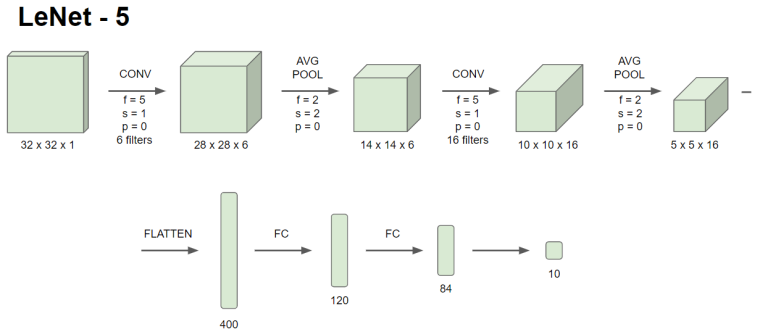
LeNet - 5
LeNey-5는 흑백으로 된 손글씨를 인식하기 위해 고안된 네트워크이다.
AlexNet
AlexNet은 1,000개의 3차원 컬러 이미지 클래스를 분류하기 위해 만들어 졌다. AlexNeta의 구조는 아래와 같다.

- 데이터 입력: 입력으로 227x227x3 크기의 이미지를 입력으로 받는다.
- LeNet-5와 유사하지만 훨씬 크기가 더 크다 LeNet-5의 경우 6만개 가량의 파라미터를 갖지만 AlexNet에 경우 6천만 개의 파라미터를 갖는다.
- 활성화 함수로 ReLu를 사용
VGG-16

vgg에서 주목할만한 점은 convolution layer에서 3x3 커널을 사용해 동일합성곱을 진행한다는 점이다. 이 방법을 이용하면 층을 깊게 쌓을 수 있다.
3x3커널의 장점
vgg-16은 합성곱 층에서 항상 3x3사이즈의 커널을 사용한다. 이전에 배운 AlexNet이나 LeNet에서 사용하는 11x11이나 5x5의 사이즈와 같은 커널을 사용하는 것과는 대비된다.
그렇다면 왜 3x3 커널을 사용하여 네트워크의 깊이를 늘리는 것이 어떤 장점이 있을까?
-
네트워크의 비선형성 증가
vgg에서 convolution layer는 convolution을 진행한 뒤에 활성화 함수(ReLu)를 거치는 데, layer가 증가할 수록 더욱 많은 활성화 함수를 거치고 이는 비선형 성의 증가로 이어져 모델의 특징 식별성이 증가한다. -
학습 파라미터 감소
만약 32x32 이미지에 대해 각각 7x7,3x3커널에 대해 합성곱을 하면 이미지 26x26 사이즈로 만드는 데 합성곱을 7x7은 1번, 3x3은 3번을 진행해야 된다.
파라미터의 개수로 본다면 49개와 27개로 3x3 커널로 3번 합성곱을 하는것이 파라미터의 개수가 적다.그러나 무작정 layer의 깊이를 늘리면 오히려 성능이 더 안좋을 수가 있다.

잘하자