
📝 인공신경망(Artificial Neural Networks)
1. 인공신경망이란?
기계학습과 인지과학에서 생물학의 신경망(뇌)에서 영감을 얻은 통계학적 학습 알고리즘이다.
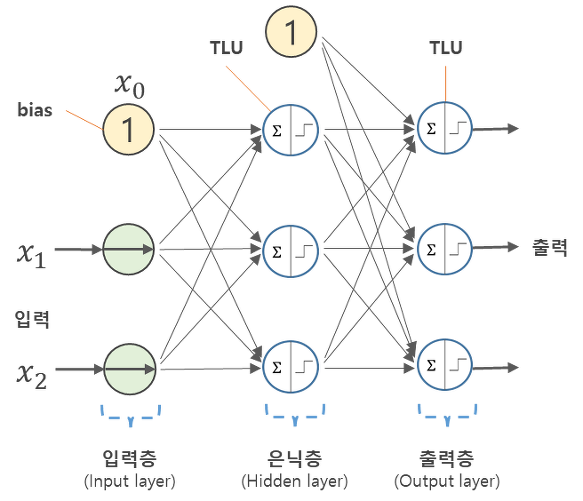
2. 퍼셉트론이란?
뇌 신경망의 작은 구조인 뉴런(Neuron)을 모사한 인공 뉴런으로 다수의 신호를 입력으로 받아 하나의 신호를 출력한다. 신경망(딥러닝)의 기원이 되는 알고리즘이다.
🔎 더 알아보기
Neuron: 신경계를 구성하는 세포이며, 전기적 및 화학적 신호를 통해 정보를 처리하고 전송한다.3. 신경망 구조
-
Input layer
데이터셋으로부터 입력을 받는 층이며, 어떤 계산도 수행하지 않고 그냥 값들을 전달하기만 하는 특징을 가지고 있다.
신경망의 층수(깊이, depth)를 셀 때 입력층은 포함하지 않는다 -
Hidden layer
입력층과 마지막 출력층 사이에 있는 층이며, 계산의 결과를 사용자가 볼 수 없다.(hidden)
딥러닝은 두 개 이상의 은닉층들을 가진 신경망을 의미한다. -
Output layer
처리된 결과가 출력되는 층이며, 노드개수나 모양에 따라서 모델의 정의가 달라질 수 있고, 대부분 활성화 함수가 존재한다. -
활성화함수(Activation function)
입력 신호의 총합을 출력 신호로 변환하는 함수이며, Sigmoid, ReLU, Softmax 등이 있다.
보통은 은닉층에는 ReLU를 사용하고, 출력층에는 Sigmoid, Softmax를 사용한다.
- 회귀 문제: 예측할 목표 변수가 실수값인 경우 활성화함수가 필요하지 않으며 출력노드의 수는 출력변수의 갯수와 같다.
- 이진 분류 문제: 시그모이드(sigmoid) 함수를 사용해서 출력을 확률 값으로 변환하여 부류(label)를 결정한다.
- 다중클래스 분류 문제: 출력층 노드가 부류 수만큼 존재하며 소프트맥스(softmax) 함수를 활성화 함수로 사용한다.-
손실함수(Loss function)
실제값과 예측값의 차이를 수치화해주는 함수이다.
오차가 클수록 손실 함수의 값이 크고, 오차가 작을수록 손실 함수의 값이 작아진다.
다중 분류 = categorical_crossentropy 혹은 sparse_categorical_crossentropy
이진 분류 = binary classification loss function -
iteration
1-epoch를 마치는데 필요한 미니배치 갯수를 의미하며, 이 단위의 반복이 일어나면서 모델이 점점 좋아진다. -
epoch
모든 학습 데이터셋을 학습하는 횟수를 의미한다.
AND GATE
입력신호가 모두 1일 때 1을 출력한다.

NAND GATE
AND gate의 결과의 반대, Not AND로 입력신호가 모두 1일 때 0을 출력한다.
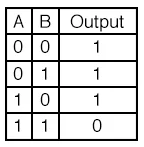
OR GATE
입력신호가 하나만 1이어도 1을 출력한다.
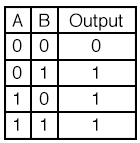
XOR GATE
입력신호가 다를 때 1을 출력한다.
AND(NAND(x1, x2), OR(x1, x2))
3. 머신러닝과 딥러닝 차이점은 무엇인가?
머신 러닝은 학습 데이터를 수동으로 제공하고,
딥러닝은 분류에 사용할 데이터를 스스로 학습할 수 있다.(representation learning)
4. 역전파(Back Propagation)란 무엇인가?
출력된 벡터와 타깃값을 비교한 뒤에 오차를 계산하고, 역방향으로 오차를 전파시키면서 각 가중치를 갱신하는 과정이다.
5. 편미분이란 무엇인가?
편미분이란 다변수 함수의 특정 변수를 제외한 나머지 변수를 상수로 생각하여 미분하는 것이다. 미분을 사용하는 이유는 오차를 줄여나가 신경망의 최적의 매개변수(가중치,편향)를 찾아가기 위해서이다. 이를 통해 가중치의 매개변수에 대한 손실 함수의 기울기를 구할 수 있다.
6. 모델 학습 시 과적합(Overfitting)을 극복하기 위한 방법은? (regularization 전략)
1. Early stopping
관찰 항목에 대해 개선이 없다고 판단할 경우 학습 조기 종료
2. Dropout
은닉층에서 일부 노드를 사용하지 않고 학습하는 것(like 앙상블)
3. Weight decay
손실 함수에 가중치와 관련된 항을 추가하여 weight 학습 반경을 조절
4. Weight constraint
weight의 범위를 지정하여 weight 크기를 제한
7. 가중치 초기화 (Weight Initialization)
모델의 초기 정확도에 큰 영향을 끼치며, 신경망 모델의 성능을 좋게하는 요인 중 하나이다.
Zero initialization, Random Initialization, Xavier Initialization, He Initialization 등이 있다.
📝 Code Review
32개의 노드를 가진 입력층,
64개, 256개의 노드를 가진 각 1개(=총 2개)의 은닉층,
5개의 클래스로 구성된 데이터를 가진 신경망
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model = Sequential([
Dense(64, activation='sigmoid', input_dim=32),
Dense(256, activation='sigmoid'),
Dense(5, activation='softmax')
])
model.compile(optimizer='sgd', loss='sparse_categorical_crossentropy', metrics=['acc'])
results = model.fit(X,y, batch_size=batch_size, epochs=100)