딥러닝 혹은 머신러닝 모델들을 학습하려면 방대한 데이터가 필요하다. 파이토치에서는 데이터 셋을 쉽게 다룰 수 있도록 torch.utils.data.Dataset과 torch.utils.data.DataLoader를 제공한다.
모델에 데이터를 적용하는 과정
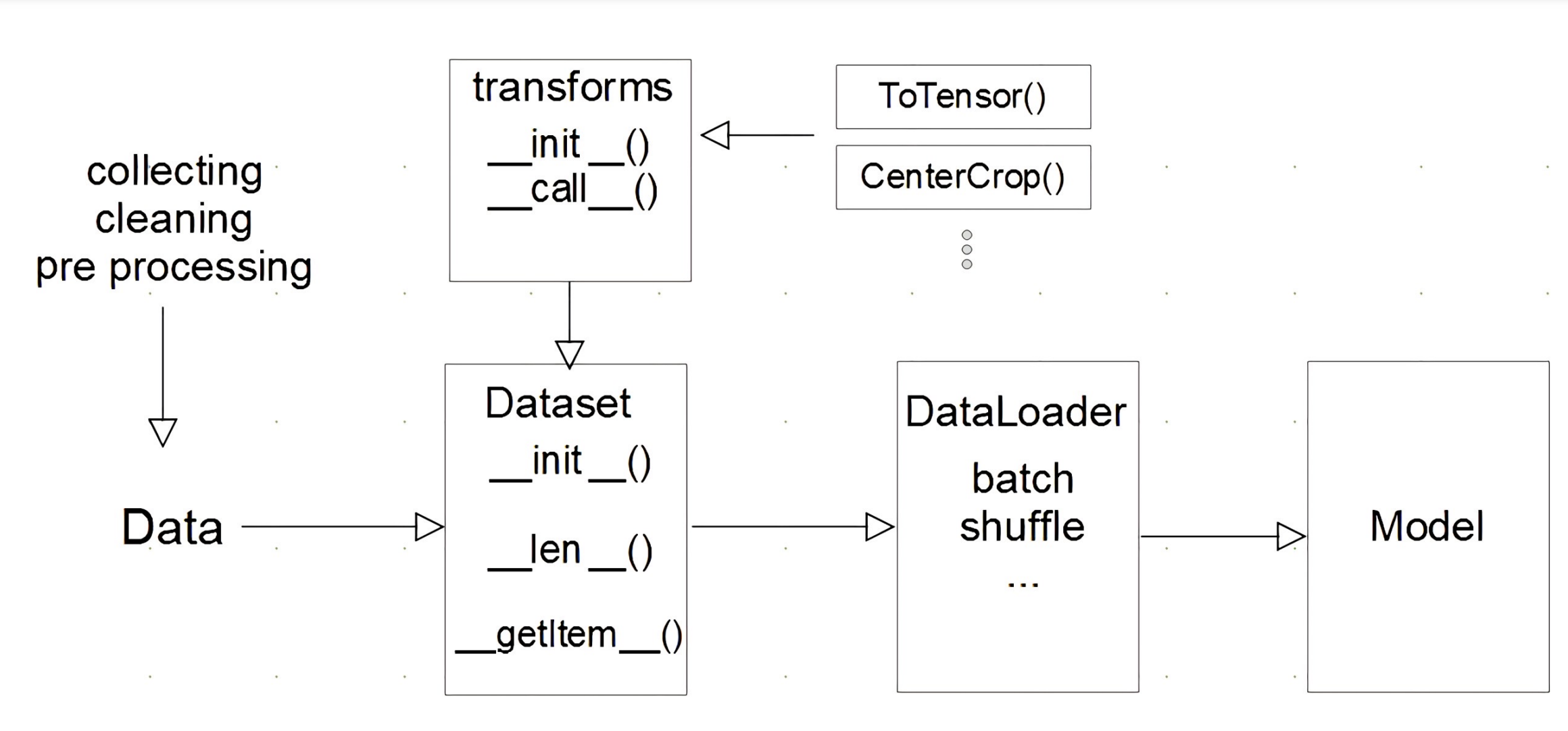
-
데이터 수집 및 전처리
-
Dataset에서 데이터를 불러오는 방식,map-style 선언
-
DataLoader에서 Dataset에서 나온 데이터를 묶어서 모델에 feeding
Dataset 클래스
데이터의 입력 형태를 정의하는 클래스이다. 이미지,텍스트, 오디오 등에 따른 입력을 정의한다
customDataset
모델을 학습하다 보면 torch.utils.data.Dataset을 상속 받아 직접 커스텀 데이터 셋을 만드는 경우가 종종 있다.
- 커스텀 데이터셋 예시
import torch
from torch.utils.data import Dataset
class CustomDataset(Dataset):
#초기 데이터의 생성 방법을 지정
def __init__(self,text,labels):
self.labels= labels
self.text = text
# 데이터의 전체 길이
def __len__(self):
return len(self.labels)
# index 값을 주었을 때 반환 되는 데이터의 형태
def __getitem__(self,idx):
label = self.labels[idx]
text = self.data[idx]
sample = {"text":text,"label":label}
return sample- Dataset클래스 생성시 주의 점
- 데이터의 형태 고려: 학습 하려는 데이터의 형태에 따라 각 함수를 다르게 정의해야한다
- 모든 것을 데이터 생성 시점에 처리할 필요는 없음
ex)이미지의 tensor 변화는 학습에 필요한 시점에 변환
DataLoader
앞서 말한 dataset의 경우 데이터 하나를 가져오는 방식을 정한다면, dataloader에서는 data를 묶는 방식을 정한다.
- Data의 Batch를 생성해주는 클래스
- 학습직전 (gpu feed 전) 데이터의 변환을 책임
- Tensor로 변환 + batch 처리가 메인 업무
- 병렬적인 데이터 전처리 코드 고민 필요
DataLoader 예시
MyDataset = CustomDataset(text,labels)
MyDataLoader = DataLoader(MyDataset,batch_size = 2,shuffle = 2)
for dataset in MyDataLoader: #DataLoader객체는 iterable객체이다.
print(dataset)#dataset은 Dataset 클래스의 __getitem__ 메소드가 반환하는 타입에따라 다르다DataLoader 파라미터

-
shuffle: 데이터를 섞을지 선택
-
sampler & batch_sampler: data를 어떻게 추출할지 data의 index를 반환
-
num_workers: 데이터를 불러올때 사용하는 서브프로세스의 개수
-
collate_fn: 데이터가 batch로 묶일 경우, 그 방식을 정하는 함수
-
pin_memory: cpu에서 pageable메모리를 거치지 않고 pinned메모리에서 바로 데이터를 읽을 수 있게한다.
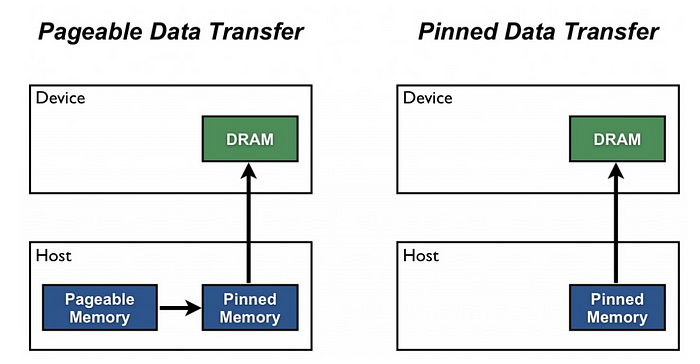
-droplast: 데이터를 batch단위로 불러 올때,batch_size에 따라 마지막 배치의 사이즈가 달라질 수 있는데 droplast = True이면 마지막 batch를 사용하지 않는다.
#data의 길이는 10이다.
for data, label in DataLoader(dataset_random, num_workers=1, batch_size=4):
print(len(data)) # 4,4,2
for data, label in DataLoader(dataset_random, num_workers=1, batch_size=4, drop_last=True):
print(len(data)) #4,4
collate_fn
앞서 본 DataLoader의 파라미터중 하나로 데이터의 사이즈를 맞추기 위해 많이 사용한다. 보통 map-style 데이터 셋에서 sample list를 batch 단위로 바꾸기 위해 필요한 기능이다.

class RandomDataset(Dataset):
def __init__(self, tot_len=10, n_features=1):
self.X = torch.rand((tot_len, n_features))
self.y = torch.randint(0, 3, size=(tot_len, ))
def __len__(self):
return len(self.X)
def __getitem__(self, idx):
x = torch.FloatTensor(self.X[idx])
y = self.y[idx]
return x, y
def collate_fn(batch):
print('Original:\n', batch)
print('-'*100)
data_list, label_list = [], []
for _data, _label in batch:
data_list.append(_data)
label_list.append(_label)
print('Collated:\n', [torch.Tensor(data_list), torch.LongTensor(label_list)])
print('-'*100)
return torch.Tensor(data_list), torch.LongTensor(label_list)
dataset_random = RandomDataset(tot_len=10)
next(iter(DataLoader(dataset_random, collate_fn=collate_fn, batch_size=4)))
출력결과 아래와 같이 배치 사이즈로 합쳐진 것을 볼 수 있다.
Original:
[(tensor([0.1153]), tensor(0)), (tensor([0.3840]), tensor(0)), (tensor([0.5922]), tensor(1)), (tensor([0.4657]), tensor(0))]
----------------------------------------------------------------------------------------------------
Collated:
[tensor([0.1153, 0.3840, 0.5922, 0.4657]), tensor([0, 0, 1, 0])]
----------------------------------------------------------------------------------------------------
(tensor([0.1153, 0.3840, 0.5922, 0.4657]), tensor([0, 0, 1, 0]))
zero-padding
class ExampleDataset(Dataset):
def __init__(self, num):
self.num = num
def __len__(self):
return self.num
def __getitem__(self, idx):
return {"X":torch.tensor([idx] * (idx+1), dtype=torch.float32),
"y": torch.tensor(idx, dtype=torch.float32)}dataset_example = ExampleDataset(10)
dataloader_example = torch.utils.data.DataLoader(dataset_example) # batch_size를 1로 하면 문제가 없다
for d in dataloader_example:
print(d['X'],d["y"])
-------------------------------------------------------------------------
#출력 결과(batch_size = 1)
tensor([[0.]]) tensor([0.])
tensor([[1., 1.]]) tensor([1.])
tensor([[2., 2., 2.]]) tensor([2.])
tensor([[3., 3., 3., 3.]]) tensor([3.])
tensor([[4., 4., 4., 4., 4.]]) tensor([4.])
tensor([[5., 5., 5., 5., 5., 5.]]) tensor([5.])
tensor([[6., 6., 6., 6., 6., 6., 6.]]) tensor([6.])
tensor([[7., 7., 7., 7., 7., 7., 7., 7.]]) tensor([7.])
tensor([[8., 8., 8., 8., 8., 8., 8., 8., 8.]]) tensor([8.])
tensor([[9., 9., 9., 9., 9., 9., 9., 9., 9., 9.]]) tensor([9.])
출력결과를 보면 배치사이즈를 1로 하면 문제가 없지만 2이상 부터는 배치 내부의 원소 차원이 일치하지 않아 오류가 발생한다. 오류를 해결하기 위해 collate_fn을 직접 정의하여 zero padding을 진행한다.
def my_collate_fn(samples):
collate_X = []
collate_y = []
l = len(samples)-1
batch_size -1만큼 차이가 난다.
for sample in samples:
zero_tensor = torch.zeros(l) #배치 내 원소 개수 최대 차이는 batch_size -1만큼 차이가 난다
t = torch.cat([sample["X"],zero_tensor],axis = 0)
collate_X.append(t)
collate_y.append(sample["y"])
l -= 1
return {"X":torch.stack(collate_X),
"y":torch.stack(collate_y)}
dataloader_example = torch.utils.data.DataLoader(dataset_example,
batch_size=2,
collate_fn=my_collate_fn)
for d in dataloader_example:
print(d['X'], d['y'])
출력결과
------------------------------------------------------------------------------------
tensor([[0., 0.],
[1., 1.]]) tensor([0., 1.])
tensor([[2., 2., 2., 0.],
[3., 3., 3., 3.]]) tensor([2., 3.])
tensor([[4., 4., 4., 4., 4., 0.],
[5., 5., 5., 5., 5., 5.]]) tensor([4., 5.])
tensor([[6., 6., 6., 6., 6., 6., 6., 0.],
[7., 7., 7., 7., 7., 7., 7., 7.]]) tensor([6., 7.])
tensor([[8., 8., 8., 8., 8., 8., 8., 8., 8., 0.],
[9., 9., 9., 9., 9., 9., 9., 9., 9., 9.]]) tensor([8., 9.])
