Training and Validation Datasets
- Training set : 모델을 훈련하며 loss 를 계산한다. 또 gradient desent 를 이용해서 모델의 weight 를 조정한다.
- Validation set : training 중에 모델을 평가하는것으로 hyperparamter 를 조정한다. (w 를 조정한다) 그리고 가장 좋은 모델을 선택한다.
- Test set : 모델 끼리 비교해서 최상의 정확도를 가진 모델을 뽑아낸다.
링크텍스트
이곳이 설명이 잘되어있다.

predefined vaildation 세트가 없기 때문에 우리는 작은 부분( 5000 이미지) 를
validation set 으로 둔다.
우리는 random _ split helper 메소드를 이용해서 같은 validation set 를 만든다. random number generator 를 위해 seed를 셋팅한다.
-- hyperparameter : 주로 알고리즘 사용자가 경험에 의해 직접 새팅하는 값이다.
- hidden unit :
- dropout : 과적합을 피하기 위한 정규화 기밥
- weight intialization : 가중치 초기화
데이터 분리 dataset split
비율을 따져서 분리한다는 의미이다.
우리는 이제 training / validation 을 위한 데이터 로더를 만들수 있다.
배치에 있는 데이터를 불러올수 있다는 의미이다.
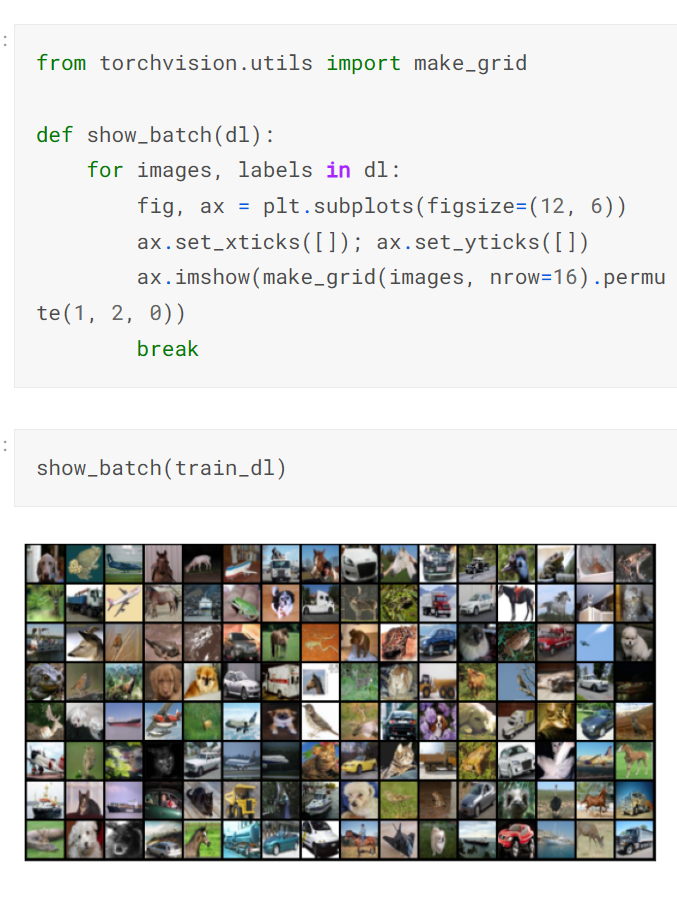
데이터 세트에 있는 배치 이미지를 make_Grid메소드를 이용해서 볼수 있따.
샘플러가 배치를 만들기 전에 지수를 섞기 때문에 다른 bach를 얻을 수 있습니다.
모델 정의하기 ( 컴불러션 뉴런 네으퉈크 (
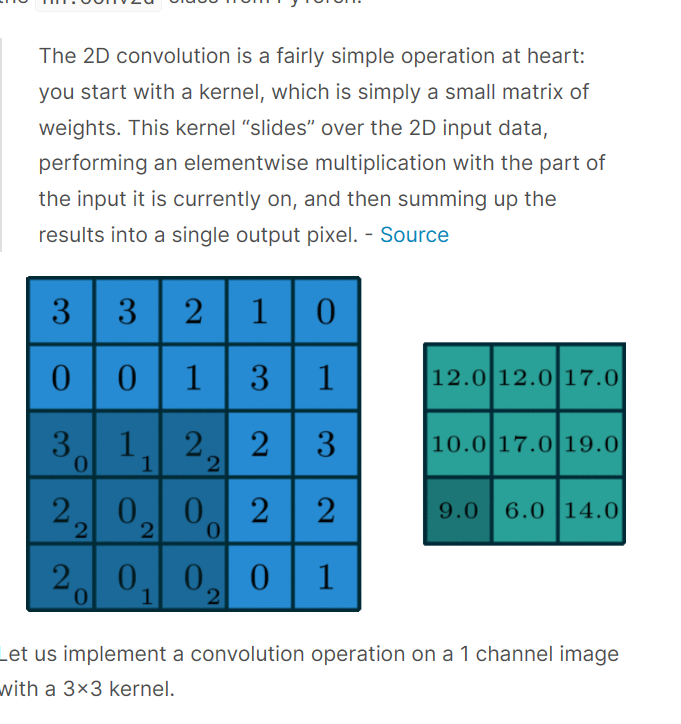
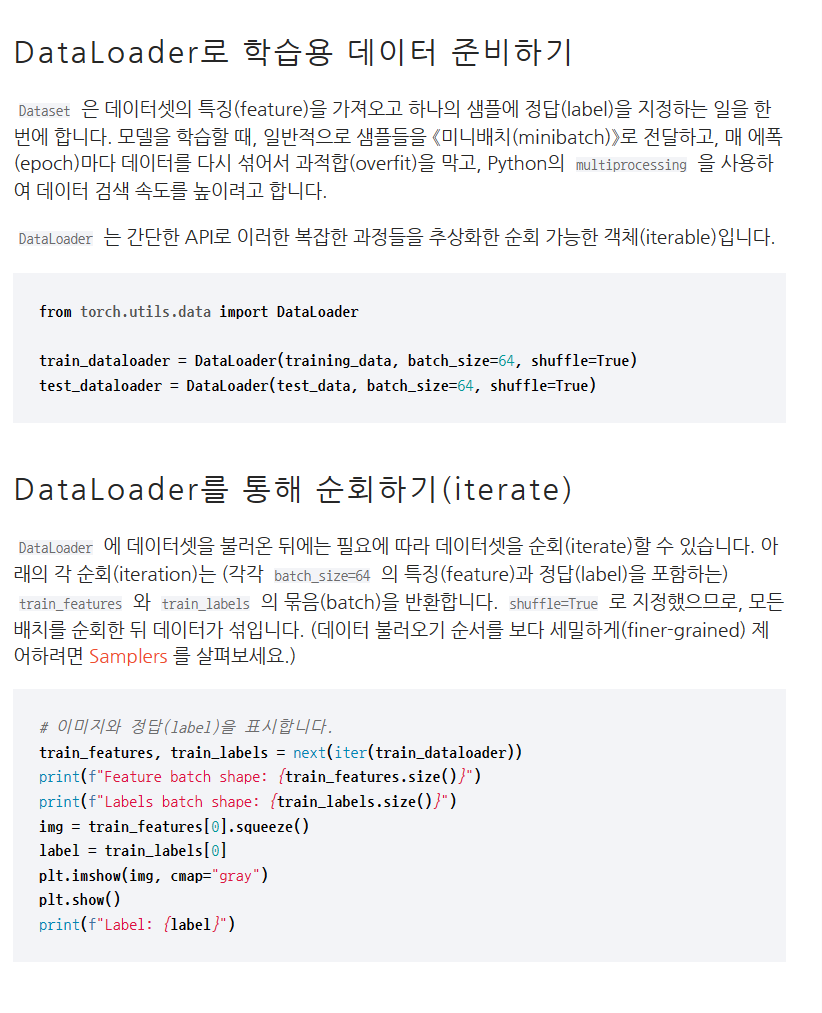
여기서 커널이란 (kernel) 은 == 필터라고 생각하면된다.

image.shape / kernel.shape를 통해 가로세로 길이 알아냄
output 디멘션의 길이를 구하고 0으로 셋팅한다 ( 초기셋팅)
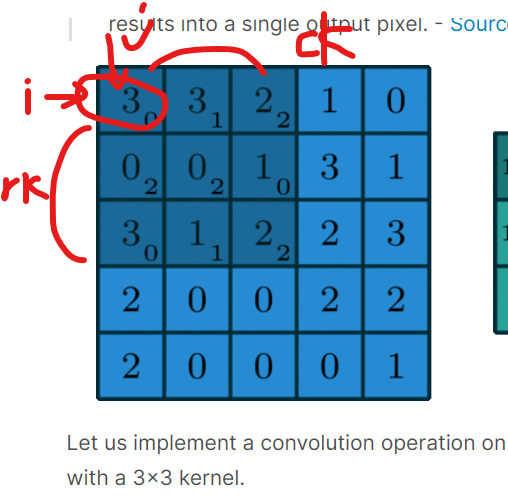
for 문을 두번 돌면서 계산해주면됨 여기서
멀티 채널 이미지를 위해서 각각의 다른 커널들이 각 채널에 적용된다.
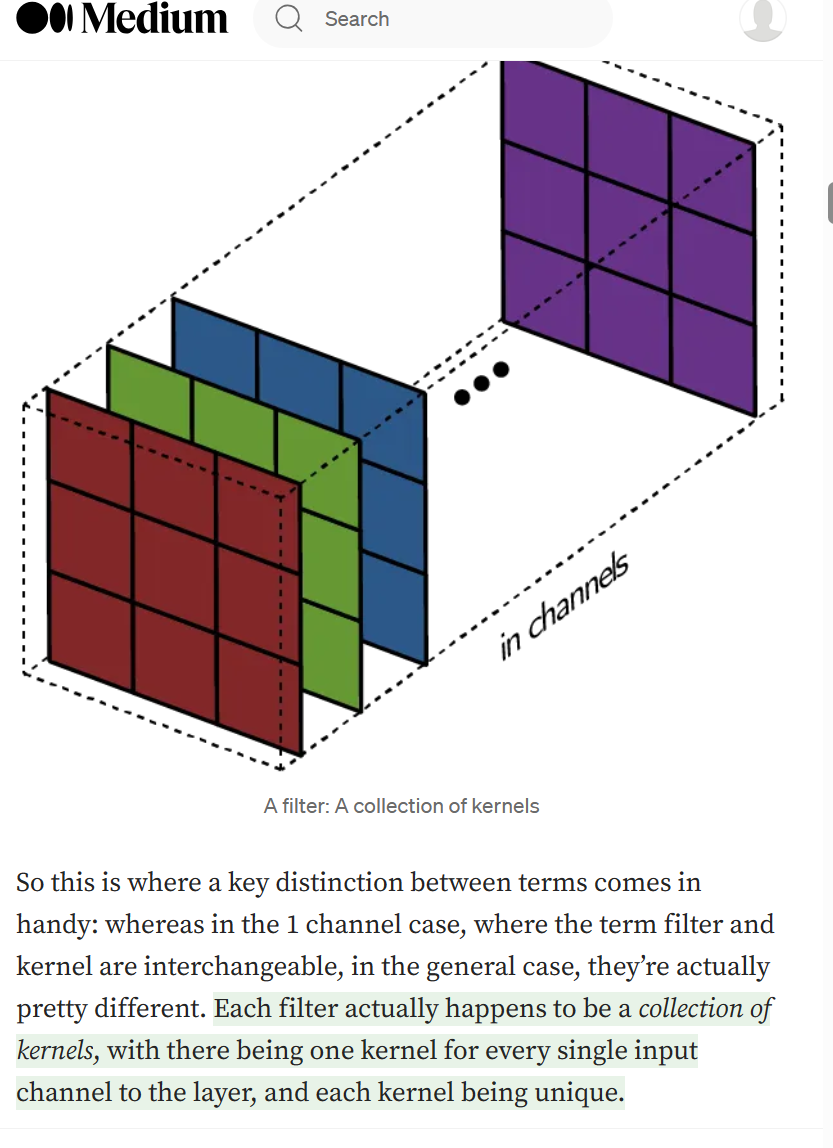
커널의 모음 == 필터라고 생각하슈
-
fewer parameter : parameter 의 작은 집합 전체 이미지를 계산하는데 사용된다.
-
sparsity of connection : 각 레이어에서 각 출력 요소는 적은 수의 입력 요소에만 의존하므로 전진 및 후진 패스가 더 효율적입니다.
-
prameter sharing and spatial invariance: 이미지의 한 부분에서 커널에 의해 학습된 특징은 다른 이미지의 다른 부분에서 유사한 패턴을 검출하는 데 사용될 수 있습니다.

simple_model 은 그저 형태만 지정한거다.
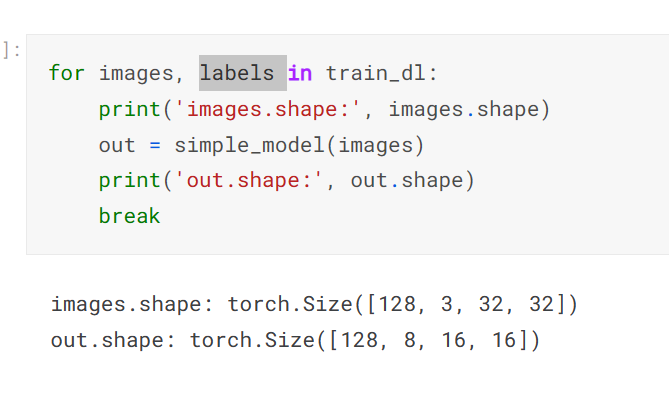
train_dl <-데이터 로드에서 가져온것
를 for 문을 톨려서 1배치 ... 끝까지 돌림 여기서 conv2d 를 해서 out 를 배출함
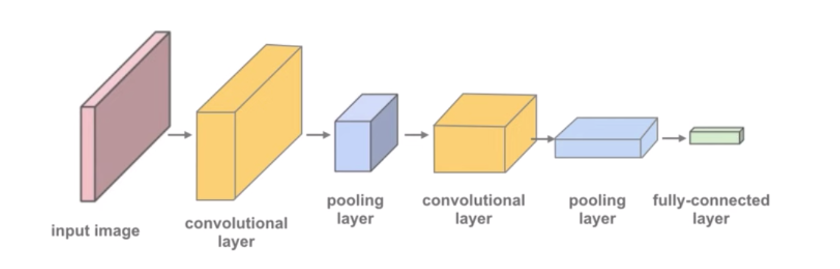
conv2d 레이어는 3- 채널 이미지를 16- 채널 feature map 으로 변화시켰다.
그리고 maxpool2s 레이어는 높이와 넓이를 반쪽으로 변형시켰다.
feature map 는 점점작아지기 때문에 결국 엄청 작은 feature 멥이 된다.
이것은 벡터를 납작하게 만들게 된다. 그런 다음 끝에 완전 연결된 레이어를 추가하여 각 이미지에 대한 크기 10의 벡터를 얻을 수 있습니다.
imageClassfication Base class
- 기존의 training validation 을 도와주는 클래스
이거 어렵슈

모델 생성

모델 트레이닝 하기
우리는 nn.sequential 를 통해 레이어를 체인화 하고 single netwwork 구조에 acitviationm function 을 넣어준다.
GPU 사용하기
모형이 훈련 데이터 배치에 대한 예상 출력을 생성하는지 확인합니다.
각 이미지에 대한 10개의 출력은 (softmax를 적용한 후) 10개의 타겟 클래스에 대한 확률로 해석할 수 있습니다,
가장 높은 가능성이 있는것은 모델의 이미의 라벨로서 예측됩니다.
gpu 를 사용해서 부드럽게 꼐산하기
GPU를 원활하게 사용할 수 있는 경우 몇 가지 도우미 기능(get_default_device &to_device)과 도우미 클래스 DeviceDataLoader를 정의하여 필요에 따라 모델과 데이터를 GPU로 이동합니다.

- gpu 가 가능하다면 선택하고 아니면 cpu 를 선택
- 선택된 디바이스로 tensor 를 이동시켜라
- dataloader 를 렙핑해서 데이터를 디바이스로 이동시켜라

for 문을 돌면서 x를 뽑아냄 > a에다가 넣음
을 한번에 하는것
for x in range(0,5) > 0, 1 , 2 , 3, 4 <- 이게 x인데
이 x를 a=[x] 이라고 생각해서 하면될듯

이 노트북을 실행하는 위치에 따라 기본 장치는 CPU(torch.device('cpu')) 또는 GPU(torch.device('cuda'))일 수 있습니다
이제 DeviceDataLoader를 사용하여 교육 및 검증 데이터 로더를 랩핑하여 데이터 배치를 자동으로 GPU로 전송하고(사용 가능한 경우)
to_device를 사용하여 모델을 GPU로 이동할 수 있습니다.

모델 트레이닝하기
gradinet 감소를 이용한 모델을 평가하고 vaildation set 에서 이것을 실행하여 평가한다. fit 과 evaluate 함수를 사용한다.
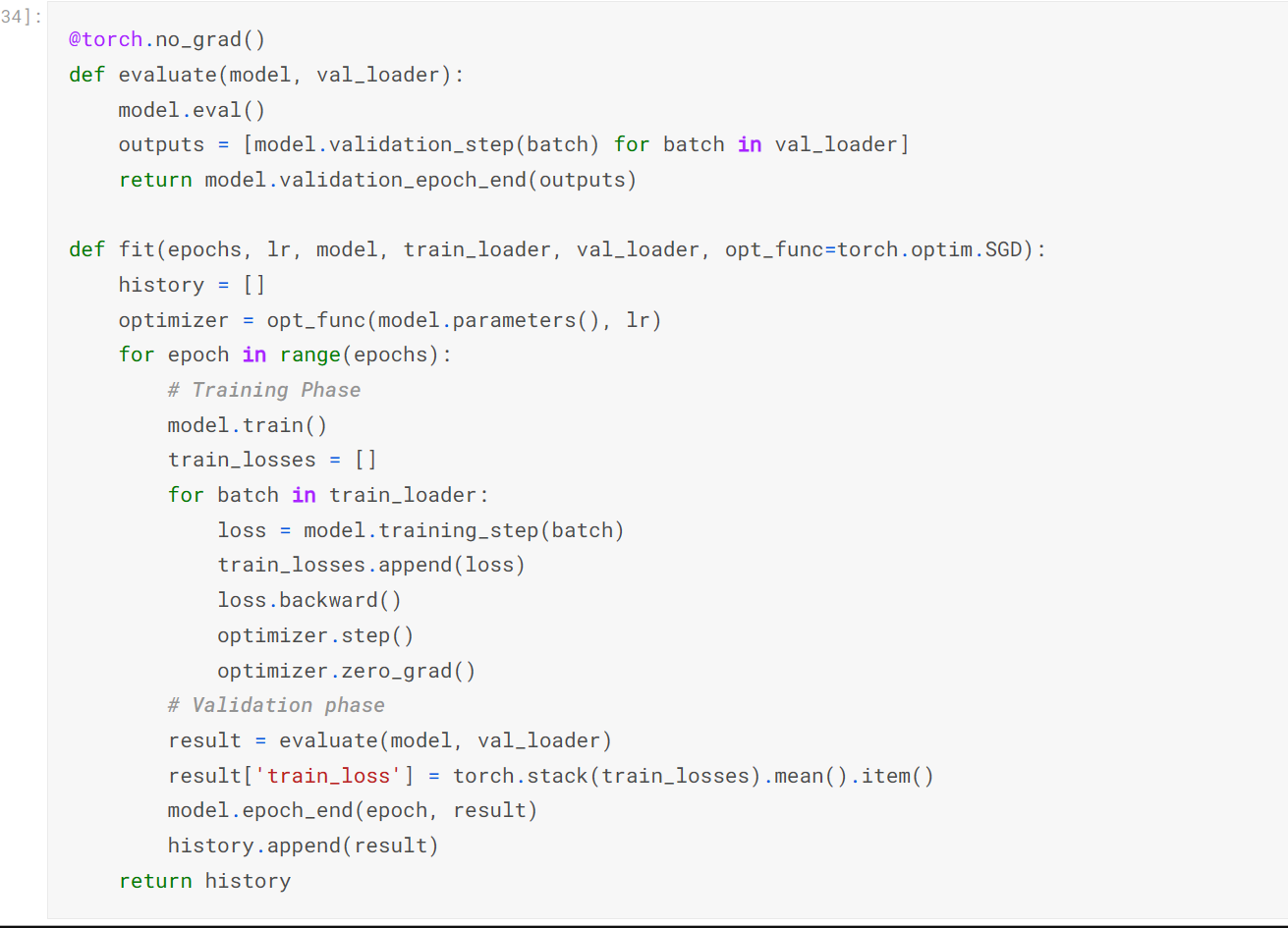
def evluate( 모델 , 로더 )
model.eval() <- 

model.validation_step( 배치 ) 를 통해 output 를 배출한다.
여기서 존재하는 out=self(images) 해석
우리는 class Cifar10CnnModel에 종속되어있다고 생각하면된다. 즉 self(images) 는 Cifar10CnnModel.forward 으로 연결되있고 return self.network(xb<- 여기에 images )
가 연결되어서 cnn 을 돌수 있따곳 .. 생각한다.
( 정확히 잘모르겟음 ) out=self(images) 니까
loss 와 acc 를 뽑아낸뒤
val_loss 에 loss 를 넣고 val_acc 에 acc를 넣고 return 한다.
torch.stack
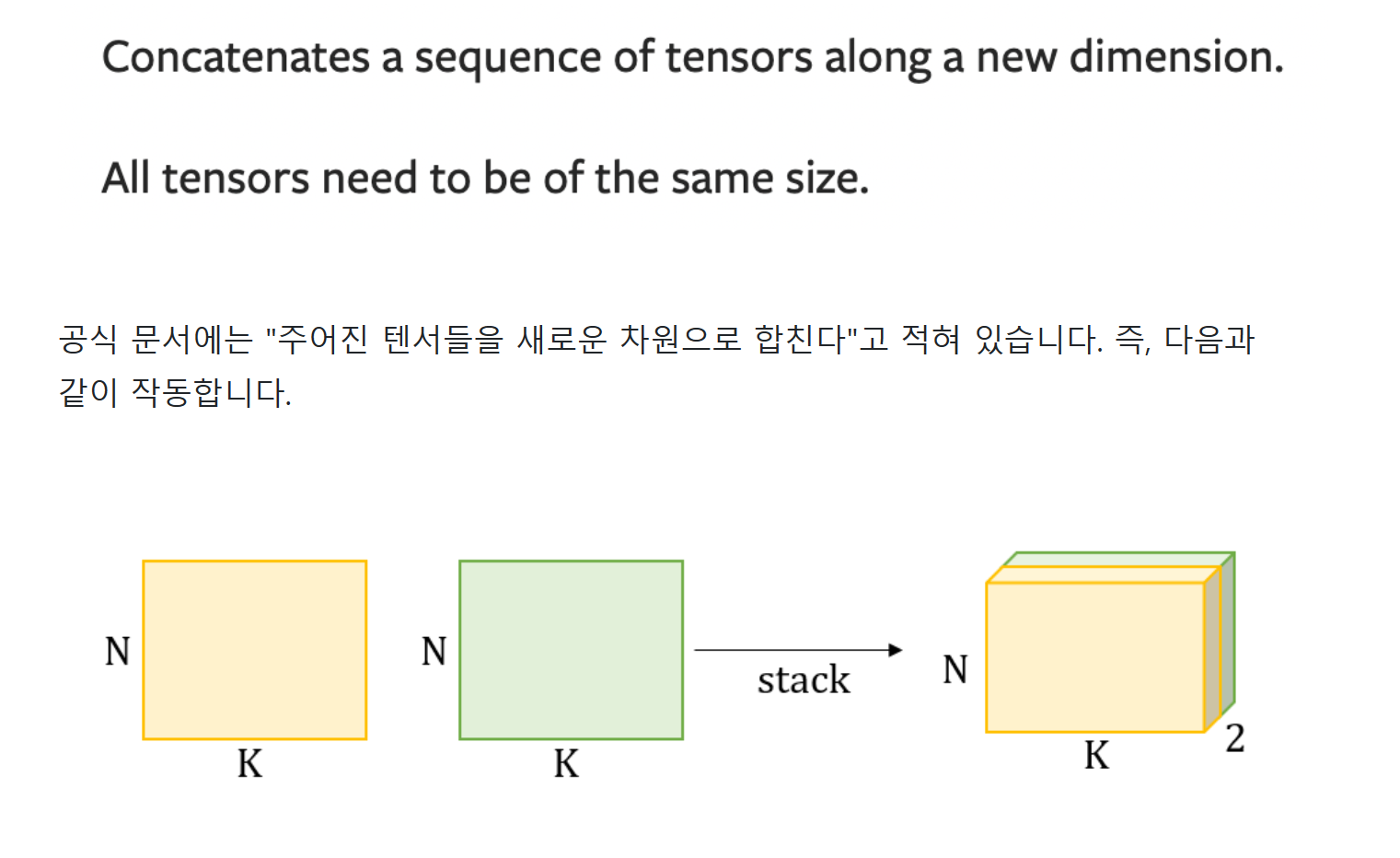
- epoch_loss 는 = batch_ioss 의 평균
- epoch_acc = batch_accs (정확도) 의평균을 구해서
return 한다.
batch 를통해 image, label 를 뽑애낸후

모델에 매개변수를 넣지 않았지만. 자동으로 parameter 가 넣어져 있는것을 확인할수 있다.

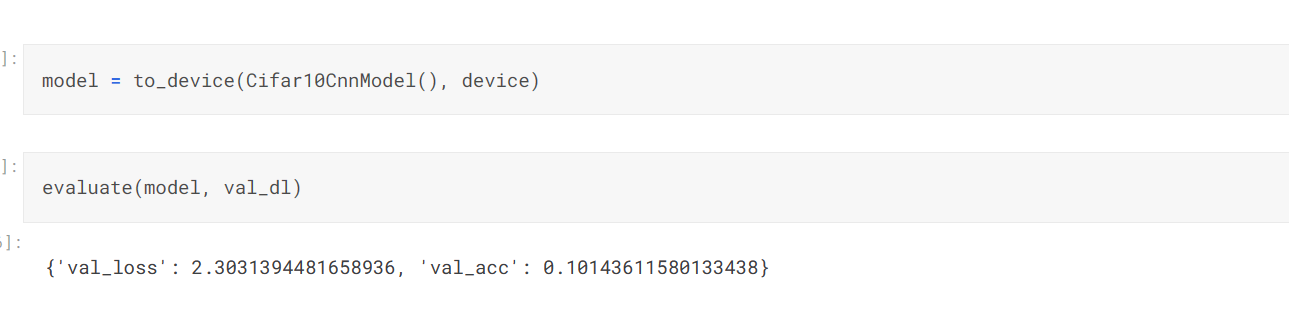
모델을 평가한다.
교육을 시작하기 전에 모델을 다시 한 번 인스턴스화하고 초기 매개 변수 집합을 사용하여 검증 세트에서 어떻게 작동하는지 알아보겠습니다.
초기 정확도는 약 10%이며, 이는 무작위로 초기화된 모델에서 기대할 수 있는 수준입니다(무작위로 추측하여 레이블을 정확하게 얻을 확률이 10분의 1이기 때문입니다).
높은 정확도를 얻기 위해 변화하기
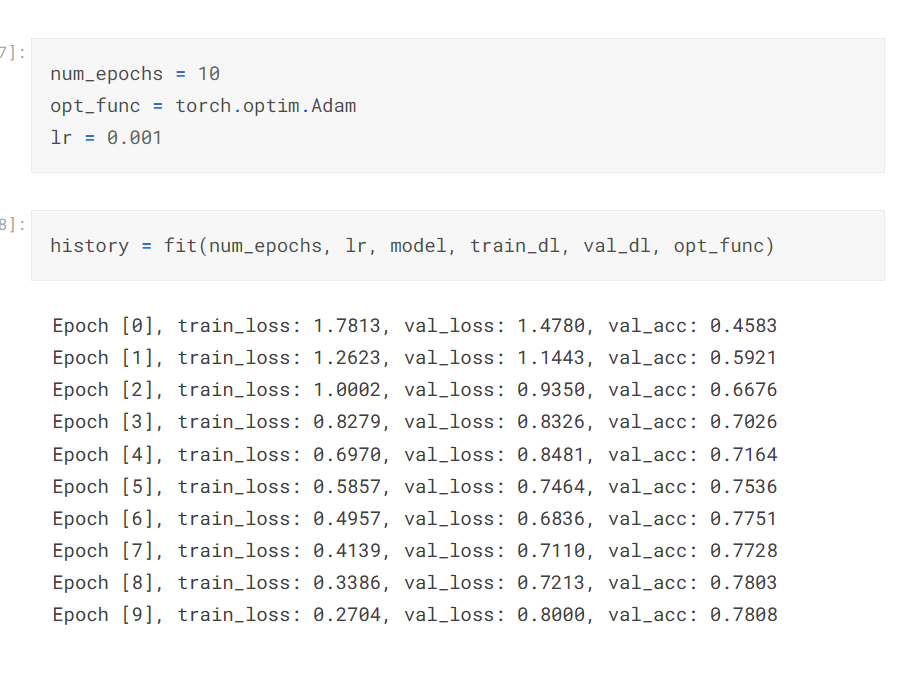
- history 배열 생성
- 주어진 함수 opt_func ( 매개변수로 불러옴 ) 을 이용해서 모델의 파라매터 옵티마이저
- 옵티마이저느 sgd 같은거 /여기서는 adam 을 사용하였다. (lr 는 학습률이다 )

- 에포크 크기 (10 번 수행하겠다 )
for 문으로 돌면서
model.train() 시킨다. ( 모델을 트레이닝 하겠다고 아렬준다고 생각)
{kind=link}
-
train_loader 에서 batch 하나씩 뜯어온다
-
traning_Set 을 이용해서 loss 를 구한다.
-
train_loss. 에다가 loss 붙이기
-
loss.backward() 배출된 loss 를 backward 시켜라 ( 파라미터 들의 에러에 대한 변화도를 계산하여 누적해라
-

한 배치해서 나온 결과를 evalute 함수에다가 넣어준다.
이때 변환된 모델과 val_loader 를 이용해서
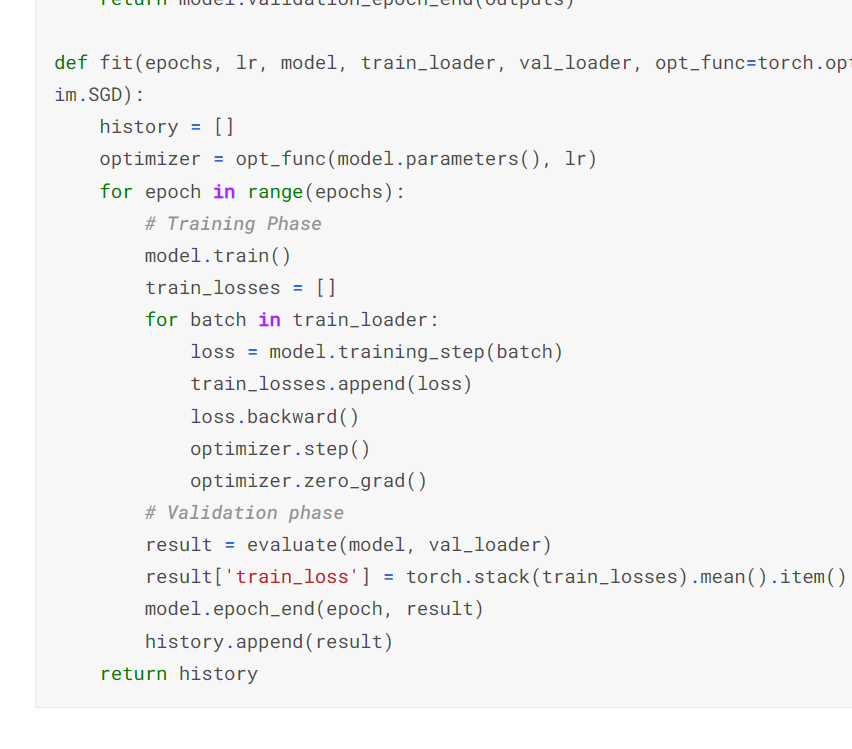
fit 의해석
- 모델을 트레이닝 하고
- 트레이닝해서 나온 결과
1) backward
2) opimizer 해줌 - 나온 결과를 토대로 평가 (evalute) 한다음

- return { }여기에 'train_loss' 라는 키 값에 =torch.stack(train_losses).mean().item() 위에서 넣어줬던 train_loss 값의 평균을 넣는다.

print 로 현재의 epoch / train_loss / val_loss / val_acc 를 보여준다.
현재까지 한 fit 값들의 히스토리를 보여준다.
이미지 testing 하기
