Natural Language Processing 모듈 학습 블로그 과제
이번 NLP 모듈에서는 Dialogue Summarization 경진대회를 목표로 LM과 LLM을 학습하였다.
이번 블로그에서는 경진대회를 준비하기 위해서 준비했던 시행착오와 뛰어난 성과를 낼 수 있었던 LLM에 대해서 내용을 정리해 보겠다.
목차
1. 일상대화 요약 경진대회
2. LLM 강의 내용 정리
1.일상대화 요약 경진대회후기
우리 팀은 다양한 언어 모델(LM)과 대규모 언어 모델(LLM)을 활용하여 대화 요약 과제에 도전했다. 대회 경험과 주요 전략, 그리고 얻은 교훈들을 공유하고자 한다.
대회 개요
-
과제: 2~7인의 2~60턴 대화문을 요약하는 것이었다.
-
데이터셋: 학습 데이터 12,457개, 평가 데이터 499개가 제공되었다.
-
평가 지표: ROUGE-1-F1, ROUGE-2-F1, ROUGE-L-F1 점수의 평균을 사용했다.
-
팀 구성 및 역할
민경도: 팀장, LM 튜닝, LLM 실험, 모듈화, 자동화, 모델링, 2차 모델, 앙상블
전승열: LM 모델 선택, LLM Prompting, LLM FineTuning, Testset 보정 모델링
이진영: Baseline 튜닝, Optuna 활용 Optimization, Trainset augmentation, 모델링
조진우: EDA, 데이터 전처리, LM 실험, Trainset augmentation, 모델링
-
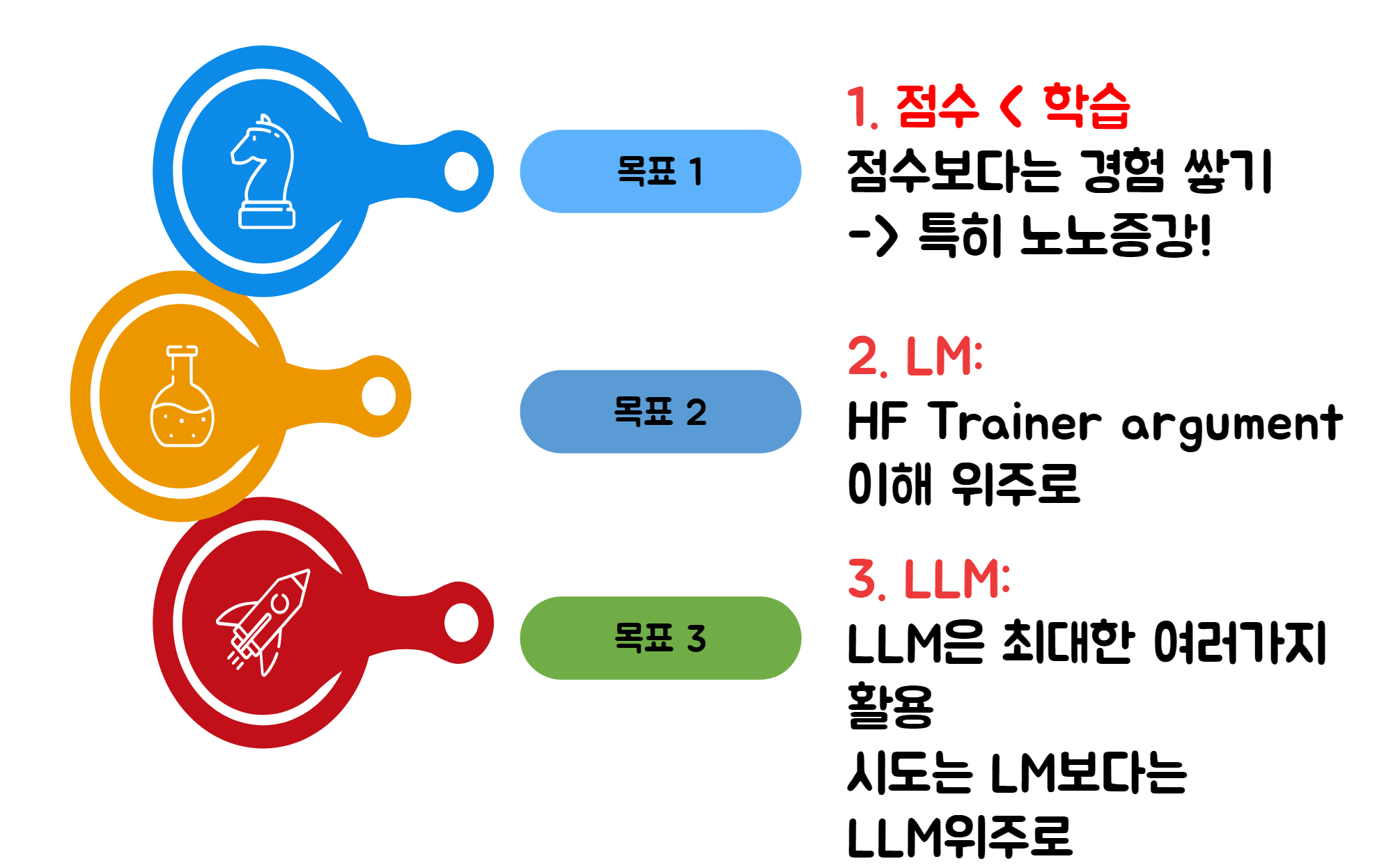
대회 목표
점수보다는 경험 쌓기에 집중
HuggingFace Trainer argument 이해에 중점
LLM을 최대한 다양하게 활용, LM보다는 LLM 위주로 시도

-
EDA (탐색적 데이터 분석)
데이터 길이 분석: Dialogue, Summary, Topic의 평균/최소/최대 길이 확인
이상치 분석 및 처리: Dialogue, Summary의 길이 이상치는 모델 max_length 설정으로 제한, Topic 길이 이상치는 Top3만 정제
Topic 분석: Top 20 Topic 확인, 불균형 문제 발견 (일상 대화, 쇼핑 등)
TF-IDF & WordCloud: Mecab.noun(text)를 이용한 주요 단어 추출 및 시각화 -
데이터 정제
특수 문자 오류 처리: 문맥에 따른 수정 여부 결정
Control Character 오류 처리: 불필요한 제어 문자 삭제 (\n 제외)
개인 정보 마스킹 오류 수정
한글 자모음 및 중복 오류 수정
길이 이상치 및 영어로 된 요약 수정
주요 전략
1. 다양한 모델 활용
KoBART, T5 계열의 모델들을 기본으로 실험을 진행했다. 또한 GPT-4, Llama 3.1 등의 대규모 언어 모델도 활용했다.
-
기본 세팅으로 실험
BART 기반 모델 (에포크당 5~10분 소요)
kobart-summarization, 42.2 -
T5 기반 모델 (에포크당 1~4시간 소요) -> Dataset에서 bos,eos 토큰을 없애야 동작
t5-small-korean-summarization, 39.6
t5-large-korean-text-summary, 41.8
ke-t5-small, 40.2 -
시간적 제약으로 시도하지 못한 모델:
Pegasus
long-ke-t5-small/base/large
ke-t5-nikl_summarization_summary
2. 하이퍼파라미터 최적화
Optuna를 사용하여 Hugging Face Trainer의 주요 하이퍼파라미터를 최적화했다. 옵티마이저 종류, 학습률, 훈련 에포크 수 등을 탐색했다.
- learning_rate: 모델의 학습 속도를 조절하는 파라미터. 너무 크면 최적점을 지나칠 수 있고, 너무 작으면 학습이 느려진다.
- num_train_epochs: 전체 데이터셋에 대해 학습을 반복하는 횟수.
- per_device_train_batch_size: GPU 메모리 사용량과 학습 속도에 영향을 미치는 배치 크기.
- weight_decay: 과적합을 방지하기 위한 L2 정규화 강도.
- warmup_ratio: 학습률을 서서히 증가시키는 웜업 단계의 비율.
- gradient_accumulation_steps: 그래디언트를 누적하여 효과적인 배치 크기를 늘리는 단계 수.
예를 들어, 다음과 같은 설정을 사용했다:
training_args = Seq2SeqTrainingArguments(
output_dir="./results",
evaluation_strategy="steps",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=3,
weight_decay=0.01,
save_total_limit=3,
load_best_model_at_end=True,
)이러한 파라미터들을 Optuna를 통해 최적화하여 모델의 성능을 향상시켰다.
3. Hugging Face Trainer 파라미터 최적화
위의 기본적인 훈련 파라미터 이외에 Optuna를 사용하여 Hugging Face Trainer의 주요 생성 하이퍼파라미터를 최적화했다.
-
고려한 파라미터:
max_length: 생성될 최대 토큰 수를 지정합니다.
temperature: 0에 가까울수록 결정적(deterministic)이고, 1에 가까울수록 무작위성이 증가합니다.
top_k: 각 단계에서 고려할 가장 가능성 높은 k개의 토큰을 지정합니다.
num_beams: 빔 서치에서 사용할 빔의 수를 지정합니다.
do_sample: True로 설정하면 확률적 샘플링을 사용하고, False면 그리디 디코딩을 사용합니다. -
결과:
t5-large-korean-text-summary 에서 ngram beam max_len 등 변경 결과 개선 없음
(43.4 ~ 43.7 범위에서 변화 없음) -
시도하지 않은 파라미터:
top_p: 누적 확률이 p를 초과할 때까지 가장 가능성 높은 토큰들을 선택합니다
repetition_penalty: 이미 생성된 토큰의 재사용을 억제하는 패널티를 설정합니다.
no_repeat_ngram_size: 지정된 크기의 n-gram이 반복되지 않도록 합니다.
4. 프롬프트 엔지니어링
LLM을 위한 효과적인 프롬프트를 설계했다. 특히 GPT-4에는 ROUGE 점수를 고려한 상세한 지시사항을 포함했다. 다음과 같이 프롬프트를 사용하여 ROUGE 점수를 최대화하는 방향으로 요약을 생성하도록 유도했다.
다음 주제에 대한 2인의 대화를 한글로 요약하되, ROUGE-1, ROUGE-2, ROUGE-L 메트릭을 고려하여 작성하십시오:
1. 원문의 단어와 표현을 정확하게 일치하도록 사용
2. 불필요한 세부 사항 제외
3. 등장인물은 #Person1#, #Person2# 등으로 표기
4. 대화의 핵심 내용과 중요한 정보를 포함
5. 요약문은 1-2문으로 작성
6. ROUGE-1: 원문과 요약문 간의 단어 일치를 평가합니다. 최대한 많은 중요한 단어가 일치하도록 요약문을 생성하십시오.
7. ROUGE-2: 원문과 요약문 간의 이웃하는 2개의 단어(바이그램) 일치를 평가합니다. 자연스러운 흐름에서 이러한 바이그램이 잘 반영되도록 노력하십시오.
8. ROUGE-L: 원문과 요약문 간의 최장 공통 부분열(LCS)을 평가합니다. 가능한 한 많은 단어 순서를 유지하여 문장 구조를 반영하십시오.5. 다양한 파인튜닝 기법
PEFT-LoRA, P-Tuning, 전체 파인튜닝 등 다양한 기법을 시도했다. GPT-4 모델의 경우, 학습 데이터 수를 늘릴수록 성능이 향상되는 것을 확인했다.
a) 전체 파인튜닝 (Full Fine-tuning):
- 모델의 모든 파라미터를 업데이트하는 전통적인 방식이다.
- GPT-4의 경우, 이 방식으로 파인튜닝을 진행했다.
- 학습 데이터 수를 200개에서 400개, 2000개로 늘리면서 성능이 지속적으로 향상되는 것을 확인했다 (점수: 40 → 42 → 44).
- temperature 파라미터를 1에서 0.1로 낮추었을 때 점수가 42에서 44.4로 대폭 상승했다.
- 전체 학습 시간은 20분 미만으로, 상대적으로 빠른 학습이 가능했다.
b) PEFT-LoRA (Parameter-Efficient Fine-Tuning with Low-Rank Adaptation):
-
모델의 일부 가중치만을 업데이트하여 메모리 효율성을 높이는 기법이다.
-
Hugging Face의 PEFT 라이브러리를 사용하여 구현했다.
-
다음과 같은 LoRA 설정을 사용했다:
peft_config = LoraConfig( r=32, # LoRA 행렬의 랭크 lora_alpha=32, # LoRA 스케일링 팩터 lora_dropout=0.05, # LoRA 레이어의 드롭아웃 비율 bias="none", # 바이어스 파라미터 포함 여부 task_type="SEQ_2_SEQ_LM" # 태스크 유형 )
c) P-Tuning:
-
입력 임베딩에 연속적인 프롬프트 벡터를 추가하는 방식이다.
-
Hugging Face의 PEFT 라이브러리를 사용하여 구현했다.
-
다음과 같은 설정을 사용했다:
peft_config = PromptEncoderConfig( task_type="SEQ_2_SEQ_LM", num_virtual_tokens=20, # 가상 토큰의 수 encoder_hidden_size=128 # 프롬프트 인코더의 은닉층 크기 )
d) 실험 결과 및 관찰:
- PEFT-LoRA와 P-Tuning은 기본 모델만으로는 성능이 좋지 않았다 (20-30점대).
- 이미 파인튜닝된 모델을 기반으로 추가 학습을 진행했을 때 더 나은 결과를 얻을 수 있었다.
- T5-small 모델을 파인튜닝한 후 PEFT-LoRA를 적용했을 때 일부 성능 향상이 있었지만, 전체 파인튜닝보다는 낮은 성능을 보였다.
- Llama 3.1 8B 모델의 경우, 4비트 양자화와 함께 PEFT-LoRA를 적용했을 때 높은 dev 점수를 얻을 수 있었다.
e) 한계점 및 교훈:
- 서버 문제로 인해 Llama 3.1과 GPT-2 모델의 일부 결과가 손실되어 완전한 비교가 어려웠다.
- 더 큰 모델 (예: Llama 3.1 70B)에 대한 실험이 제한적이었다. 만약 더 큰 모델에 대해 PEFT-LoRA나 P-Tuning을 적용했다면 더 좋은 결과를 얻을 수 있었을 것으로 예상된다.
- 파인튜닝 기법의 선택은 모델 크기, 가용 컴퓨팅 자원, 데이터셋 크기 등 다양한 요인을 고려해야 함을 깨달았다.
이러한 다양한 파인튜닝 기법의 실험을 통해, 대규모 언어 모델을 효율적으로 활용하는 방법에 대한 귀중한 통찰을 얻을 수 있었다. 향후에는 더 큰 모델에 대해 PEFT-LoRA나 P-Tuning을 적용하는 실험을 진행해볼 가치가 있을 것으로 보인다.
6. 역번역(Back-Translation) 시도
번역투의 대화를 고려하여 영어로 번역 후 요약하고 다시 한국어로 번역하는 방식을 실험했다. 이 과정은 다음과 같이 진행되었다:
a) 데이터 준비:
- dev 파일의 한글 대화를 GPT-4를 이용해 영문으로 번역했다.
- 한글 요약은 DeepL을 사용하여 영문으로 번역했다.
b) 모델 훈련:
- (모델 1) 영문 대화를 영문으로 요약하는 모델:
영문 대화와 영문 요약으로 구성된 JSONL 파일을 생성하여 GPT-4를 파인튜닝했다. - (모델 2) 영문 요약을 한글로 번역하는 모델:
영문 요약과 원래의 한글 요약을 이용해 GPT-4를 파인튜닝했다.
c) 추론 과정:
1. 한글 대화를 영어로 번역
2. 영문 대화를 모델 1을 사용해 영문으로 요약
3. 영문 요약을 모델 2를 사용해 한글로 번역
d) 성능 개선:
모델 2에서 영문 요약을 한글로 번역할 때, 원본 한글 대화를 프롬프트에 함께 제공하여 컨텍스트로 활용하도록 했다. 이 방법을 통해 점수가 2점 향상되었다(31 → 33).
e) 한계점:
- 데이터 크기를 늘려 훈련했을 때 예상만큼 점수 향상이 없었다.
- 영어 요약의 질이 한글 요약보다 더 좋을 것이라 예상했으나, 실제로는 그렇지 않았다.
f) 개선 가능성:
- 영한 번역 모델, 영문 요약 모델, 한영 번역 모델을 각각 따로 훈련시키는 방법이 더 효과적일 수 있다고 판단된다.
- LM 모델을 활용한 영어 요약도 시도해 볼 가치가 있을 것으로 보인다.
이 접근 방식은 번역투 대화의 특성을 고려한 것이었지만, 예상보다 큰 성능 향상을 얻지는 못했다. 그러나 이 과정을 통해 다국어 처리와 요약 태스크의 복잡성에 대해 더 깊이 이해할 수 있었다.
결과 및 교훈
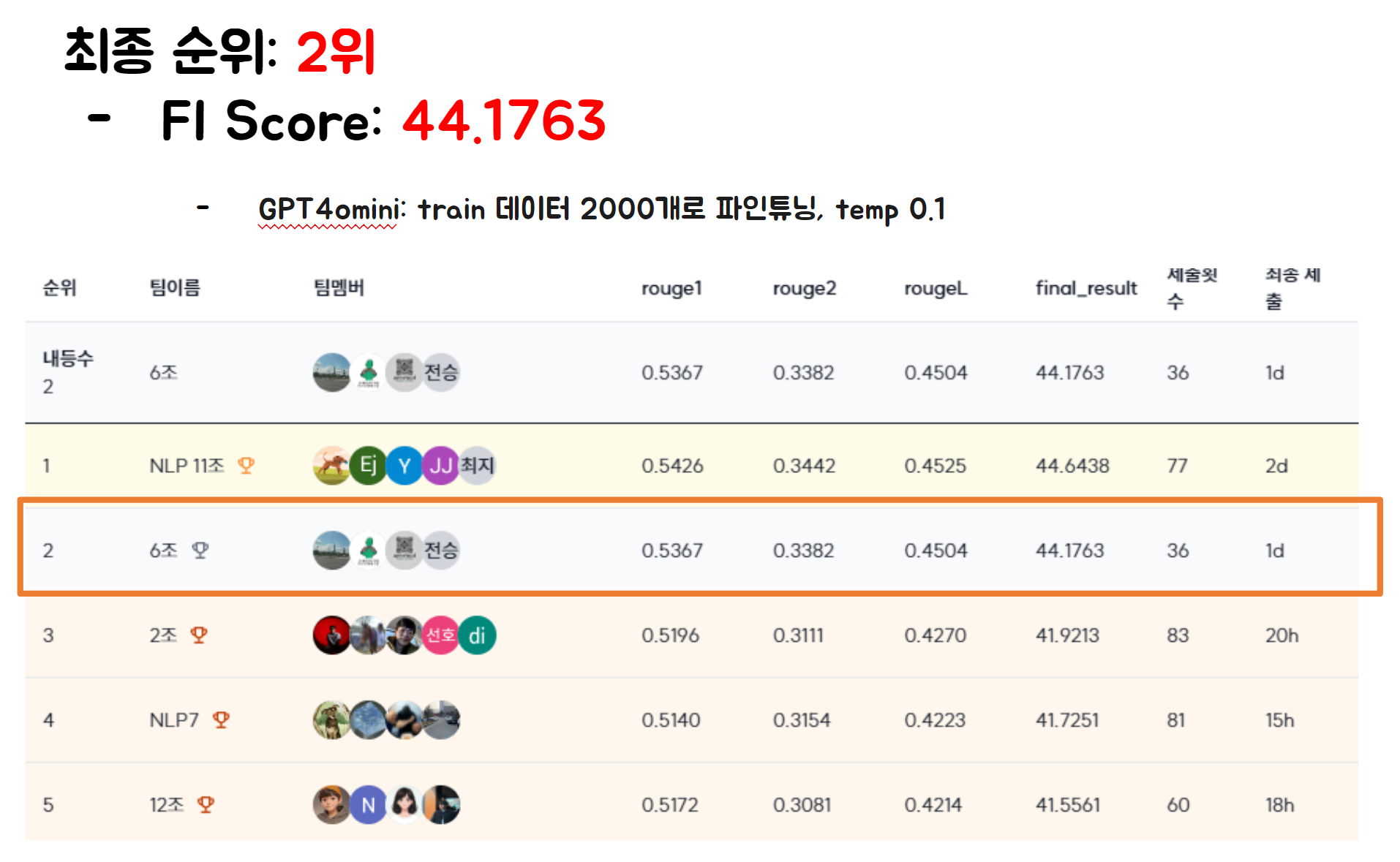
- 최종 순위 2위를 기록했으며, 최고 점수는 GPT-4 모델로 44.1763점을 달성했다.
- LLM의 경우 적은 양의 데이터로도 빠르게 학습되어 좋은 성능을 보였다.
- 데이터의 품질과 일관성이 결과에 큰 영향을 미치는 것을 확인했다.
- ROUGE 점수가 실제 요약의 품질을 정확히 반영하는지에 대해서는 의문이 남았다.
향후 개선 방향
-
정답라벨과 LLM 생성 요약을 이용한 RL기반 훈련
HuggingFace Trainer의 DPO/PPO 기반 트레이너는 chosen label과 rejected label로 구성되어 RLHF 방식으로 훈련된다.
chosen을 golden label, rejected를 zero/fewshot 결과를 이용하여 훈련
LoRA+DPO로 8B Quantized 모델 훈련가능 -
더 큰 모델을 이용한 LoRA/P-tuning
Llama3.1의 성능을 보았을때, 성능 향상의 여지가 있는 것으로 보인다. -
Custom Optimizer
하이퍼 파라미터에 민감하다면, Optimizer를 빠른 Convergence를 촉진하는 것으로 바꾸는 것은 어떨까?
Ranger (Lookahead+RectAdam) 구현 시도 -
한영-요약-영한 3단계 모델
지나치게 많은 시간 소요예상
이번 대회를 통해 다양한 NLP 기술과 최신 언어 모델을 실제 문제에 적용해 볼 수 있는 귀중한 경험을 얻었다. 앞으로도 이러한 경험을 바탕으로 더 나은 자연어 처리 솔루션을 개발해 나가고자 한다.
2.LLM 관련 강의 정리
<Large Language Model (LLM) 종합 분석>
1. LLM의 정의와 특성
1.1 정의
- 대규모 파라미터(수십억~수천억 개)를 가진 확장된 언어모델
- 방대한 텍스트 데이터로 학습된 심층 신경망 기반 모델
1.2 주요 특성
- 창발성(Emergent Abilities): 단일 모델로 다양한 태스크 수행 가능
- In-Context Learning: 별도의 미세조정 없이 새로운 태스크 수행
- 인간 가치 정렬(Human Alignment): 인간의 의도와 가치에 부합하는 출력 생성
- 다국어 및 다중 작업 처리 능력
1.3 대표적 LLM
- OpenAI의 GPT 시리즈 (GPT-3, GPT-4)
- Google의 PaLM, LaMDA
- Anthropic의 Claude
- Meta의 LLaMA
- DeepMind의 Chinchilla, Gopher
2. LLM의 등장 배경과 기술적 진보
2.1 Scaling Law
- 모델 크기, 데이터셋 크기, 컴퓨팅 파워 증가에 따른 성능 향상
- "더 크게, 더 많이" 학습할수록 성능이 로그 스케일로 향상
2.2 아키텍처 혁신
- Transformer 아키텍처의 등장 (2017)
- Attention 메커니즘을 통한 장거리 의존성 학습 능력 향상
2.3 자기 지도 학습(Self-Supervised Learning)
- 레이블이 없는 대규모 데이터셋을 활용한 효율적 학습
- 다음 단어 예측 태스크를 통한 언어 이해 및 생성 능력 향상
2.4 전이 학습과 Few-Shot Learning
- 사전 학습된 모델을 다양한 하위 태스크에 적용
- 적은 양의 예시만으로도 새로운 태스크 수행 가능
3. LLM의 제작 프로세스
3.1 인프라
- 대규모 GPU 클러스터 또는 TPU 포드
- 분산 학습을 위한 고성능 네트워크
- 대용량 고속 스토리지 시스템
3.2 데이터 준비
- 웹 크롤링, 책, 논문 등 다양한 소스에서 텍스트 수집
- 데이터 정제: 중복 제거, 품질 필터링, 개인정보 제거
- 토큰화 및 전처리
3.3 모델 아키텍처 설계
- Transformer 기반 아키텍처 선택 및 최적화
- 모델 크기 (파라미터 수) 결정
- 하이퍼파라미터 설정: 레이어 수, 어텐션 헤드 수 등
3.4 사전 학습 (Pre-training)
- 대규모 데이터셋을 사용한 자기 지도 학습
- 다음 토큰 예측 태스크 수행
- 분산 학습 및 최적화 기법 적용
3.5 미세조정 (Fine-tuning)
- 특정 태스크나 도메인에 맞춘 추가 학습
- Instruction Tuning: 지시사항 형태의 데이터로 학습
- RLHF (Reinforcement Learning from Human Feedback): 인간 피드백 기반 강화학습
4. LLM의 주요 연구 방향 및 기술 동향
4.1 모델 효율성 향상
- 모델 압축 및 지식 증류
- 혼합 정밀도 훈련 및 양자화
- 스파스 모델링
4.2 멀티모달 통합
- 텍스트-이미지 결합 모델 (예: DALL-E, Stable Diffusion)
- 비전-언어 모델 (예: GPT-4, PaLM-E)
- 음성 인식 및 합성 통합
4.3 추론 능력 강화
- Chain-of-Thought Prompting
- 자기 일관성 (Self-Consistency) 기법
- 외부 도구 및 지식베이스 활용
4.4 윤리 및 안전성
- 편향성 감소 기법 연구
- 유해 콘텐츠 필터링
- 프라이버시 보호 학습 방법 (연합 학습 등)
4.5 해석 가능성 및 설명 가능성
- 어텐션 시각화 기법
- 프로빙 태스크를 통한 내부 표현 분석
- 모델 동작의 형식적 검증
5. LLM의 응용 분야
5.1 자연어 처리 태스크
- 기계 번역, 요약, 질의응답
- 감성 분석, 개체명 인식
- 대화 시스템 및 챗봇
5.2 창의적 작업
- 스토리 생성, 시 작성
- 광고 문구 및 마케팅 콘텐츠 생성
- 음악 작곡 지원
5.3 코딩 및 소프트웨어 개발
- 코드 자동 완성 및 생성
- 버그 감지 및 수정
- 프로그래밍 교육 지원
5.4 과학 연구 및 의료
- 학술 논문 분석 및 요약
- 약물 상호작용 예측
- 의료 기록 분석 및 진단 지원
5.5 교육 및 학습
- 개인화된 튜터링 시스템
- 교육 자료 생성 및 적응형 학습
6. LLM의 한계 및 과제
6.1 환각(Hallucination) 문제
- 사실과 다른 정보 생성
- 정보의 신뢰성 검증 필요
6.2 편향성 및 공정성
- 학습 데이터의 편향성 반영
- 사회적 고정관념 강화 가능성
6.3 계산 비용 및 환경 영향
- 대규모 모델 학습에 따른 높은 에너지 소비
- 탄소 배출량 증가 우려
6.4 법적, 윤리적 문제
- 저작권 및 지적 재산권 이슈
- 개인정보 보호 문제
- AI 생성 콘텐츠의 책임 소재
6.5 장기 기억 및 지식 업데이트
- 학습 시점 이후의 정보 반영 어려움
- 실시간 지식 갱신 메커니즘 필요
7. 향후 전망 및 연구 방향
7.1 모델 아키텍처 혁신
- Transformer를 넘어선 새로운 아키텍처 탐색
- 신경생물학적 영감을 받은 모델 구조
7.2 지속적 학습 및 적응
- 온라인 학습 및 평생 학습 기법 개발
- 새로운 정보의 효율적 통합 방법
7.3 다중 에이전트 시스템
- LLM 기반 협업 AI 시스템
- 전문화된 모델 간의 상호작용 및 통합
7.4 인간-AI 협력 강화
- 더 자연스러운 인터페이스 개발
- 인간의 의도 및 맥락 이해 개선
7.5 범용 인공지능(AGI)을 향한 발전
- 다양한 지능 요소의 통합
- 추상적 추론 및 메타인지 능력 개발
1. Large Language Model (LLM) 개요
1.1 In-Context Learning
-
N-Shot Learning:
- 정의: 모델이 추론 시 N개의 예시를 참고하여 정답을 생성하는 방식
- 특징: 문맥과 원하는 답의 예시들이 주어진 후, 새로운 문맥에 대해 답을 생성
- 장점: Task-specific 데이터의 필요성을 크게 줄임, 새로운 task에 빠르게 적응 가능
-
Few-Shot Learning:
- 정의: 적은 수의 학습 예제로 새로운 작업을 수행하는 능력
- 특징: GPT-3에서 주목받기 시작한 기술
- 성능: 모델 크기가 커질수록 few-shot 성능이 향상됨
- 응용: 다양한 NLP 태스크에 적용 가능 (분류, 생성, QA 등)
1.2 ChatGPT의 정의와 특징
- 기본 모델: GPT-3.5를 기반으로 파인튜닝
- 관련 모델: InstructGPT의 "sibling model"로, 유사한 학습 방식 사용
- 데이터 특성: 대화형 데이터로 학습되어 자연스러운 대화 가능
- 핵심 기술:
- 사용자 선호도를 반영한 보상 모델(Reward Model) 사용
- 강화학습(RLHF: Reinforcement Learning from Human Feedback)을 통한 최적화
- 주요 능력:
- 다양한 주제에 대한 대화 및 질문 응답
- 코드 작성 및 디버깅
- 창의적 글쓰기 및 아이디어 제안
- 다국어 지원
1.3 ChatGPT의 학습 방법
-
SFT(Supervised Fine-Tuning):
- 목적: 지시 따르기(instruction following) 능력 향상
- 데이터: 13K개의 지시 프롬프트와 그에 대한 이상적인 응답으로 구성
- 과정: GPT-3에 이 데이터셋으로 미세조정 적용
-
보상 모델(Reward Model) 학습:
- 목적: 사람의 선호도를 모델화
- 데이터: 33K개의 프롬프트에 대한 여러 응답과 그 선호도 순위
- 학습 방식: 주어진 프롬프트에 대해 더 선호되는 응답에 높은 점수 부여하도록 학습
-
RLHF(Reinforcement Learning from Human Feedback):
- 알고리즘: PPO(Proximal Policy Optimization) 사용
- 과정:
a) SFT 모델이 프롬프트에 대한 응답 생성
b) 보상 모델이 생성된 응답 평가
c) 평가 결과를 바탕으로 모델 정책 업데이트 - 목표: 사람이 선호하는 방향으로 응답 생성 능력 향상
1.4 ChatGPT 활용 팁
-
Persona Injection:
- 정의: 챗봇에 특정 역할이나 성격 부여
- 예시: "당신은 지금부터 X입니다. X처럼 행동하고 대답해주세요."
- 효과: 특정 상황이나 전문 분야에 맞는 응답 유도
-
프롬프트 구성 원칙:
- 명확성: 모호하지 않고 구체적인 지시 제공
- 간결성: 불필요한 정보 제거, 핵심만 전달
- 단계적 접근: 복잡한 작업은 여러 단계로 나누어 요청
-
출력 형식 지정:
- 방법: 원하는 응답 형식을 명확히 제시 (예: "JSON 형식으로 답변해주세요")
- 장점: 일관된 형식의 응답 얻기 용이, 후처리 간소화
-
구역 지정:
- 용도: 복잡한 요청 시 각 부분을 명확히 구분
- 방법: 번호 매기기, 섹션 나누기 등
- 효과: 누락 없이 모든 요청사항 처리 가능
-
예시 제공:
- 목적: 원하는 출력 형태를 구체적으로 전달
- 방법: "다음과 같은 형식으로 답변해주세요: [예시]"
- 효과: 모델의 이해도 향상, 정확한 형식의 응답 유도
2. Parameter Efficient Fine-Tuning (PEFT)
2.1 PEFT 소개
- 정의: 대규모 언어 모델의 일부 파라미터만을 업데이트하여 효율적으로 미세조정하는 기법
- 필요성:
- 전체 모델 미세조정의 높은 계산 비용 및 메모리 요구량
- 미세조정된 전체 모델의 저장 및 배포 비용
- 주요 장점:
- 연산량 대폭 감소: 전체 파라미터의 0.01% 미만만 수정
- Catastrophic forgetting 완화: 기존 지식 보존
- 적은 데이터로도 효과적: 오버피팅 위험 감소
- 다중 태스크 처리: 태스크별 작은 모듈 추가로 다양한 기능 구현
2.2 주요 PEFT 방법론
2.2.1 Prompt Tuning
- 개념: 입력 시퀀스에 학습 가능한 연속적 임베딩(soft prompt) 추가
- 작동 원리:
- 모델 파라미터는 고정
- 각 태스크마다 고유한 soft prompt 학습
- 추론 시 해당 태스크의 soft prompt 사용
- 장점:
- 모델 크기와 무관한 일정한 추가 파라미터 수
- 우수한 도메인 적응력
- 태스크 간 간섭 최소화
- 성능: 모델 크기가 클수록 전체 미세조정에 근접한 성능
2.2.2 Prefix-Tuning
- 개념: 각 트랜스포머 레이어의 입력에 태스크별 prefix 벡터 추가
- 구조:
- 입력 임베딩 층에 prefix 추가
- 각 트랜스포머 레이어의 self-attention, cross-attention 입력에 prefix 추가
- 특징:
- Prompt Tuning보다 더 깊은 레이어까지 영향
- prefix는 학습 가능한 행렬로 초기화
- 장점:
- 단일 모델로 다중 태스크 처리 가능
- 낮은 파라미터 오버헤드
- 응용: 자연어 생성 태스크에서 특히 효과적
2.2.3 P-Tuning
- 개념: Prompt Encoder를 사용해 연속적인 prompt 임베딩 생성
- 구조:
- Bi-LSTM 기반의 Prompt Encoder 사용
- 일부 고정된 'anchor' 토큰과 학습 가능한 prompt 토큰 결합
- 특징:
- 이산적(discrete) 프롬프트의 한계 극복
- 모델 구조와 독립적으로 적용 가능
- 성능:
- NLU 태스크에서 GPT 스타일 모델의 성능 향상
- 일부 태스크에서 전체 미세조정 대비 우수한 결과
2.2.4 LoRA (Low-Rank Adaptation)
- 개념: 가중치 업데이트를 저순위 분해로 근사
- 방법:
- 원본 가중치 행렬 W는 고정
- 저순위 행렬 A와 B를 통해 ΔW = AB 학습
- 추론 시 W + ΔW 사용
- 특징:
- 주로 self-attention 모듈의 쿼리와 값 프로젝션에 적용
- 학습 가능한 파라미터 수를 크게 줄임 (예: GPT-3의 0.01%)
- 장점:
- 추론 시간 증가 없음
- 다른 PEFT 방법과 결합 가능
- 태스크 간 빠른 전환 가능
2.2.5 Quantization
- 정의: 모델 파라미터를 더 적은 비트로 표현하는 기법
- 목적: 메모리 사용량 감소 및 추론 속도 향상
- 주요 방식:
- 동적 양자화: 추론 시 실시간으로 양자화
- 정적 양자화: 모델 저장 시 미리 양자화
- 양자화 인식 학습: 학습 중 양자화 고려
- 일반적 적용: 32비트 부동소수점에서 8비트 정수로 변환
- 장점: 모델 크기 감소, 하드웨어 가속 가능
2.2.6 QLoRA (Quantized Low-Rank Adapters)
- 개념: 4비트 양자화 모델에 LoRA 적용
- 방법:
- 기본 모델을 4비트로 양자화
- LoRA 어댑터는 16/32비트로 유지
- 특징:
- 4비트 양자화를 위한 새로운 기법 도입 (Double Quantization)
- 페이지드 최적화로 메모리 효율성 향상
- 성능: 16비트 전체 미세조정과 유사한 성능 달성
- 장점: 대규모 모델의 저비용 미세조정 가능 (예: 65B 파라미터 모델을 단일 48GB GPU에서 조정)
2.2.7 IA3 (Infused Adapter by Inhibiting and Amplifying Inner Activations)
- 개념: 트랜스포머 내부 활성화를 조절하는 벡터 도입
- 적용 위치:
- Self-Attention과 Cross-Attention의 Key, Value
- Feed-forward 네트워크의 출력
- 방법: 각 위치에 학습 가능한 벡터를 곱하여 활성화 조절
- 특징:
- LoRA보다 적은 파라미터로 유사하거나 더 나은 성능
- 기존 가중치에 새 값을 더하는 대신 곱셈 연산 사용
2.2.8 LLaMA Adapter
- 목적: LLaMA 모델의 효율적인 instruction tuning
- 방법:
- 상위 트랜스포머 레이어에 학습 가능한 어댑터 추가
- 어댑터는 입력 텍스트 앞에 위치
- 특징:
- 약 1.2M의 적은 파라미터로 구현
- 다양한 지식 주입 가능
- 멀티모달 조건부 생성 지원 (예: 이미지-텍스트 태스크)
- 구조:
- 어댑터 토큰: 학습 가능한 임베딩
- 게이트 메커니즘: 어댑터와 원본 입력의 결합 제어
- 성능: 효율성과 성능 면에서 기존 방법들 대비 우수
1. 국내 LLM 현황
1.1 네이버: HyperCLOVA X
- 자체 개발한 대규모 언어 모델
- CLOVA Studio를 통해 API 서비스 제공
- 다양한 응용 분야(챗봇, 콘텐츠 생성, 코드 생성 등)에 활용
1.2 LG AI Research: EXAONE 2.0
- 멀티모달 AI 모델
- EXAONE Universe(전문가용 대화형 AI 플랫폼), EXAONE Discovery(신소재/신물질/신약 개발 플랫폼), EXAONE Atelier(창의적 발상 지원 플랫폼) 등 제공
1.3 카카오뱅크: CarbonVillain
- 허깅페이스 OpenLLM 리더보드 평가 1위 (2023년 12월 기준)
- 머지 모델(Merge Model) 방식 사용
1.4 카카오브레인: minDALL-E
- 텍스트-이미지 생성 모델
- 1.46억 개의 이미지-텍스트 쌍으로 학습
1.5 NC소프트: VARCO
- VARCO LLM KO-13B-FM(Foundation Model)
- VARCO LLM KO-13B-IST(Instruction Tuning Model)
- VARCO Studio: 게임 콘텐츠 개발을 위한 멀티모달 플랫폼
1.6 SK텔레콤: 에이닷(A.) 2.0
- 대화형 AI 어시스턴트
1.7 KT: 믿:음
- 맞춤형 AI 서비스 제공
1.8 코난테크놀로지: Konan LLM
- 한국어 특화 언어모델
1.9 마음AI: maumGPT
- 기업용 맞춤형 AI 시스템 구축 플랫폼
1.10 솔트룩스: 루시아GPT
- 기업용 AI 솔루션
1.11 뤼이드: Sheep-duck-llama-2
- 교육 분야 특화 모델
1.12 42dot: LLM-PLM / LLM-SFT
- 한영 Pretraining 및 SFT 모델
1.13 업스테이지: SOLAR
- Depth Up-Scaling (DUS) 기법 적용
- 오픈소스 LLM 분야에서 높은 성능 기록
2. 해외 LLM 현황
2.1 OpenAI: GPT 시리즈
- GPT-3, GPT-4 등 선도적인 언어 모델
- ChatGPT, DALL-E 등 다양한 응용 서비스 제공
- GPT Store를 통한 커스텀 GPT 생태계 구축
2.2 Microsoft: Bing Chat, Copilot
- OpenAI 기술 기반의 서비스 제공
2.3 Meta AI: LLaMA 2, Code Llama
- 오픈소스 기반의 강력한 언어 모델
- 코딩 특화 모델 제공
2.4 Google: PaLM 2, Med-PaLM 2, BARD, Gemini
- 다양한 분야에 특화된 모델 개발
- 멀티모달 AI 모델 Gemini 출시
2.5 Amazon: Titan, Bedrock, Alexa
- 자체 개발 모델과 타사 모델을 통합 제공하는 플랫폼 운영
2.6 Anthropic: Claude 2.1
- 200K 컨텍스트 윈도우, 환각률 감소 등 개선된 성능
2.7 Mistral AI: Mistral 7B, Mistral 8x7B
- 효율적인 아키텍처로 높은 성능 달성
2.8 HuggingFace: BLOOM, Zephyr-7B
- 오픈소스 기반의 다국어 지원 모델
2.9 기타 주목할 만한 모델들
- Technology Innovation Institute: Falcon
- LMSYS: Vicuna-13B
- EleutherAI: Llemma (수학 특화 모델)
- DataBricks: Dolly 2.0
- Alibaba: Qwen
- 01.AI: Yi (다국어 특화 모델)
1. LLM 학습 데이터 종류
1.1 사전 학습 데이터
- 주요 소스: 웹 데이터(Wikipedia, 뉴스, 리뷰 등)
- 중요 요소: 데이터의 품질, 다양성, 최신성
- 주요 데이터셋:
- Common Crawl, WebText2, BookCorpus, Wikipedia 등
- 데이터 구성 예:
- GPT-3: Common Crawl (필터링), WebText2, Books1, Books2, Wikipedia (총 3000억 토큰)
- LLaMA: Common Crawl, C4, Github, Wikipedia, Books, ArXiv, StackExchange (총 1.4조 토큰)
1.2 태스크 특화 사전 학습
- LaMDA: 50% 대화 데이터 사용
- BLOOM, PaLM: 다국어 데이터 활용
- Galactica: 86% 과학 데이터 사용
- AlphaCode: 100% 코드 데이터 사용
1.3 미세 조정 데이터
- Instruction Tuning 데이터:
- 지시어(Instruction)와 대응하는 출력(Answer)으로 구성
- 예: Stanford Alpaca, FLAN, Super-NaturalInstructions
- Alignment Tuning 데이터:
- 인간의 선호도가 반영된 데이터
- 예: InstructGPT의 Human preference 데이터
1.3.1 주요 Instruction 데이터셋
- Cross-Task Generalization: 61개 NLP 태스크, 193K 인스턴스
- FLAN: 62개 NLP 데이터셋, 다양한 템플릿 사용
- Super-NaturalInstructions: 1600+ NLP 태스크
- Stanford Alpaca: GPT-3.5로 생성한 데이터셋
- LIMA: 1,000개의 고품질 instruction 데이터
1.3.2 Alignment Tuning 연구
- InstructGPT: Human preference annotation 기반 RLHF
- Constitutional AI: AI 피드백을 활용한 Harmful output 식별
- RLAIF: AI 피드백을 활용한 강화학습
- Direct Preference Optimization: Preference data로 직접 LM 학습
2. LLM 데이터 전처리
2.1 주요 전처리 과정
- Data filtering: 저품질 데이터 제거
- Deduplication: 중복 데이터 제거
- Diversification: 다양한 소스 활용
2.2 GPT-3의 전처리 방법
- Filtering: 유사도 기반 필터링, 고품질 문서 분류기 사용
- Deduplication: 문서 레벨 퍼지 중복 제거 (MinHashLSH 활용)
- Diversification: WebText, Books1, Books2, Wikipedia 등 추가
2.3 LLaMA의 전처리 방법
- Filtering:
- FastText 활용 언어 식별
- N-gram 언어 모델 활용 저품질 필터링
- Wikipedia 참조 페이지 분류 모델 사용
- 휴리스틱 기반 품질 필터링
- Deduplication: 라인 레벨 중복 제거, 책 내용 90% 이상 중복 시 제거
- Diversification: CommonCrawl, C4, GitHub, Wikipedia, Books3, ArXiv 등 혼합
2.4 주요 데이터 전처리 연구
- The Pile: 800GB 다양한 텍스트 데이터셋, 새로운 전처리 과정 적용
- RefinedWeb Dataset: 웹 데이터만으로 고품질 데이터셋 구축
- MDR (MacroData Refinement): "Scale first", "Strict deduplication", "Neutral filtering" 원칙
- D4: 사전학습 LM 임베딩 활용한 중복 제거 및 다양화
- Self-Refine: LLM 활용 반복적 자체 피드백 과정으로 데이터 품질 개선
3. LLM 기반 라벨링 연구
3.1 데이터 증강 연구
-
LLM-powered Data Augmentation for Enhanced Crosslingual Performance
- LLM으로 다국어 데이터셋 증강, 소규모 모델 성능 향상
-
Mixture of Soft Prompts for Controllable Data Generation
- 구조화된 예측 태스크를 위한 LLM 기반 데이터 생성 방법
3.2 데이터 합성 연구
-
Vicuna
- ChatGPT 대화 데이터로 LLaMA 파인튜닝
-
DISCO
- LLM 활용 대규모 반사실적 데이터 생성 (NLI 태스크)
-
Large Language Model as Attributed Training Data Generator
- 속성이 부여된 프롬프트로 기사 분류 데이터셋 합성
-
Instruction tuning with GPT-4
- GPT-4로 instruction 데이터셋 생성, LLM 파인튜닝에 활용
-
Increasing Diversity While Maintaining Accuracy
- 인간과 LLM 협력으로 데이터의 다양성과 품질 개선
1. LLM Tuning
1.1 Fine-Tuning
- 정의: 사전학습된 모델을 특정 작업에 특화 학습하는 과정
- LLM에서는 주로 Instruction Tuning을 지칭
- 문제점: 방대한 파라미터로 인한 높은 계산 리소스 요구
1.2 Parameter Efficient Tuning
모델 전체가 아닌 일부만 튜닝하는 방법론
1.2.1 Adapter-based Tuning
- 기존 모델에 별도의 Adapter 모듈 추가
- 기존 모델 파라미터는 고정, Adapter만 학습
1.2.2 LoRA (Low-Rank Adaptation)
- 원리: 가중치 업데이트를 저순위 행렬로 근사
- 장점:
- 메모리 및 저장 공간 절약 (예: GPT-3 175B의 VRAM 1.2TB → 350GB)
- 학습 속도 약 25% 증가
- 빠른 태스크 전환 가능
1.2.3 QLoRA
- LoRA의 메모리 효율적 구현
- 주요 기술:
- 4-bit NormalFloat (NF4): 효율적인 가중치 표현
- Double Quantization: 양자화 상수 재양자화로 메모리 절감
- Paged Optimizer: GPU-CPU 메모리 최적화
1.2.4 Prefix-Tuning
- 방법: 입력 토큰 앞에 학습 가능한 파라미터 추가
- 특징: 전체 파라미터의 0.1%만으로 full fine-tuning 수준 성능 달성
1.2.5 LLaMA-Adapter
- 특징:
- LLaMA 모델 고정, 1.2M의 Adapter만 학습
- Zero-initialized gating 방법 적용
- 장점: 멀티모달 모델링 가능 (CLIP 등과 결합)
2. Domain Specialization
2.1 정의
- 목적: 일반 도메인 모델을 특정 도메인에 특화시키는 과정
- 필요성: 일반 모델의 특정 도메인 이해력 부족 문제 해결
2.2 Knowledge Augmentation (External Augmentation)
외부 소스에서 관련 정보를 검색하여 모델의 도메인 지식 향상
2.2.1 Retrieval-Augmented Generation (RAG)
- 구성: 언어 모델과 검색 모델을 결합한 프레임워크
- 방법: 검색된 도메인 컨텍스트를 프롬프트에 포함시켜 in-context learning
2.2.2 In-Context Retrieval-Augmented Language Models
- 특징: 검색된 컨텍스트를 추가 학습 없이 in-context learning으로 활용
- 결과: 관련성 높은 검색 컨텍스트로 성능 크게 개선
2.2.3 GeneGPT
- 방법: NCBI Web APIs와 LLM 결합
- 목적: 생물의학 정보 접근성 향상
2.2.4 Verify-and-Edit Framework
- 방법: Chain-of-Thought 프롬프팅에 외부 지식 기반 검증 과정 추가
- 과정: 각 추론 단계를 검색된 지식으로 편집하고 새로운 답변 생성
2.3 Domain Tuning (Knowledge-updated Domain Specialization)
도메인 특화 코퍼스로 LLM 추가 학습
2.3.1 FinGPT
- 목적: 금융 분야 특화 LLM 개발
- 방법:
- 실시간 금융 데이터 자동 수집 파이프라인 구축
- QLoRA 및 주가 기반 강화학습 적용
2.3.2 Med-PaLM 2
- 목적: 의료 분야 전문가 수준의 질의응답 시스템 개발
- 기반 모델: Google의 PaLM 2
- 학습 방법:
- Instruction fine-tuning: 다양한 의료 데이터셋 활용
- Few-shot prompting
- Chain-of-Thought (CoT) prompting
- Self-consistency: 복잡한 의료 추론에 효과적
- Ensemble refinement: CoT 및 Self-Consistency 기반 자체 개선 기술
1. LLM Evaluation
1.1 일반적인 평가 방법
1.1.1 벤치마크 데이터셋 기반 평가
- 예: ChatGPT 평가 연구 (Laskar et al.)
- 140개 태스크, 255K 생성 결과 분석
- 결과: 대부분의 언어 이해 작업에서 우수한 zero-shot 능력 입증
- 한계: 수학적 추론 등 일부 작업에서 정확한 답변과 부정확한 추론 과정의 불일치 발견
1.1.2 GPT-4를 활용한 평가 (G-EVAL)
- 기존 BLEU, ROUGE 등의 메트릭스의 한계 극복
- 인간 판단과의 높은 상관관계 보임
- 주의점: 평가자 모델의 편향 가능성 존재
1.1.3 작업별 세부 평가 (FLASK)
- alignment skill sets 기반 세분화 평가
- 인간 평가와 더 높은 상관관계 달성
1.2 Interpretability (해석 가능성)
1.2.1 지식 충돌 시 LLM 행동 분석
- 'Adaptive Chameleon or Stubborn Sloth' 연구
- LLM의 파라메트릭 지식과 검색된 지식 간 충돌 시 행동 분석
- 결과: LLM이 파라메트릭 지식에 의존하는 경향, 단 높은 일관성의 외부 정보는 수용
- 시사점: LLM의 정보 수용 과정의 복잡성과 잠재적 오류 가능성 제시
1.2.2 LLM as Examiner
- 'Benchmarking Foundation Models' 연구
- LLM을 다른 모델의 평가자로 활용
- GPT-4 사용 시 인간 선호도와 80% 이상 일치
- 한계: 평가자 모델의 편향 가능성 존재
1.2.3 새로운 지식 처리 능력 평가 (ALCUNA)
- 급변하는 세계에서 LLM의 새 지식 처리 능력 평가
- 중요성: LLM의 실시간 적응력과 지식 업데이트 능력 측정
1.2.4 사실 지식 평가
- 'Do Large Language Models Know about Facts?' 연구
- LLM의 사실적 지식 범위와 정확도 종합 평가
- 지식 집약적 태스크에 대한 심층 분석 수행
1.2.5 Hallucination 평가 (HaluEval)
- LLM의 환각 현상을 평가하기 위한 벤치마크 데이터셋
- 결과: 기존 LLM의 환각 내용 구분 능력 부족 확인
- 개선 방안: Retrieval augmentation의 효과성 입증
1.3 Ethics/Trustworthiness (윤리성/신뢰성)
1.3.1 Toxicity 평가
- ChatGPT의 독성 분석 연구
- 특정 페르소나 할당 시 독성 최대 6배 증가 관찰
- 시사점: LLM 사용 시 컨텍스트와 역할 설정의 중요성 강조
1.3.2 편향성 분석
- ChatGPT의 MBTI 및 정치적 편향성 조사
- LLM 개발자의 편향 관리 책임 강조
1.3.3 Sycophancy (아첨) 현상 연구
- LLM의 아첨 행위 이해 및 영향 분석
- 결과: LLM의 응답이 사용자의 선호나 의견에 과도하게 동조할 수 있음을 시사
1.3.4 평가의 공정성 연구
- 'Large Language Models are not Fair Evaluators' 연구
- 발견: 응답 후보의 순서만으로도 LLM의 평가 결과 변화
- 개선: Multiple Evidence Calibration (MEC)와 Balanced Position Calibration (BPC) 프레임워크 제안
- 결과: ChatGPT는 공정한 평가자가 아니나, GPT-4는 상대적으로 공정한 평가 수행
2. LLM Leaderboard
2.1 주요 LLM 리더보드
2.1.1 Open LLM Leaderboard (Hugging Face)
- 목적: 다양한 오픈소스 LLM의 성능 비교
- 특징: 지속적으로 업데이트되는 모델 순위 제공
2.1.2 MTEB (Massive Text Embedding Benchmark) Leaderboard
- 목적: 텍스트 임베딩 모델의 성능 평가
- 평가 영역: 다양한 NLP 태스크에서의 임베딩 품질 측정
2.1.3 Chatbot Arena
- 특징: Elo 레이팅 시스템 사용, 20만개 이상의 인간 선호도 데이터 기반
- 장점: 실제 사용자 경험을 반영한 평가 제공
2.1.4 Big Code Models Leaderboard
- 목적: 코드 생성 모델의 성능 비교
- 평가 기준: HumanEval 벤치마크, MultiPL-E 등 사용
2.1.5 Open ASR Leaderboard
- 목적: 음성 인식 모델 평가
- 주요 메트릭: Word Error Rate (WER), Real-Time Factor (RTF)
2.1.6 LLM Perf Leaderboard
- 목적: LLM의 처리 성능 평가
- 평가 영역: 지연 시간, 처리량, 메모리 및 에너지 효율성
2.1.7 Open Multilingual LLM Evaluation Leaderboard
- 특징: 29개 언어 지원, 지속적 확장 중
- 중요성: 다국어 LLM의 성능 비교 제공
2.1.8 AlpacaEval Leaderboard
- 특징: GPT-4 등 고성능 LLM을 참조 모델로 활용한 평가
2.1.9 HELM (Holistic Evaluation of Language Models) Leaderboard
- 특징: 다양한 시나리오와 관점에서 LLM 평가
- 장점: 종합적이고 체계적인 평가 프레임워크 제공
2.1.10 Hallucinations Leaderboard
- 목적: LLM의 환각 현상 평가
- 사용 데이터셋: TruthfulQA, HaluEvals, XSum, CNN/DM, Self-CheckGPT 등
2.1.11 OpenCompass 2023 LLM Annual Leaderboard
- 특징: 연간 LLM 평가 제공
- 평가 영역: 언어, 지식, 추론, 창의성, 장문 컨텍스트 처리, 에이전트 능력 등
2.1.12 ZeroSCROLLS
- 목적: 장문 텍스트 생성 능력 평가
- 평가 태스크: 요약, QA, 감정 분류, 정보 재배열 등 10개 태스크
2.1.13 Open Ko-LLM Leaderboard
- 목적: 한국어 LLM의 객관적 성능 평가
- 주최: Upstage, NIA (AI-Hub 데이터 제공)
1. LLMOps (Large Language Model Operations)
1.1 LLMOps의 개념
- 정의: LLM의 운영 관리(학습/배포)에 활용되는 사례, 기술 및 도구를 포괄하는 개념
- 중요성: Forbes 선정 2023년 10대 AI 예측 중 하나로 선정됨
1.2 MLOps와의 차이점
- 기본 구성: 데이터, 모델 학습, 서빙 등 MLOps와 유사
- 주요 차이: 모델 규모의 차이로 인한 특수성 존재
1.3 LLMOps의 특수성
1.3.1 모델 사이즈
- 특징: 매우 큰 모델 크기
- 결과: 높은 계산 리소스 요구
- 요구사항: 최적화 및 병렬 처리 기술 필요
1.3.2 데이터의 특수성
-
데이터 크기 및 형식
- 대규모 데이터셋 필요
- 다양한 형식의 데이터 처리 능력 요구
-
Prompt Engineering
- 목적: In-Context Learning 능력 극대화
- 중요성: 특정 작업에 대한 모델 성능 향상
- 기법: 적절한 지시어 및 예제 제공
1.3.3 생성형 모델의 특성
- 출력 결과의 다양성: 성능 평가 및 인간 평가 방법의 세분화 필요
- 윤리적 문제: 편향성, 환각 현상 등 고려
- 해결책: Post-processor 도입 필요
1.3.4 서빙 방식
- 주요 방식: API 앱 형태의 배포
- 예시: 대화형 챗봇, 어시스턴트, 작업 특화 파이프라인
- 이유: 모델 크기와 복잡한 전/후처리 과정
1.4 LLMOps 프로세스
- 데이터 준비 및 전처리
- 모델 선택 및 학습
- 평가 및 튜닝
- 배포 및 모니터링
- 지속적인 학습 및 개선
2. Augmented LLMs
2.1 개념
- 정의: LLM의 능력을 외부 도구나 추가 기능으로 확장한 모델
- 목적: LLM의 한계 극복 및 성능 향상
2.2 주요 연구 및 접근 방법
2.2.1 Toolformer
- 특징: LLM이 스스로 도구 사용법을 학습
- 방법: API 호출 등을 통한 외부 도구 활용
2.2.2 TaskMatrix.AI
- 목적: 다양한 API와 LLM 연결
- 특징: 수백만 개의 API를 LLM과 연동하여 다양한 작업 수행
2.2.3 CRITIC
- 방법: 도구 상호작용을 통한 자기 수정
- 목적: LLM의 오류 감지 및 수정 능력 향상
2.2.4 Self-Improvement in Code Generation
- 방법: LLM 자체 능력 기반 데이터 증강
- 결과: 코드 생성 능력 향상
2.2.5 Self-Debugging
- 목적: LLM에게 자체 디버깅 능력 부여
- 방법: 오류 감지 및 수정 과정 학습
2.2.6 Cross Examination for Factual Error Detection
- 방법: 여러 LLM 간 상호작용
- 목적: 사실적 오류 탐지 능력 향상
2.2.7 BlenderBot 3
- 특징: 지속적으로 학습하는 대화형 에이전트
- 목적: 책임감 있는 대화 능력 개발
2.2.8 Multi-Character Belief Tracker
- 목적: LLM의 Theory of Mind 개선
- 방법: 다중 캐릭터 신념 추적 시스템 도입
2.2.9 Reflexion
- 특징: 언어 기반 강화학습
- 목적: LLM의 자기 개선 능력 향상
2.2.10 ToolLLM
- 특징: 16,000개 이상의 실제 API 마스터
- 목적: LLM의 실제 도구 사용 능력 확장
2.2.11 Chameleon
- 특징: 플러그 앤 플레이 방식의 추론 시스템
- 목적: LLM의 유연한 추론 능력 향상
2.2.12 ViperGPT
- 방법: Python 코드 실행을 통한 시각적 추론
- 목적: 시각 정보 처리 및 추론 능력 향상
2.2.13 ART (Automatic multi-step reasoning and tool-use)
- 특징: 자동 다단계 추론 및 도구 사용
- 목적: LLM의 복잡한 문제 해결 능력 강화
2.3 Augmented LLMs의 장점
- 확장성: 외부 도구 및 지식 활용으로 능력 확장
- 정확성 향상: 실시간 정보 접근 및 도구 사용으로 정확도 개선
- 다양성: 다양한 작업 수행 가능
- 적응성: 새로운 상황이나 도메인에 빠르게 적응
2.4 도전 과제
- 통합의 복잡성: 다양한 도구와 LLM의 원활한 통합
- 보안 및 프라이버시: 외부 도구 사용에 따른 보안 문제
- 일관성 유지: 다양한 도구 사용 시 일관된 출력 유지
- 학습 및 최적화: 효율적인 도구 사용 방법 학습
1. Prompt Engineering
1.1 개요
- 정의: LLM의 In-Context Learning 능력을 최대화하기 위한 입력 설계 기술
- 목적: LLM의 Emergent Abilities를 끌어올리고 특정 작업 수행 능력 향상
1.2 Prompt의 구성 요소
- Task Instruction: 수행할 작업에 대한 지시사항
- Demonstrations (Examples): 작업 수행 예시
- Query: 실제 수행할 작업 내용
1.3 주요 Prompt Engineering 기법
1.3.1 Chain-of-Thought (CoT) Prompting
- 특징: 단계적 사고 과정을 유도
- 효과: 수학적 추론, 상식 추론 등에서 성능 향상
- 한계: 복잡한 문제에 대한 제한적 효과
1.3.2 Least-to-Most Prompting
- 방법: 복잡한 문제를 하위 문제로 분해하여 순차적 해결
- 장점: 복합적 추론 능력 향상, 특히 SCAN 같은 compositional generalization 작업에서 효과적
1.3.3 Automatic Chain of Thought
- 목적: 수동으로 작성된 CoT 예시의 한계 극복
- 방법: 유사도 기반 예제 검색과 클러스터링을 통한 다양성 확보
1.3.4 Plan-and-Solve Prompting
- 특징: 계획 수립 후 문제 해결
- 효과: Zero-shot 설정에서도 few-shot CoT에 준하는 성능 달성
1.3.5 Self-Instruct
- 목적: 고품질 instruction 데이터셋 자동 생성
- 방법: LLM을 활용한 instruction 생성 및 필터링
1.3.6 Prompt Order Optimization
- 문제: Few-shot 예제 순서에 따른 성능 변동
- 해결책: Entropy 기반 최적 순서 탐색
1.3.7 Unified Demonstration Retriever
- 목적: 범용적인 예제 검색기 개발
- 방법: 다양한 작업의 데이터로 학습된 단일 검색기 사용
1.3.8 Self-Consistency
- 특징: 다양한 추론 경로 생성 및 일관성 있는 답변 선택
- 효과: Zero-shot CoT 성능 향상
1.3.9 Verify-and-Edit Framework
- 목적: CoT 추론의 중간 단계 오류 검증 및 수정
- 방법: 외부 지식원 활용 및 Self-Consistency 기반 검증
1.3.10 Promptbreeder
- 특징: 자기 참조적, 자기 개선적 프롬프트 진화
- 방법: 프롬프트 돌연변이와 진화 알고리즘 적용
1.4 Prompt Engineering의 도전 과제
- 일반화 능력: 다양한 작업과 도메인에 적용 가능한 프롬프트 설계
- 효율성: 최소한의 예시로 최대 성능 달성
- 견고성: 입력 변화에 강건한 프롬프트 개발
- 윤리성: 편향과 부적절한 출력 방지
2. LLM Tools
2.1 LangChain
2.1.1 개요
- 정의: LLM 애플리케이션 개발을 위한 프레임워크
- 특징: 모듈화된 컴포넌트 제공, 쉬운 LLM 통합
2.1.2 주요 기능
- Model I/O: 프롬프트 관리, LLM 인터페이스
- Retrieval: 외부 데이터 소스 연동
- Agents: LLM 기반 자동화된 작업 수행
- Chains: 여러 컴포넌트의 조합 및 워크플로우 생성
2.1.3 장점
- 빠른 프로토타이핑
- 다양한 LLM 및 도구와의 호환성
- 복잡한 LLM 애플리케이션 개발 간소화
2.2 AutoGPT
2.2.1 개요
- 정의: 자율적으로 목표를 달성하는 AI 에이전트
- 특징: GPT 모델 간 상호작용을 통한 복잡한 작업 수행
2.2.2 주요 기능
- 목표 기반 작업 수행
- 자체 계획 수립 및 실행
- 인터넷 검색, 파일 조작 등 다양한 도구 활용
2.2.3 응용 분야
- 코딩 자동화
- 복잡한 리서치 작업
- 창의적 콘텐츠 생성
2.2.4 한계 및 주의점
- 완전한 자율성으로 인한 예측 불가능한 결과 가능성
- 윤리적, 법적 고려사항 필요
2.3 Scikit-LLM
2.3.1 개요
- 정의: LLM을 Scikit-learn 스타일로 사용할 수 있게 해주는 라이브러리
- 목적: 머신러닝 워크플로우에 LLM 쉽게 통합
2.3.2 주요 기능
- Scikit-learn 호환 LLM 래퍼 제공
- 텍스트 분류, 요약 등 일반적인 NLP 작업 지원
- 다양한 LLM과의 호환성
2.3.3 장점
- 기존 머신러닝 파이프라인과의 쉬운 통합
- 표준화된 인터페이스로 LLM 실험 용이
- 데이터 과학자들에게 친숙한 API
1. Multilingual Pre-trained Models
1.1 mBERT (Multilingual BERT)
- 특징: 102개 언어의 위키피디아 데이터로 학습
- 학습 방법: MLM (Masked Language Modeling), NSP (Next Sentence Prediction)
- 한계: 언어 간 사상을 위한 특별한 기술 미사용
1.2 XLM (Cross-lingual Language Model)
- 특징: 언어 임베딩을 사용한 Translation Language Modeling (TLM) 도입
- 모델: XLM-17 (17개 언어), XLM-100 (100개 언어)
- 성과: 소수 언어에 대한 성능 향상
1.3 MASS (Masked Sequence to Sequence Pre-training)
- 특징: BERT와 Seq2Seq 학습의 간극 해소
- 방법: 연속된 일부분 마스킹 후 예측
1.4 mBART
- 특징: BART의 다국어 버전, Denoising Auto-Encoding 사용
- 모델: mBART-25 (25개 언어), mBART-50 (50개 언어)
- 성과: 번역 태스크에서 높은 성능, 특히 저자원 언어에서 효과적
1.5 mT5
- 특징: T5의 다국어 버전, Text-to-Text 프레임워크
- 규모: 최대 13B 파라미터, 101개 언어 지원
- 성과: 모델 크기 증가에 따른 성능 향상, 단일 언어 모델과의 격차 감소
2. Multilingual Large Language Models
2.1 다국어 코퍼스로 학습된 LLMs
2.1.1 PaLM (Google)
- 규모: 540B 파라미터, 780B 토큰
- 언어: 100개 이상 언어 지원 (78% 영어, 22% 비영어)
- 특징: 무손실 어휘집 구축, 다양한 NLP 태스크에서 높은 성능
2.1.2 LLaMA 및 LLaMA 2 (Meta)
- LLaMA: 7B-65B 모델, 20개 언어로 사전학습
- LLaMA 2: 7B-70B 모델, 90% 영어, 10% 비영어 데이터 사용
2.1.3 Alpaca (Stanford)
- 특징: LLaMA 1 기반, Instruction Tuning 적용
- 한계: SFT 시 영어로만 학습
2.1.4 Falcon
- 규모: 7B, 40B, 180B 모델
- 언어: 주로 영어, 독일어, 스페인어, 프랑스어에 능숙
2.1.5 RedPajama
- 특징: 완전 개방형 LLM을 위한 데이터 프로젝트
- 언어: 영어, 독일어, 프랑스어, 이탈리아어, 스페인어
2.2 다국어 답변이 뛰어난 LLMs
2.2.1 PolyLM (Alibaba)
- 특징: 18개 언어로 학습, 오픈소스
- 성과: 다국어 태스크에서 다른 오픈소스 LLM 대비 높은 성능
2.2.2 BLOOM
- 규모: 176B 파라미터, 59개 언어 지원
- 특징: 70% 비영어 데이터 사용, 오픈소스
2.2.3 PaLM 2 (Google)
- 규모: 약 340B 파라미터 (추정)
- 특징: 100개 이상 언어 지원, 다양한 언어의 뉘앙스 이해
2.2.4 GPT-3.5 / GPT-4 (OpenAI)
- 특징: 소수 언어 포함 대부분의 언어에서 최고 성능
- 평가: GPT-4는 현재 가장 우수한 다국어 LLM으로 평가됨
3. Multilingual LLM Benchmark
3.1 주요 벤치마크 및 데이터셋
- LASER/LASER2: 다국어 문장 임베딩
- Flores 시리즈: 저자원 언어 기계 번역 평가
- WikiMatrix: 위키피디아 기반 병렬 문장
- CCMatrix: 웹 기반 고품질 병렬 문장
- NLLB 200: 200개 언어 지원 모델 및 데이터셋
3.2 MEGA (Multilingual Evaluation of Generative AI)
- 특징: 70개 언어, 16개 데이터 벤치마크
- 평가 영역: 상식 추론, NLI, QA, 시퀀스 라벨링, 자연어 생성, 책임 있는 AI 등
3.3 Open Multilingual LLM Evaluation Leaderboard
- 평가 벤치마크: AI2 Reasoning Challenge, HellaSwag, MMLU, TruthfulQA
- 지원 언어: 29개 언어
1. Multimodal Pre-trained Models (PLMs)
1.1 개요
- 정의: 여러 데이터 형태(이미지, 텍스트, 오디오, 비디오 등)를 처리할 수 있는 사전학습 모델
- 주요 유형: Image-Text, Audio-Text, Video-Text Multimodal
1.2 Image-Text Multimodal
1.2.1 CLIP (Contrastive Language-Image Pre-training)
- 목적: 이미지와 텍스트의 공통 임베딩 공간 학습
- 방법: Contrastive Learning
- 특징:
- Zero-shot 추론 가능
- Fine-grained 분류에서 강점
1.2.2 FILIP (Fine-grained Interactive Language-Image Pre-Training)
- 개선점: 이미지 패치와 텍스트 토큰 간 세밀한 상호작용
- 성능: CLIP 대비 이미지 분류 및 검색 성능 향상
1.2.3 BLIP
- 특징:
- CapFlit 구조로 웹 데이터 노이즈 해결
- 세 가지 손실 함수 사용 (Contrastive, Language Modeling, Matching)
- 구조: ViT (Image Encoder), 사전학습된 BERT (Text Encoder)
1.3 Other Multimodals
1.3.1 Whisper (Audio-Text)
- 특징:
- 다국어 대규모 음성 데이터셋 사용
- 멀티태스크 학습 (음성 활동 감지, 화자 구분, 역 텍스트 정규화)
- 구조: Encoder-Decoder Transformer
- 성능: Zero-shot으로 인간 수준 음성인식 달성
1.3.2 VideoCLIP (Video-Text)
- 구조: Video Encoder (S3D + BERT), Text Encoder (BERT)
- 학습: CLIP과 유사한 Contrastive Learning
- 성능: Zero-shot으로 supervised 모델 능가
2. Multimodal Large Language Models (LLMs)
2.1 Flamingo
- 목적: Few-shot learning 가능한 시각-언어 모델
- 구조:
- 사전학습 Image Encoder (CLIP)
- 사전학습 Language Model (Chinchilla)
- Perceiver Resampler (이미지-텍스트 연결)
- 특징:
- Few-shot 학습 가능
- 대화형 사용 가능
2.2 BLIP-2
- 접근법: 사전학습 모델들을 연결하는 Q-Former 도입
- 구조:
- Frozen Image Encoder
- Frozen Large Language Model
- Q-Former (학습 가능한 연결 모듈)
- 학습:
1) Q-Former 사전학습
2) Image-to-Text 생성 사전학습 - 장점: 적은 학습 파라미터로 높은 성능 달성
2.3 LLaVA (Language and Vision Assistant)
- 특징: GPT-4로 생성한 Instruction 데이터로 학습
- 구조:
- 사전학습 LLM
- 사전학습 CLIP Image Encoder
- 학습 과정:
1) CC3M 데이터로 Projection Layer만 학습
2) 생성된 Instruction 데이터로 Fine-tuning - 성능: 상세 설명, 대화, 추론 능력 향상
2.4 Gemini (Google)
- 특징:
- 시각, 비디오, 오디오, 언어 통합 모델
- 38개 언어 지원
- 능력: 다양한 Vision, NLP 태스크 수행
- 한계: 자세한 학습 방법 및 모델 구조 비공개
1. 간단한 전이학습 방법
1.1 Instruction Tuning
- 방법: 목표 언어에 대한 Instruction Tuning만 진행
- 조건:
- 낮은 OOV (Out of Vocabulary) rate
- 소스 언어와 목표 언어의 높은 유사도
- 장점: 간단하고 빠른 학습 가능
- 단점: 성능이 상대적으로 낮을 수 있음
1.2 Vocabulary Extension
- 방법: 기존 Vocabulary에 목표 언어 토큰 추가
- 과정:
- 목표 언어 토큰 추가
- Further Pre-training 또는 Instruction Tuning
- 장점: 목표 언어에 대한 이해도 향상 기대
- 단점:
- 잘 구축된 목표 언어 Vocabulary 필요
- 추가 학습 시간 소요
1.3 Further Pre-training
- 방법: 기존 LLM을 목표 언어로 추가 사전학습
- 조건: 낮은 OOV rate의 Vocabulary 필요
- 장점: 목표 언어에 대한 풍부한 지식 획득
- 단점: 사전학습 코퍼스 구축 및 학습에 많은 자원 소모
2. 모델 및 임베딩 학습 기반 방법
2.1 Adapting Monolingual Model (AMM)
- 방법:
- 목표 언어 임베딩 레이어로 변환
- 임베딩만 Further Pre-training 진행
2.2 Cross-Lingual Post-Training (XPT)
- 과정:
- Phase 1:
- ITL (Implicit Translation Layer) 삽입
- 소스 언어 임베딩을 목표 언어 임베딩으로 교체
- ITL 및 교체된 임베딩만 학습
- Phase 2:
- 전체 모델 Further Pre-training
- Phase 1:
2.3 GPT-recycle
- 방법: 잘 학습된 다른 언어모델의 임베딩 활용
- 특징: 임베딩 차원이 다를 경우 least-squares regression으로 차원 확장
3. 임베딩 정렬 기반 학습 전략
3.1 WECHSEL
- 목적: 소스 언어와 목표 언어 토큰 임베딩을 유사도 기반으로 초기 정렬 후 학습
- 과정:
- 모델 파라미터 복사 및 토크나이저 교체
- 양방향 단어 임베딩 사용
- 서브워드 임베딩 계산
- 서브워드 유사성 계산
- 유사성 기반 목표 언어 서브워드 임베딩 초기화
- Further Pre-training
- 장점: 의미적으로 유사한 토큰 간 정렬을 통해 효과적인 전이 학습
4. Adapter 기반 학습 방법
- 종류: LoRA, QLoRA, Prefix-tuning, P-Tuning 등
- 특징:
- 특정 파라미터만 학습
- 기존 모델의 언어적 특징 유지
- 장점:
- 적은 계산 자원으로 효과적인 전이 학습 가능
- Cross-lingual 학습에 적합
OpenAI 관련 내용 정리
1. 개요
OpenAI는 2015년 설립된 선도적인 인공지능 연구 및 개발 회사
주요 목표는 인류에게 이로운 방식으로 인공 일반 지능(AGI)을 개발하는 것
• AGI란?: 인간 수준 또는 그 이상의 지능을 가진 AI 시스템으로, 다양한 분야에서 인간과 동등하거나 더 뛰어난 성능을 보일 수 있는 기술
• 비영리에서 "capped-profit" 모델로 전환: 초기에는 비영리 단체로 시작했으나, 2019년 "capped-profit" 모델을 도입. (투자자들의 수익을 제한하고 나머지를 회사의 미션에 재투자하는 구조)
• 오픈소스 정책: OpenAI는 초기에 모든 연구를 공개하는 정책을 가졌으나, GPT-3 이후로는 일부 기술에 대해 제한적 공개 정책을 채택
2. 역사
• 2015년: 일론 머스크, 샘 올트먼, 그렉 브록만 등이 10억 달러를 투자하며 설립
• 2016년: 첫 번째 오픈소스 프로젝트 'OpenAI Gym' 출시
• 2018년: GPT-1 발표, 기계 학습의 새로운 지평을 열음
• 2019년: GPT-2 발표, 윤리적 우려로 인해 단계적 공개 결정
• 2020년: GPT-3 발표, 역사상 가장 큰 규모의 언어 모델로 주목받음
• 2021년: DALL-E 및 CLIP 모델 공개, 이미지 생성 및 이해 분야에서 혁신
• 2022년 11월: ChatGPT 출시, 전 세계적으로 폭발적인 인기
• 2023년 3월: GPT-4 발표, 멀티모달 기능 추가
• 2023년 11월: CEO 해임 및 복귀 사태, 새로운 이사회 구성
마이크로소프트의 투자:
• 2019년: 10억 달러 투자
• 2021년: 추가 투자 (금액 미공개)
• 2023년: 100억 달러 투자, OpenAI의 기술에 대한 독점적 라이선스 확보
3. 주요 기술 및 제품
3.1 GPT (Generative Pre-trained Transformer) 시리즈
GPT는 OpenAI의 대표적인 언어 모델 시리즈:
• GPT-1 (2018): 1.17억 개의 매개변수
• GPT-2 (2019): 15억 개의 매개변수
• GPT-3 (2020): 1,750억 개의 매개변수
• GPT-4 (2023): 매개변수 수 비공개, 멀티모달 기능 추가
특징:
- 자연어 이해 및 생성 능력 향상
- 문맥 이해력과 일관성 있는 텍스트 생성
- 다국어 지원 및 번역 능력
- 코드 생성 및 분석 기능
3.2 ChatGPT
ChatGPT는 GPT 모델을 기반으로 한 대화형 AI 시스템:
• 버전: GPT-3.5 기반 (무료), GPT-4 기반 (유료)
• 특징:
- 자연스러운 대화 능력
- 질문에 대한 상세한 답변 제공
- 문맥을 고려한 연속적인 대화 가능
- 다양한 주제에 대한 지식 보유
• 활용 분야: - 고객 서비스
- 교육 및 튜터링
- 창의적 글쓰기 지원
- 프로그래밍 지원
3.3 DALL-E
DALL-E는 텍스트 설명을 바탕으로 이미지를 생성하는 AI 모델:
• DALL-E (2021): 초기 버전, 기본적인 이미지 생성 능력
• DALL-E 2 (2022): 향상된 해상도와 사실성, 이미지 편집 기능 추가
• DALL-E 3 (2023): ChatGPT와 통합, 더욱 정교한 이미지 생성
특징:
- 높은 창의성과 다양성
- 텍스트 프롬프트에 대한 정확한 해석
- 다양한 스타일과 예술적 표현 가능
- 이미지 편집 및 변형 기능
3.4 Whisper
Whisper는 OpenAI의 음성 인식 및 번역 모델:
• 2022년 9월 공개
• 68만 시간 이상의 다국어 음성 데이터로 학습
특징:
- 100개 이상의 언어 지원
- 강력한 잡음 제거 능력
- 다양한 억양과 방언 인식
- 실시간 자막 생성 및 번역 가능
3.5 Codex
Codex는 프로그래밍 코드 생성 및 이해를 위한 AI 모델:
• GPT-3를 기반으로 개발
• GitHub의 수백만 개의 코드 저장소로 학습
특징:
- 자연어를 프로그래밍 코드로 변환
- 다양한 프로그래밍 언어 지원 (Python, JavaScript, Go 등)
- 코드 설명 및 문서화 기능
- GitHub Copilot의 핵심 기술
4. OpenAI API 주요 기능
4.1 텍스트 생성 (Chat Completions API)
Chat Completions API는 GPT 모델을 활용한 대화형 텍스트 생성 인터페이스:
• 지원 모델: GPT-3.5-turbo, GPT-4
• 주요 기능:
- 대화 컨텍스트 유지
- 역할 기반 프롬프트 (시스템, 사용자, 어시스턴트)
- 온도(temperature) 및 상위 확률(top_p) 조절을 통한 창의성 제어
- 토큰 제한 설정
• 고급 기능: - 함수 호출 (Function calling): API가 특정 함수를 호출하여 외부 데이터나 서비스와 상호작용
- GPT-4 Vision: 이미지 입력 처리 및 분석
- 스트리밍 응답: 실시간으로 텍스트 생성 결과 전송
활용 사례:
- AI 챗봇 및 가상 비서
- 자동 이메일 응답 시스템
- 콘텐츠 생성 도구 (기사, 광고 카피, 시나리오 등)
- 코드 자동 완성 및 설명
4.2 임베딩 (Embeddings)
임베딩은 텍스트를 고차원 벡터 공간으로 변환하는 기술:
• 주요 모델: text-embedding-ada-002
• 특징:
- 1536차원의 벡터 표현
- 의미적 유사성 계산 가능
- 다국어 지원
• 활용 분야: - 의미 기반 검색 엔진
- 문서 분류 및 클러스터링
- 추천 시스템
- 이상 탐지 (Anomaly detection)
구현 방법:
1. 텍스트를 임베딩 벡터로 변환
2. 벡터 간 코사인 유사도 계산
3. 유사도에 기반한 작업 수행 (검색, 분류 등)
4.3 파인튜닝 (Fine-tuning)
파인튜닝은 사전 훈련된 모델을 특정 작업이나 도메인에 최적화하는 과정:
• 지원 모델: GPT-3.5-turbo, Babbage-002, Davinci-002
• 장점:
- 특정 도메인에 대한 성능 향상
- 일관된 출력 형식 유지
- API 호출 비용 절감
- 더 짧은 프롬프트로 원하는 결과 도출
파인튜닝 과정:
1. 훈련 데이터 준비 (프롬프트-완료 쌍)
2. 데이터 검증 및 전처리
3. 파인튜닝 작업 생성 및 실행
4. 모델 평가 및 반복
5. 파인튜닝된 모델 배포 및 사용
활용 사례:
- 기업 특화 챗봇
- 특정 분야의 전문 지식 시스템 (법률, 의료 등)
- 브랜드 특화 콘텐츠 생성기
4.4 DALL-E 인터페이스 (이미지 생성)
DALL-E API를 통해 텍스트 프롬프트 기반의 이미지 생성이 가능:
• 주요 기능:
- 텍스트 기반 이미지 생성
- 이미지 편집 (인페인팅, 아웃페인팅)
- 이미지 변형
• 매개변수: - 크기: 256x256, 512x512, 1024x1024 픽셀
- 생성 이미지 수: 1-10장
- 응답 형식: URL 또는 Base64 JSON
활용 분야:
- 디지털 아트 및 일러스트레이션
- 제품 디자인 및 프로토타이핑
- 마케팅 및 광고 시각 자료
- 게임 및 애니메이션 캐릭터 디자인
주의사항:
- 저작권 및 윤리적 사용에 대한 고려 필요
- 생성된 이미지의 품질 및 일관성 확인 중요
4.5 Whisper 인터페이스 (음성 처리)
Whisper API는 강력한 음성 인식 및 번역 기능을 제공:
• 주요 기능:
- 음성-텍스트 변환 (Transcription)
- 음성 번역 (Translation)
- 텍스트-음성 변환 (Text-to-Speech, 신규 기능)
• 지원 형식: - 입력: mp3, mp4, mpeg, mpga, m4a, wav, webm
- 출력: json, text, srt, verbose_json, vtt
• 옵션: - 언어 지정 (optional)
- 프롬프트 (음성 내용에 대한 힌트 제공)
- 온도 설정 (디코딩 확실성 조절)
활용 사례:
- 자동 자막 생성 시스템
- 다국어 회의 실시간 통역
- 음성 명령 기반 AI 비서
- 콜센터 음성 데이터 분석
4.6 GPT Builder 및 Custom GPTs
GPT Builder는 사용자 맞춤형 AI 모델을 쉽게 만들 수 있는 도구:
• 주요 기능:
- 모델 성격 및 전문 분야 정의
- 사용자 지정 지식 베이스 추가
- 대화 시작 문구 설정
- 외부 API 연동 (Actions)
• 특징: - 코딩 없이 AI 모델 커스터마이징
- 웹 인터페이스를 통한 쉬운 설정
- 빠른 프로토타이핑 및 테스트
Custom GPT 구축 과정:
1. 목적 및 전문 분야 정의
2. 성격 및 톤 설정
3. 지식 베이스 업로드 (문서, 웹사이트 등)
4. 대화 예시 작성
5. 외부 도구 연동 (선택사항)
6. 테스트 및 반복 개선
활용 예:
- 기업 내부 지식 관리 시스템
- 특정 분야 전문가 AI (법률, 의료, 금융 등)
- 개인화된 학습 도우미
- 브랜드 특화 고객 서비스 봇
네, 이어서 계속하겠습니다.
5. 윤리적 고려사항 및 논란
5.1 AI의 편향성과 오류 가능성
• 문제점:
- 학습 데이터의 편향성이 AI 모델의 출력에 반영
- 성별, 인종, 문화적 고정관념 등의 편향 존재
- 사실과 다른 정보 생성 가능성 (환각)
• 대응 방안:
- 다양성을 고려한 학습 데이터 구성
- 지속적인 모니터링 및 편향 감지 시스템 구축
- 사용자에게 AI의 한계 명시 및 정보 검증 권장
5.2 개인정보 보호 문제
• 우려사항:
- 대화 내용을 통한 개인정보 수집 가능성
- 학습 데이터에 포함된 개인정보 보호 문제
- AI 모델을 통한 개인 식별 가능성
• 대응 방안:
- 엄격한 데이터 익명화 정책 시행
- 사용자 데이터 보관 및 사용에 대한 투명성 제고
- GDPR 등 국제 개인정보 보호 규정 준수
5.3 AI가 일자리에 미치는 영향
• 잠재적 영향:
- 반복적이고 예측 가능한 업무의 자동화
- 창의적 분야에서의 AI 활용 증가
- 새로운 AI 관련 직종 창출
• 대응 방안:
- AI와 협업할 수 있는 인력 교육 및 재훈련
- AI 윤리 및 관리 전문가 양성
- 인간-AI 협업 모델 개발 및 연구
5.4 AGI 개발의 잠재적 위험성
• 우려사항:
- 통제 불가능한 초지능 AI 등장 가능성
- AI의 자율적 의사결정에 따른 윤리적 문제
- 군사 및 보안 분야에서의 악용 가능성
• 대응 방안:
- AI 안전성 연구 강화
- 국제적 AI 개발 가이드라인 수립
- AI 개발의 단계적 접근 및 지속적인 위험 평가
5.5 AI 생성 콘텐츠의 저작권 문제
• 쟁점:
- AI 생성 작품의 저작권 귀속 문제
- 기존 저작물을 학습한 AI 모델의 법적 지위
- AI 생성 콘텐츠의 상업적 이용에 대한 규제
• 대응 방안:
- AI 생성 콘텐츠에 대한 새로운 법적 프레임워크 개발
- 저작권자와 AI 개발자 간의 협력 모델 구축
- AI 생성 콘텐츠 표시 의무화 검토
6. 향후 전망
6.1 AGI 개발을 향한 지속적인 연구
• 목표:
- 인간 수준 또는 그 이상의 일반 지능 개발
- 다중 작업 처리 능력을 갖춘 AI 시스템 구현
• 전망:
- 신경과학과 AI의 융합 연구 확대
- 대규모 언어 모델을 넘어선 새로운 AI 아키텍처 등장 가능성
6.2 산업 분야별 AI 적용 확대
• 의료:
- 정확한 진단 및 개인화된 치료법 개발
- 신약 개발 프로세스 가속화
• 교육:
- 개인 맞춤형 학습 시스템 구축
- AI 튜터를 활용한 교육 방식 혁신
• 금융:
- 고도화된 리스크 분석 및 투자 전략 수립
- 금융 사기 탐지 시스템 강화
• 환경:
- 기후 변화 예측 및 대응 전략 수립
- 친환경 기술 개발에 AI 활용
6.3 AI 기술 경쟁 심화
• 주요 경쟁사:
- Google (DeepMind)
- Meta AI
- Microsoft
- Anthropic
• 경쟁 분야:
- 대규모 언어 모델의 성능 향상
- 멀티모달 AI 시스템 개발
- AI 모델의 효율성 및 경량화
6.4 AI 규제 및 윤리 가이드라인 발전
• 국제적 협력:
- AI 개발 및 사용에 대한 글로벌 표준 수립
- 국가 간 AI 기술 및 데이터 공유 협약
• 법적 프레임워크:
- AI 결정에 대한 책임 소재 명확화
- AI 사용의 투명성 및 설명 가능성 요구 강화
• 윤리적 AI 개발:
- AI 윤리 위원회의 역할 확대
- 기업의 AI 윤리 준수 의무화
6.5 AI와 인간의 공존 모델 구축
• 일자리 변화 대응:
- AI 보조 도구를 활용한 직무 재설계
- 평생 학습 및 재교육 시스템 강화
• 인간-AI 협업:
- 인간의 창의성과 AI의 효율성을 결합한 새로운 작업 방식 개발
- AI 리터러시 교육의 중요성 증대
• 사회적 영향:
- AI 기술 접근성 격차 해소를 위한 정책 수립
- AI 윤리 교육의 일반화
