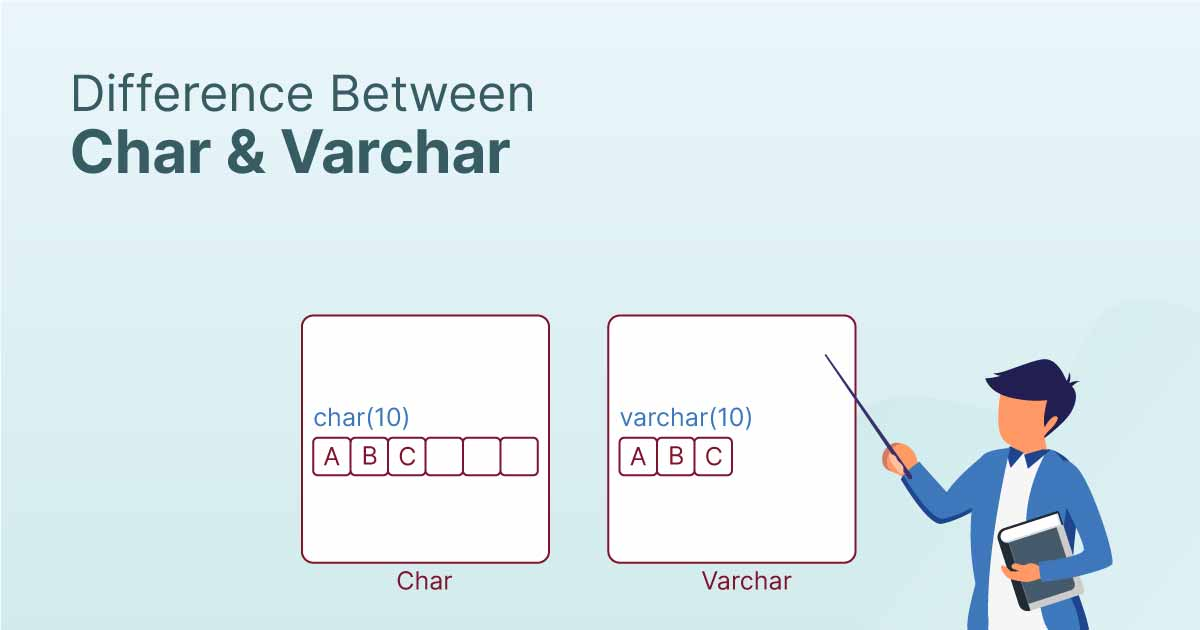
변수나 속성의 데이터 타입을 정할때 뭐를 사용해야 될까요?
CREATE TABLE emp (
id INT UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
regDate DATETIME NOT NULL,
`name` CHAR(100) NOT NULL,
deptId INT UNSIGNED NOT NULL,
salary INT UNSIGNED NOT NULL
);-
CHAR(100)일 때의 메모리 동작
- 고정 길이: name 필드가 100바이트로 항상 고정된 공간을 차지합니다.
- 데이터 저장 예시:
- 이름이 "홍길동"이면 '홍길동' + 97개의 공백을 저장합니다.
- 저장 공간: name 필드당 100바이트.
-
VARCHAR(100)일 때의 메모리 동작
- 가변 길이: name 필드는 실제 데이터 길이에 따라 유동적으로 공간을 할당합니다.
- 데이터 저장 예시:
- 이름이 "홍길동"이면 3바이트(홍길동) + 1~2바이트(길이 정보)만 저장됩니다.
- 저장 공간: 짧은 문자열일수록 적은 바이트를 사용.
CHAR(100)와 VARCHAR(100)의 차이점
둘 다 문자열 데이터를 저장하기 위한 필드 타입이지만, 저장 방식과 효율성에서 차이가 있습니다.
CHAR(100)
-
고정 길이 문자열: 입력된 데이터 길이와 상관없이 100자로 고정된 공간을 차지합니다.
-
빈 공간 패딩: 저장된 문자열이 100자보다 짧으면 나머지 공간을 공백 문자로 채웁니다.
[특징]
-
고정된 크기: 문자열이 짧거나 길이에 변동이 없는 경우 적합.
-
빠른 접근 속도: 일정한 크기 덕분에 데이터 접근 속도가 빠릅니다.
[장점]
-
일관된 성능: 모든 행이 동일한 크기를 가지므로, 검색 및 정렬이 빠름.
-
적은 오버헤드: 데이터 크기 관리가 단순.
[단점]
-
비효율적인 공간 사용: 저장된 데이터가 짧을 경우에도 불필요한 공백으로 공간 낭비 발생.
VARCHAR(100)
-
가변 길이 문자열: 입력된 데이터 길이에 따라 동적으로 공간을 할당합니다.
-
최대 100자까지 저장 가능하며, 실제 데이터 길이 + 1~2 바이트(길이 정보 저장용)를 추가로 사용합니다.
[특징]
-
가변 크기: 문자열 길이가 일정하지 않은 경우 적합.
-
효율적인 공간 사용: 입력된 길이만큼만 저장되므로 공간 절약 가능.
[장점]
-
공간 절약: 짧은 문자열 저장 시 디스크 공간을 아낄 수 있음.
-
유연성: 데이터 길이가 변동될 경우에도 효율적.
[단점]
-
오버헤드: 데이터 길이를 저장하기 위한 추가 바이트가 필요.
-
검색 속도 저하: 길이가 다를 수 있으므로 검색 성능이 약간 떨어질 수 있음.
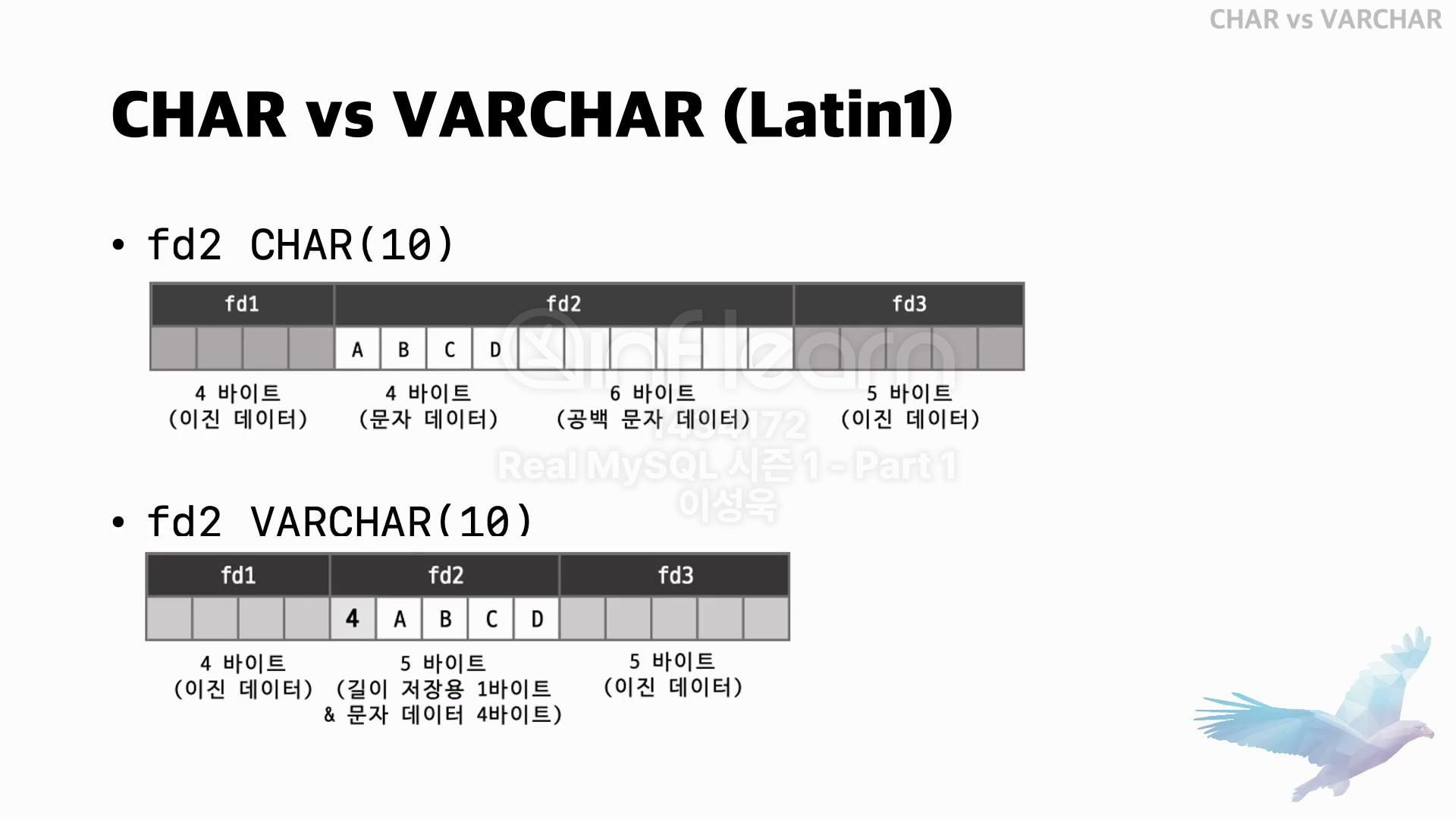
- 위의 사진처럼 똑같이 10바이트의 크기로 변수를 생성했는데 CHAR타입은 문자 데이터가 4바이트여도 10바이트만큼의 저장공간을 차지하고 VARCHAR타입은 문자 데이터 4바이트 + 길이 저장용 1바이트로 필요한 만큼의 저장공간만 차지한다는 점에서 차이가 있습니다.
비교 요약
| 특징 | CHAR(100) | VARCHAR(100) |
|---|---|---|
| 길이 | 고정 길이 | 가변 길이 |
| 공간 사용 | 고정된 크기, 공간 낭비 가능 | 필요한 만큼만 사용 |
| 속도 | 일정한 접근 속도, 빠름 | 길이 계산 필요, 약간 느림 |
| 유연성 | 짧거나 고정된 데이터에 적합 | 길이가 변동되는 데이터에 적합 |
| 공백 처리 | 공백으로 패딩 | 공백 없음 |
사용 예시
CHAR추천 상황: 우편번호, 국가 코드 등 고정 길이 문자열.VARCHAR추천 상황: 사용자 이름, 주소 등 가변 길이 문자열.
그렇다면 검색을 자주하는 데이터 같은 경우는 어떤 타입이 효율적일까요?
CHAR(100)vsVARCHAR(100)- 검색 속도 관점
1.CHAR(100)
- 고정 길이: 모든 값이 동일한 길이를 가지기 때문에, 비교 연산이 간단하고, 검색 속도가 상대적으로 빠릅니다.
- 데이터 정렬 및 검색 효율: 인덱스를 사용할 때 일관된 길이 덕분에 인덱스 접근이 더 빠릅니다.
VARCHAR(100)
- 가변 길이: 각 값의 길이가 다르기 때문에, 비교 연산 시 추가적인 길이 계산이 필요합니다.
- 인덱스 효율: 짧은 데이터라면 인덱스의 크기가 작아져 공간 효율은 높지만, 길이 가변성 때문에 속도는 약간 느려질 가능성이 있습니다.
Tip:
인덱스를 추가해 검색 성능을 최적화할 수 있습니다. VARCHAR 필드에도 인덱스를 잘 활용하면 검색 속도의 차이를 최소화할 수 있습니다.
- 인덱스란? 인덱스(Index)는 테이블의 특정 열에 대해 빠른 검색을 가능하게 하는 데이터 구조입니다. 인덱스를 사용하면 WHERE 절, JOIN, ORDER BY 등의 연산 속도가 크게 향상됩니다.
1. 기본 인덱스 생성 방법
테이블 생성 시 인덱스 추가
CREATE TABLE emp (
id INT UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
regDate DATETIME NOT NULL,
`name` VARCHAR(100) NOT NULL,
deptId INT UNSIGNED NOT NULL,
salary INT UNSIGNED NOT NULL,
INDEX idx_name (`name`) -- name 컬럼에 인덱스 생성
);이미 생성된 테이블에 인덱스 추가
CREATE INDEX idx_name ON emp(`name`);2. 복합 인덱스 (Composite Index)
여러 컬럼을 조합해 인덱스를 생성할 수 있습니다.
예시: name과 deptId에 복합 인덱스 생성
CREATE INDEX idx_name_dept ON emp(`name`, `deptId`);이 인덱스는 name과 deptId를 함께 사용하는 쿼리에서 효과적입니다.
SELECT *
FROM emp
WHERE `name` = '홍길동' AND deptId = 3;3. UNIQUE 인덱스
중복을 허용하지 않는 인덱스입니다.
CREATE UNIQUE INDEX idx_unique_name ON emp(`name`);이 경우, 동일한 name 값이 중복 삽입되지 않음.
4. 인덱스 삭제
DROP INDEX idx_name ON emp;5. 인덱스 조회
테이블의 인덱스를 확인하려면:
SHOW INDEX FROM emp;인덱스 사용 시 주의사항
- 너무 많은 인덱스: 인덱스가 많으면 INSERT, UPDATE, DELETE 성능이 저하될 수 있습니다.
- 선택도(Selectivity): 인덱스 컬럼에 다양한 값이 많을수록 효율적입니다.
- 빈번히 검색되는 컬럼 위주로 인덱스를 설정하세요.
최종 예시
-- 테이블 생성
CREATE TABLE emp (
id INT UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
regDate DATETIME NOT NULL,
`name` VARCHAR(100) NOT NULL,
deptId INT UNSIGNED NOT NULL,
salary INT UNSIGNED NOT NULL,
INDEX idx_name (`name`),
INDEX idx_dept_salary (deptId, salary) -- 복합 인덱스
);
-- 데이터 검색
SELECT *
FROM emp
WHERE `name` = '홍길동';
SELECT *
FROM emp
WHERE deptId = 2 AND salary > 5000;이렇게 하면 검색 속도가 개선됩니다. 😊
