딥러닝을 학습할 시 가중치 초기화는 매우 중요하다. 가중치 초기화를 어떻게 하느냐에 따라 local minimum, 경사 소실,폭발 등 예방할 수 있다.
모든 가중치를 0으로 설정
- 모든 뉴런들의 출력값이 0이 된다.
- 결론적으로 여러개의 뉴런을 학습하는 것이 아닌 하나의 뉴런을 학습하는 결과를 갖게 된다
- backward시 모든 weight값이 똑같이 바뀌게 됨
가중치를 random으로 설정
- 0으로 초기화하는 것 보다 좋은 성능을 갖는다
- 하지만 활성화 함수를 sigmoid로 사용하는 경우 출력값이 0 또는 1으로 치우치게 된다.
- sigmoid의 경우 기울기가 0에 수렴하는 경사소실 발생 가능
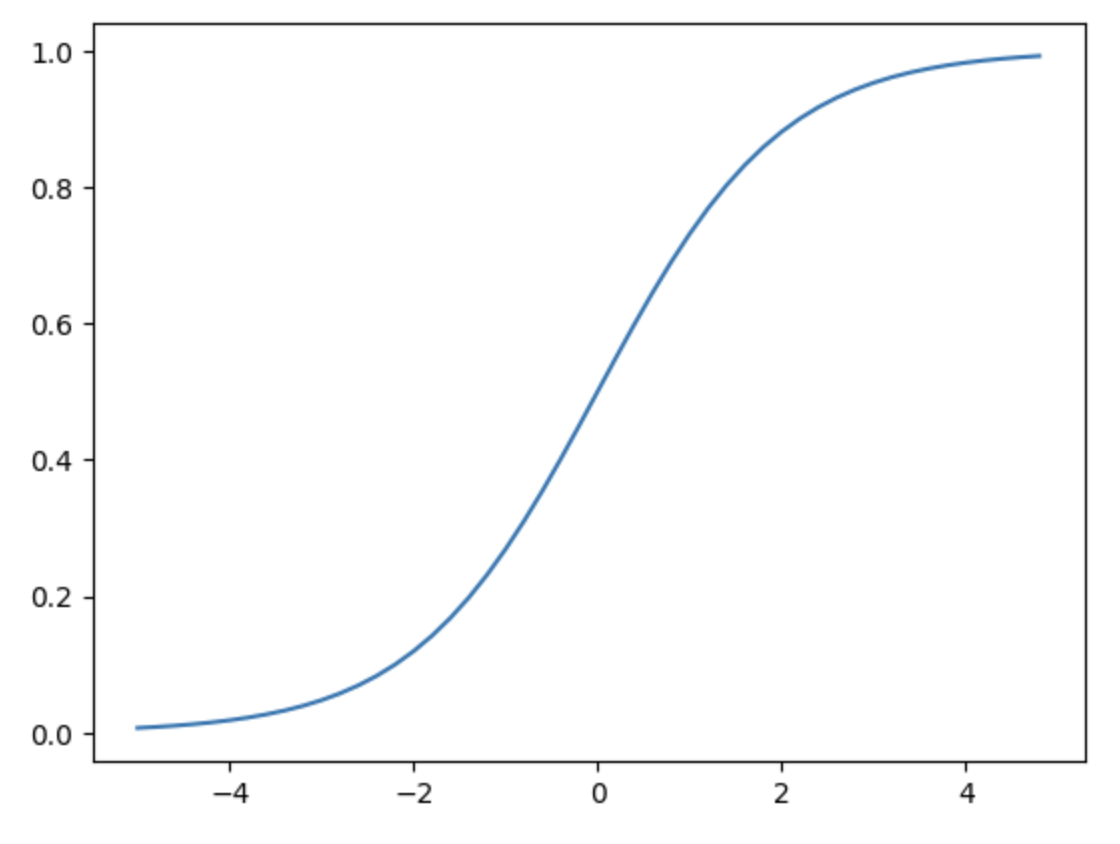
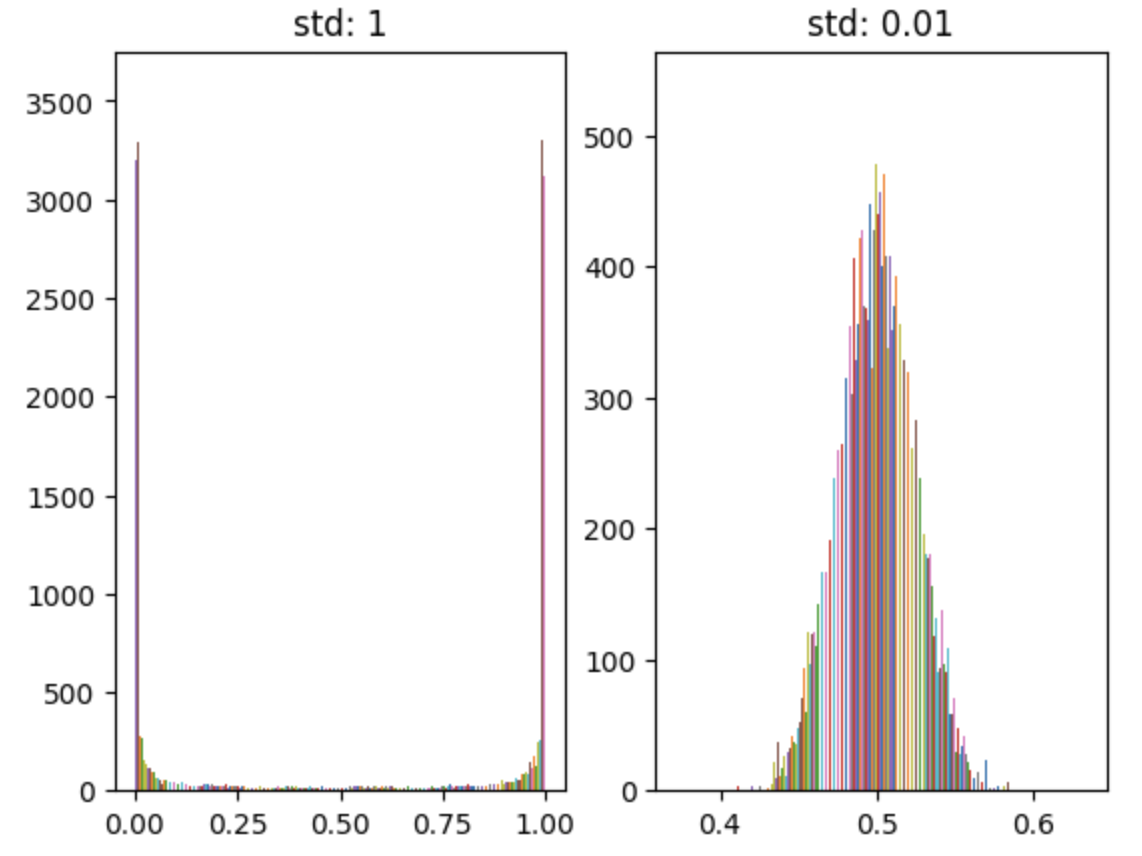
가중치를 정규분포를 따르도록 설정
가중치를 정규분포를 따르도록 설정하는 것은 좋은 방법이다. 하지만 편차에 따라서 경사 소실(gradient descent), 표현력 제한(zero-initiation과 같이 뉴런들의 값이 비슷한 값을 갖는것) 같은 문제가 생길 수 있다.
- 편차를 1로 설정할 경우 sigmoid함수에서 출력값이 0과 1에 치우치게 된다(경사소실).
- 편차를 작은값 (0.01)로 설정할 경우 sigmoid함수의 출력값이 에 치우친다
xavier 초기화
tanh,sigmoid함수를 활성화 함수로 사용할때 주로 사용한다. 이전 layer의 s뉴런의 수가 n개 라면 표준편차가 1/n**(1/2)인 분포를 사용한다
He 초기화
relu 함수에 최적화된 초기화 방법, 표준편차가 2/n**(1/2)인 분포를 사용.
xavier보다 분포가 넓어 기울기가 0이되는 출력값을 줄이는 효과가 있다.

잘하자