thandbag 프로젝트에서 구현한 검색기능은 다음과 같다.
검색 키워드가 유저 닉네임, 타이틀, 또는 게시글 내용중에 하나라도 포함 되어 있다면 해당 게시글을 반환
Thandbag 프로젝트에서 처음에 검색기능을 하기위해 java contains 메소드를 사용하여 키워드 필터링을 구현하였다. 기능은 정상적으로 구현하였으나, 필터링을 위해서 arraylist에서 String의 contains 메소드로 검색 키워드가 포함되지 않은 글들을 remove하는 식으로 구현했는데 remove가 O(N)이기 때문에 필터링 속도가 거의 O(N^2)에 가까웠을것 같다. 차라리 새로 리스트를 만들어서 포함하는내용을 arraylist의 add 메소드로 옮기는게 더 나았을 것 같다. 현재 설명대로 구현한 검색 기능의 코드는 다음과 같다.
contains를 사용하여 검색 구현
// 검색된 생드백 전체 리스트 페이지로 만들기
public List<ThandbagResponseDto> searchThandbags(String keyword, int pageNumber, int size) {
List<Post> posts = postRepository.findAllByShareTrueOrderByCreatedAtDesc();
// 키워드가 유저 닉네임, 타이틀, 또는 게시글 내용에 포함되지 않았으면 삭제
posts.removeIf(post -> !(userRepository.getById(post.getUser().getId()).getNickname().contains(keyword)
|| post.getContent().contains(keyword) || post.getTitle().contains(keyword)));
//페이징 처리
PagedListHolder<Post> page = new PagedListHolder<>(posts);
page.setPageSize(size);
page.setPage(pageNumber);
posts = page.getPageList();
//dto 변환
List<ThandbagResponseDto> searchedPosts = new ArrayList<>();
for (Post post : posts) {
ThandbagResponseDto thandbagResponseDto = createThandbagResponseDto(post);
searchedPosts.add(thandbagResponseDto);
}
return searchedPosts;
}100개정도의 데이터가 있었는데 postman으로 테스트를 해본결과
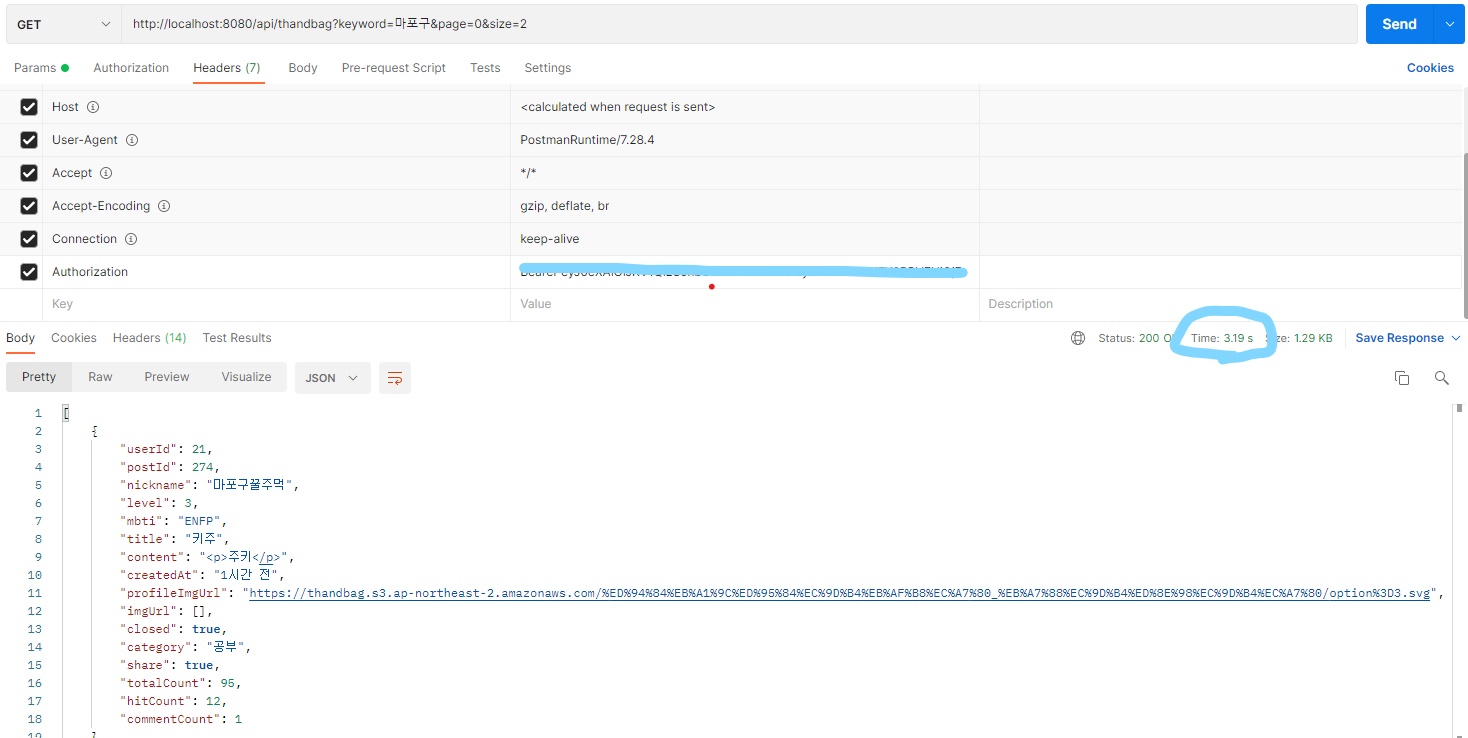
3.19s로 굉장히 느렸다..
다음은 같은 검색기능을 JPA의 쿼리 메소드를 사용하여 구현을 해주었다.
postRepository에 쿼리 메소드 구현
public interface PostRepository extends JpaRepository<Post, Long> {
//닉네임, 게시글 제목, 게시글 내용 안에 키워드가 포함되는 글들을 리턴
@Query(value = "select p from Post p where p.share = true and (p.title like %:keyword% or p.content like %:keyword% or p.user in (select u from User u where u.nickname like %:keyword%))")
Page<Post> findAllByShareTrueAndContainsKeywordForSearch(@Param("keyword") String keyword, Pageable pageable);
}해당 쿼리 메소드를 서비스에서 호출하여 구현하였다.
querymethod를 사용하여 검색 구현
// 검색된 생드백 전체 리스트 페이지로 만들기
public List<ThandbagResponseDto> searchThandbags(String keyword, int pageNumber, int size) {
Pageable sortedByModifiedAtDesc = PageRequest.of(pageNumber, size, Sort.by("modifiedAt").descending());
List<Post> posts = postRepository.findAllByShareTrueAndContainsKeywordForSearch(keyword, sortedByModifiedAtDesc).getContent();
//dto 변환
List<ThandbagResponseDto> searchedPosts = new ArrayList<>();
for (Post post : posts) {
ThandbagResponseDto thandbagResponseDto = createThandbagResponseDto(post);
searchedPosts.add(thandbagResponseDto);
}
return searchedPosts;
}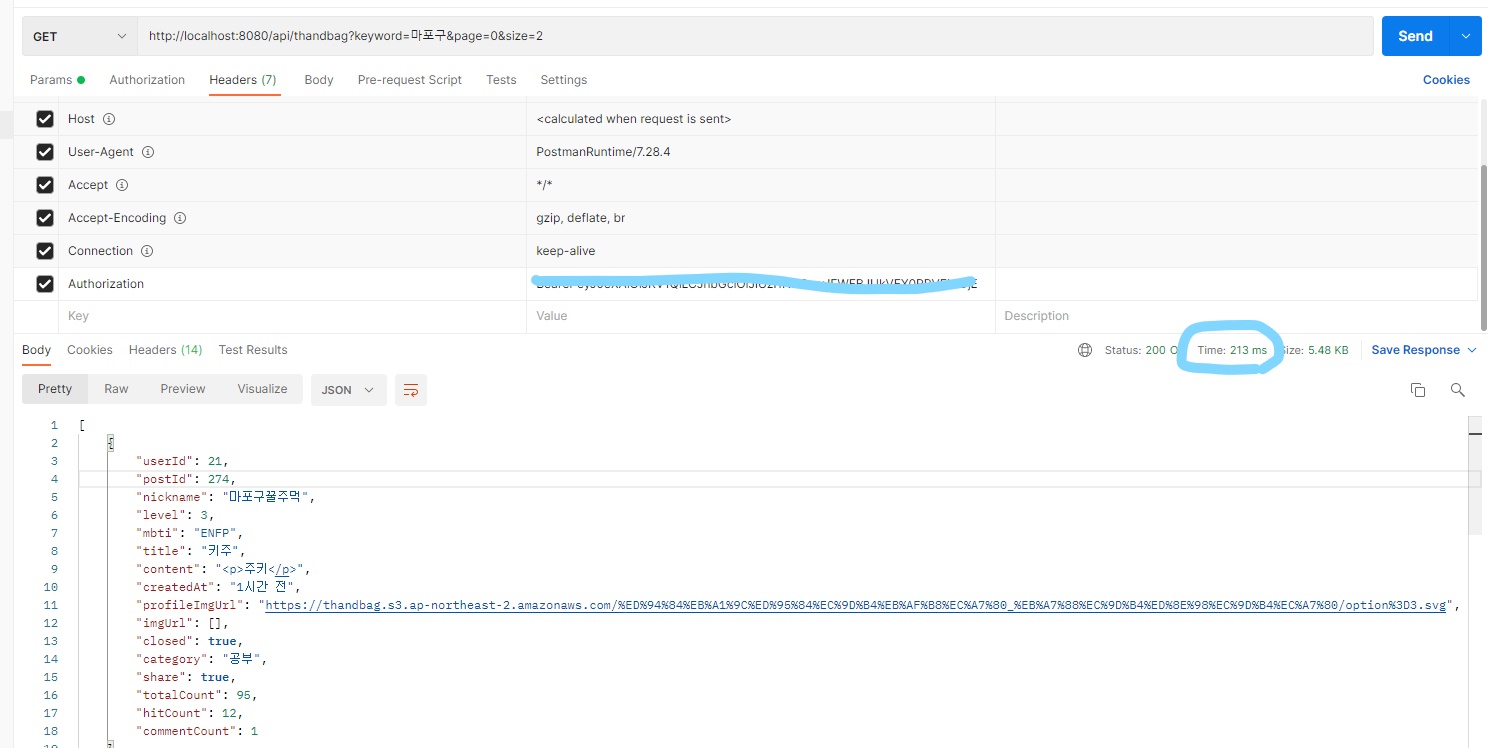
결과를 확인해보니 213ms로 10배이상 빨라진것을 확인할 수 있었다.
당연히 java contains메소드를 사용한것 보다는 속도가 빨라지긴했으나, 위 쿼리문 처럼 user 테이블에 대한 서브쿼리를 구현하게 되면, user 테이블과 post테이블 모두에 fullscan이 발생한다.
fetch join으로 fullscan을 한번으로 줄임
어차피 user 테이블에는 게시글을 전혀 쓰지 않은 유저도 다수 있기 때문에 검색어 입력시 굳이 확인할 필요없는 유저데이터까지 확인한다. 불필요한 데이터확인과 fullscan을 줄이기 위해 post테이블과 user테이블을 fetch join 시켜서 쿼리가 한번만 실행되도록 최적화 하였다.
@EntityGraph(attributePaths = {"user"})
@Query(value = "select p from Post p where p.share = true and " +
"(p.title like %:keyword% or p.content like %:keyword% or " +
"p.user.nickname like %:keyword%)")
Page<Post> findAllByShareTrueAndContainsKeywordForSearch(
@Param("keyword") String keyword, Pageable pageable);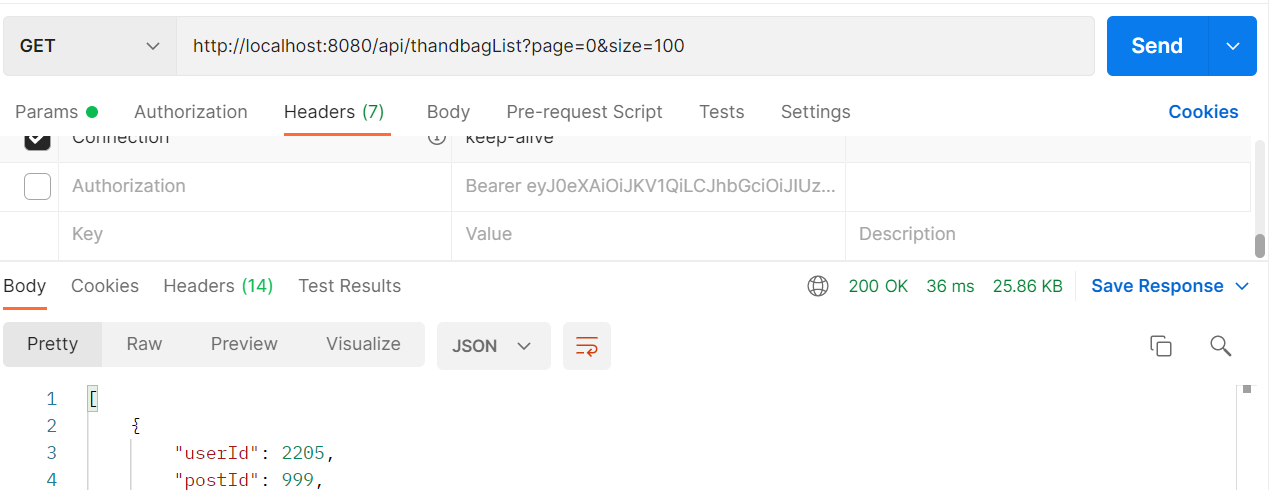
postman으로 응답속도를 확인해보니 36ms로 5배이상 더 빨라진것을 확인할 수 있었다.
ElasticSearch의 활용
멘토링에 따르면 SQL의 와일드카드 Like를 사용하는것도 현업에서 트래픽이 높아지면 Elasticsearch로 다시 성능 개선을 해주어야 한다고 들었는데, 현재 수준의 프로젝트에서는 overengineering이라고 판단하여 일단 넘어가고 추후에 다시 공부해서 개선시켜보기로 했다.
