transfer learing(전이학습)이란 사전에 학습된 모델을 새로운 작업의 모델의 시작점으로 재사용하는 기계학습 기법이다. 이미지 분류로 예를 들면 사전에 학습된 DNN을 다른 데이터셋 혹은 다른 문제에 적용시켜 푸는 것을 의미한다. 이러한 전이학습을 이용하면 전이학습을 수행하지 않은 모델들 보다 비교적 빠르고 정확한 모델을 만들 수 있다.
전이학습이 앞에서 말한 효과를 낼 수 있었던 이유는 사전에 학습된 모델이 이미지의 low-level features(색상,edge...)같은 보편적인 이미지 특성을 학습 했기때문이다.
transfer learing 구현 준비
이제 파이토치에서 직접 transfer learing을 구현해 보는 것 실습한다. 실습하기 전에 알아 둬야할 것들이 있다.
model.save()
파이토치에서 제공하는 메소드로 학습의 결과를 저장하기 위한 함수 이다. 모델의 형태(architecture)와 파라미터 등을 저장한다. 모델 학습 중간 과정의 저장을 통해 최선의 결과 모델을 선택할 수 있다(early stop)
- 파라미터 저장 & 불러오는 법
model = TheModelClass()
#저장
torch.save(model.state_dict(),os.path.join(MODEL_PATH,"model.pt")) #.state_dict()를 이용하여 모델의 파라미터를 저장한다.
#불러오기
new_model = TheModelClass()
new_model.load_state_dict(torch.load(os.path.join(MODEL_PATH,"model.pt"))) #같은 모델 형태에서만 load가능
-------------------------------------------------------------------------------------
출력 결과
<All keys matched successfully> #모델이 같으면 성공 적으로 파라미터가 매치 된다- 모델 architecture 저장 & 불러오기
new_model = TheModelclass() #딥러닝 모델 생성
torch.save(new_model,os.path.join(MODEL_PATH,"model.pt")) #모델의 architecture 저장
model = torch.load(os.path.join(MODEL_PATH,"model.pt"))보통 결과값만 공유하는 경우가 많아 파라미터를 저장하고 불러오는 방식을 더 많이 사용한다.
checkpoints
- 학습 중간 결과를 저장하여 최선의 결과를 선택
- 일반적으로 epoch,loss,metric을 함께 저장하여 확인
- earlystopping 기법 사용시 이전 학습의 결과물 저장
for e in range(1, EPOCHS+1):
epoch_loss = 0
epoch_acc = 0
for X_batch, y_batch in dataloader:
X_batch, y_batch = X_batch.to(device), y_batch.to(device).type(torch.cuda.FloatTensor)
optimizer.zero_grad()
y_pred = model(X_batch)
loss = criterion(y_pred, y_batch.unsqueeze(1))
acc = binary_acc(y_pred, y_batch.unsqueeze(1))
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_acc += acc.item()
#checkpoint 코드 예시
# epoch,loss와 파라미터를 epoch가 한번 돌때마다 저장한다
torch.save({
'epoch': e,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': epoch_loss,
}, f"saved/checkpoint_model_{e}_{epoch_loss/len(dataloader)}_{epoch_acc/len(dataloader)}.pt")
print(f'Epoch {e+0:03}: | Loss: {epoch_loss/len(dataloader):.5f} | Acc: {epoch_acc/len(dataloader):.3f}')
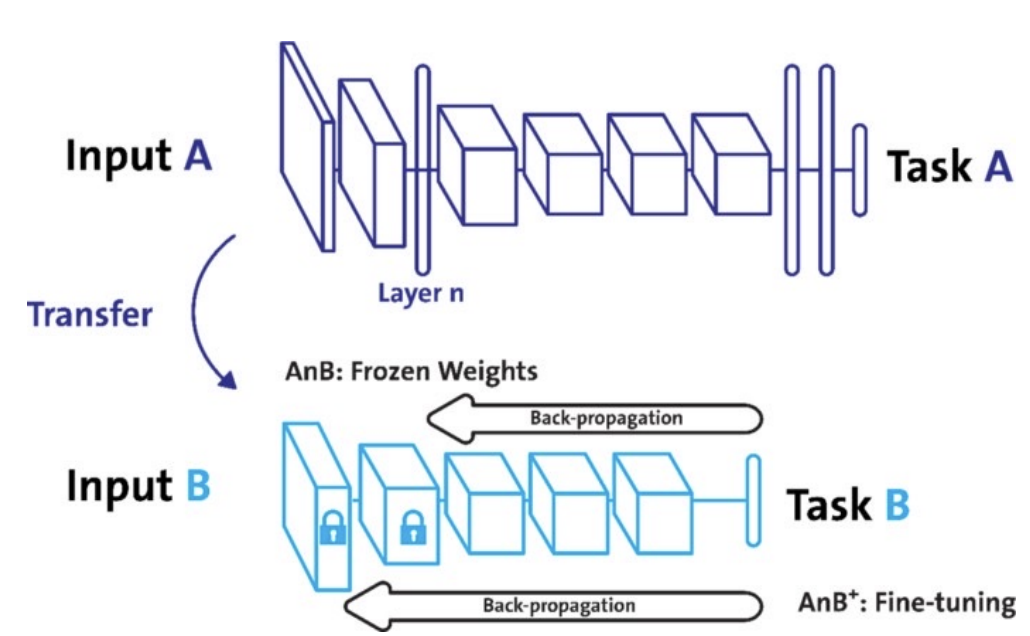
Freezing
pretrained model을 활용시 일부분을 frozen 시켜 frozen 되지 않은 층만 파라미터를 재학습 시킨다. 일반적으로 데이터가 적을 수록 frozen 되는 층이 깊다.
class MyNewNet(nn.Module):
def __init__(self):
super(MyNewNet, self).__init__()
self.vgg19 = models.vgg19(pretrained=True)
self.linear_layers = nn.Linear(1000, 1) #vgg 모델은 천개의 이미지를 분류하는 모델이므로 출력값이 1000개이다. 따라서 하나의 출력으로 변환시켜주는 linear layer를 하나 추가한다.
# Defining the forward pass
def forward(self, x):
x = self.vgg19(x)
return self.linear_layers(x)
my_model = MyNewNet()
for param in my_model.parameter(): # 마지막 레이어 제외 vgg의 모든층 freezing
param.requires_grad = False
for param in my_model.linear_layers.parameters():
param.requires_grad = True
잘하자