하둡
Hadoop 서버
클라우드에서 사용되는 Hadoop은 하둡 분산 파일 시스템(HDFS)사용
데이터를 빠르게 저장하고 사dyd
DFS (분산 파일 시스템)
하나의 데이터를 일정한 크기로 분할해서 최대 세 곳에 복제하여 실제 사용자가 근처에 데이터를 배치시킴 -> 사용자가 빠르게 데이터를 사용하게 함
Hadoop의 구조는 실제 데이터를 저장하는 Data Node (Client)와 이들을 통제하는 Name Node(Server)로 구성
Setting
hduser 사용자를 생성하고 sudoers 파일에서 su 권한 생성
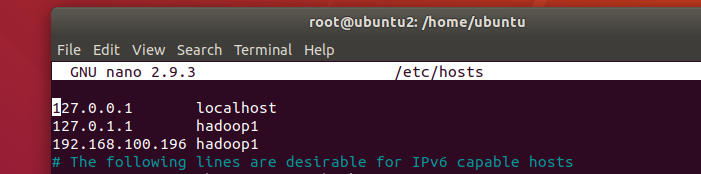
hostname 변경 hadoop1
hosts 파일 수정
JAVA 설치 default-JDK

bashrc 파일에 환경변수 추가
export 내장된 환경변수 값을 추가하여
환경변수는 특정 디렉터리에 값이 저장되어있을 경우 해당 경로로 이동하여 실행파일을 사용해야되는데
PATH를 사용하여 저장하면 어디서나 실행파일을 실행하면 실행이 가능
export로 환경변수 입력
기존 경로 PATH, JAVA_HOME/bin 추가

설정 적용을 위해 source 명령어 사용하여 적용한 뒤 환경 변수 추가

APM install
add-apt-repository ppa:ondrej/php
sudo apt -y install apache2 libapache2-mod-php5.6 openssl php-imagick php5.6-common php5.6-curl php5.6-gd php5.6-imap php5.6-intl php5.6-json php5.6-ldap php5.6-mbstring php5.6-mysql php5.6-pgsql php-smbclient php-ssh2 php5.6-sqlite3 php5.6-xml php5.6-zip --fix-missing && sudo apt -y install mysql-server
sudo chmod 755 -R /home : /home 디렉터리 아래에 있는 권한 설정
3306 mysql 확인
보안 연결을 위한 SSH 설치
sudo apt -y install ssh
sudo ufw disable
hadoop slave들이 ssh로 연결을 위해서 키를 통한 보안 연결을 해야함으로 개인키와 공개키 생성
개인키 공개키는 두 가지 방법으로
서버에서 개인키 공개키를 생성하여 서버에 공개키를 두고 클라이언트에게 개인키 전송
클라이언트에서 설정한 뒤 서버에게 공개키를 전송하는 방법 => 인증된 클라이언트만 SSH 키를 이용하여 인증된 사용자만 NameNode에 접속하게 설정
하둡 서버에서 설정
ssh-keygen -t rsa -P ""
ls -al /home/hduser/.ssh /
cd /home/hduser && cat .ssh/id_rsa.phb >> .ssh/authorized_keys
ls -a .ssh 로 확인
chmod +x .ssh/au :누구라도 인증된 사용자가 인증받을 수 있도록
ssh hduser@localhost : 접속 확인 별도의 로그인 정보 없이 접속이 가능
싱글노드 하둡 설치
하나의 머신이 모든 기능을 다함
싱글 모드로 설정 한 뒤 멀티 모드로 변경하는 것이 일관성 우수

hduser로 hadoop 파일소유자 변경

환경변수에 하둡 경로설정하여 bin과 sbin 파일 추가

환경변수 설정을 통해 해당 경로에 접속하지 않아도 사용할 수 있음
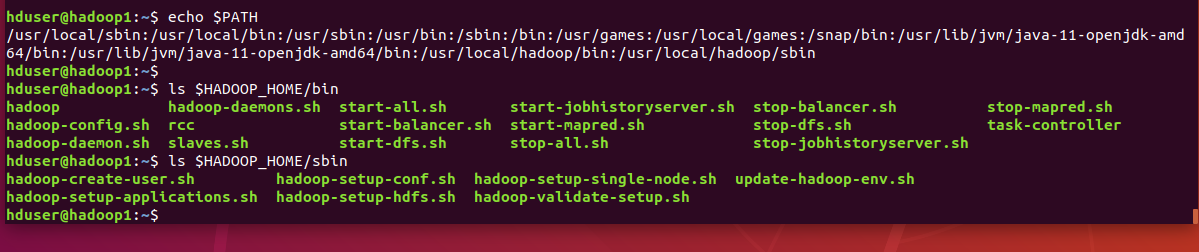
bin 실행파일, sbin 설정파일
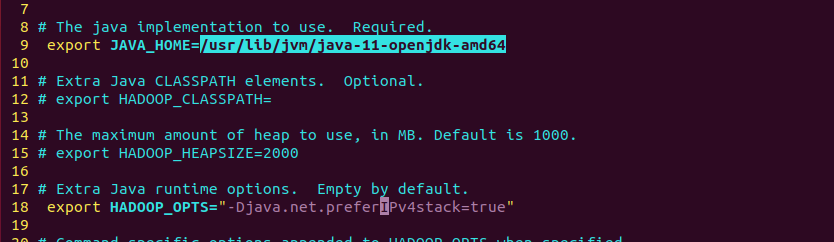
java 경로
/usr/lib/jvm/java-11-openjdk-amd64
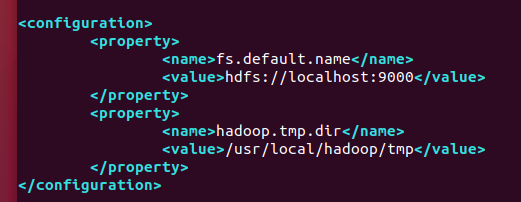
fs.default.name
hdfs://localhost:9000
하둡 환경 설정
conf 파일에서 자바와 하둡 opts 경로 수정
core-site 공통적으로 사용하는 파일로 핵심 파일
mapred-site

hdfs-site
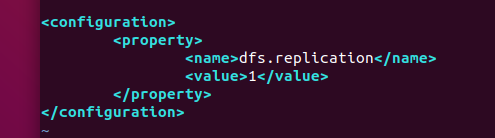
/hadoop 디렉터리 밑에 tmp 파일을 생성하고

hadoop을 포맷

start-all.sh 명령으로 하둡을 실행 한 뒤
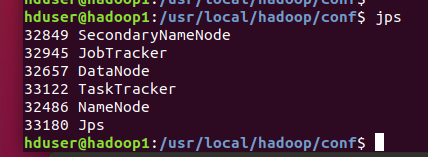
jps로 실행되는 프로세스를 확인 6개의 프로세스 확인
로컬 호스트로 접속

로컬 데이터를 저장하기 위한 디렉터리 생성

여러 텍스트 파일을 생성하여 해당 디렉터리에 저장한 뒤

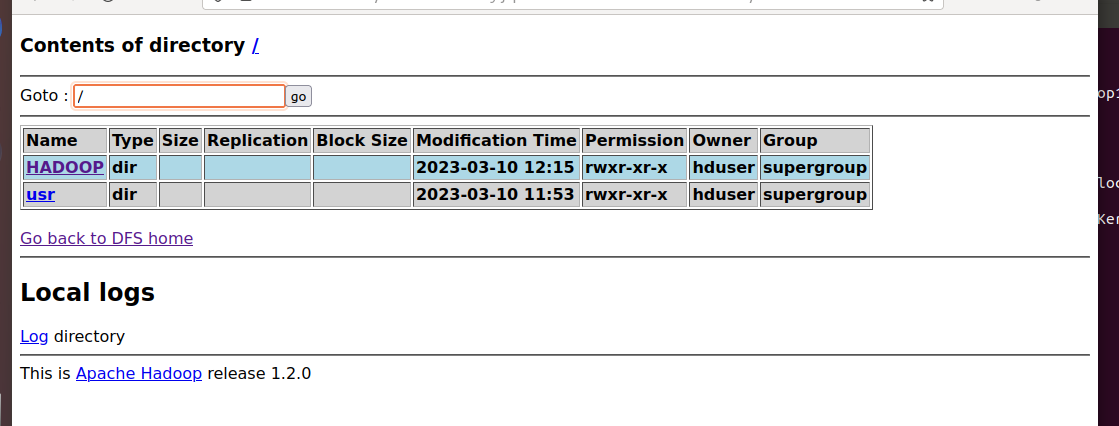
클라우드의 루트 디렉터리 확인
로컬 루트와 클라우드 루트의 위치가 다름
일반 리눅스와 같이 사용
클라우드에 HADDOP 디렉터리를 생성하여 확인
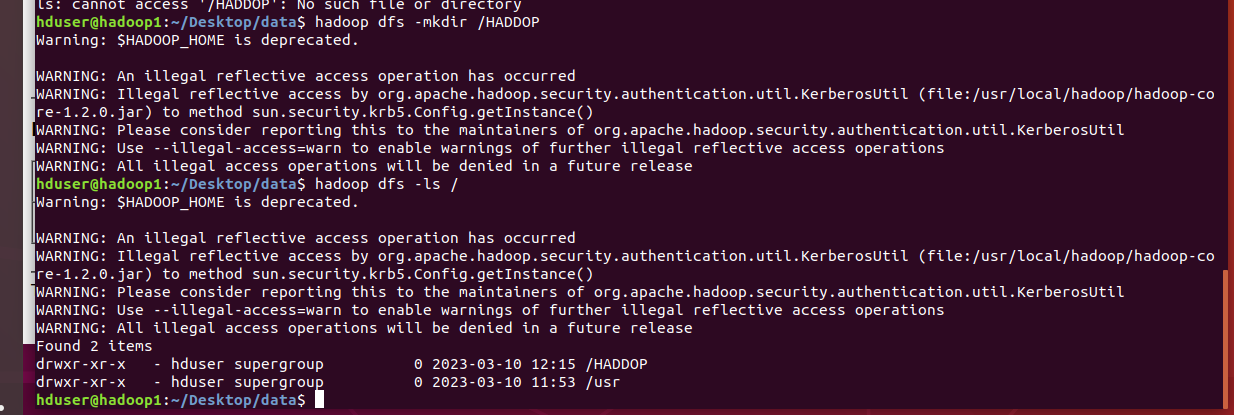
hadoop dfs 명령어를 사용하여 클라우드에서 사용할 수 있는 shell 명령어를 사용
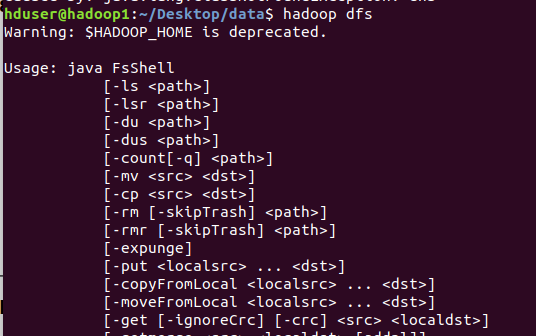
로컬에 있는 파일을 클라우드로 업로드

클라우드 웹 브라우저에서 Browse the filesystem으로 접속하여
디렉터리 안에 있는 파일을 확인 할 수 있음
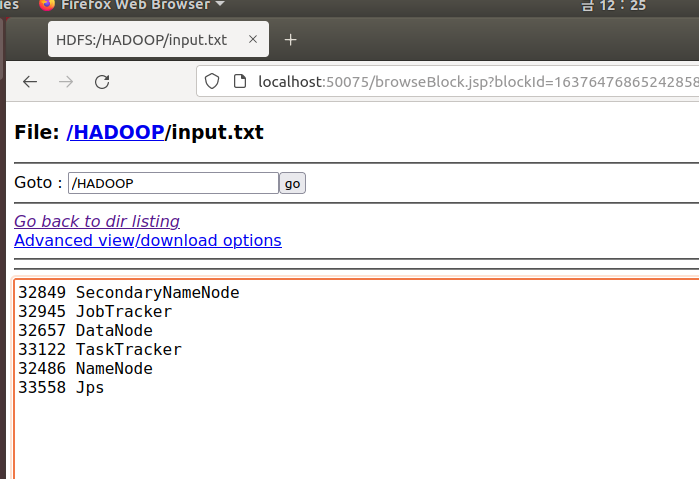
파일을 읽을 수 있음
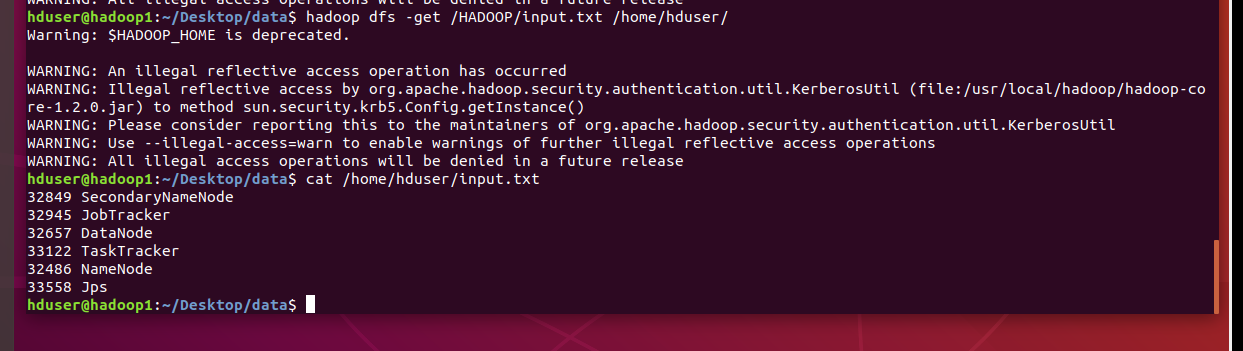
다운로드 받을 수 있음
청크사이즈 : 데이터를 분석할 때
dfs 파일은 분산 파일 시스템 파일
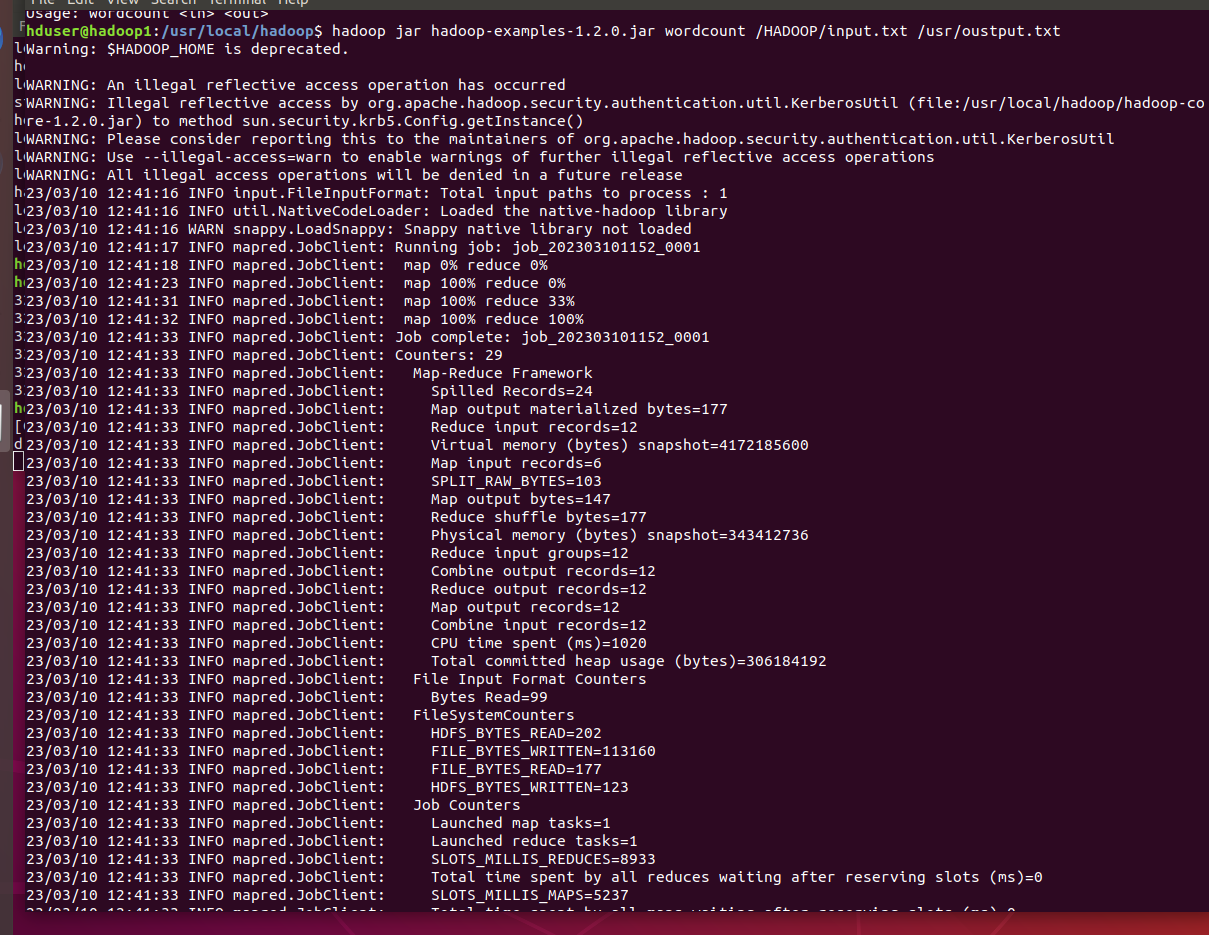
하둡의 로컬하고, 워드 카운트
mapping 작업이 끝나고 reduce 작업 카운트 작업을 실행
mppping은 키와 결과 값을 분리하고 reduce는 메모리에서 데이터를 처리하여 업로드
하둡에 있는 inputtxt. 파일을 클라우드에 /usr/output 파일로 저장
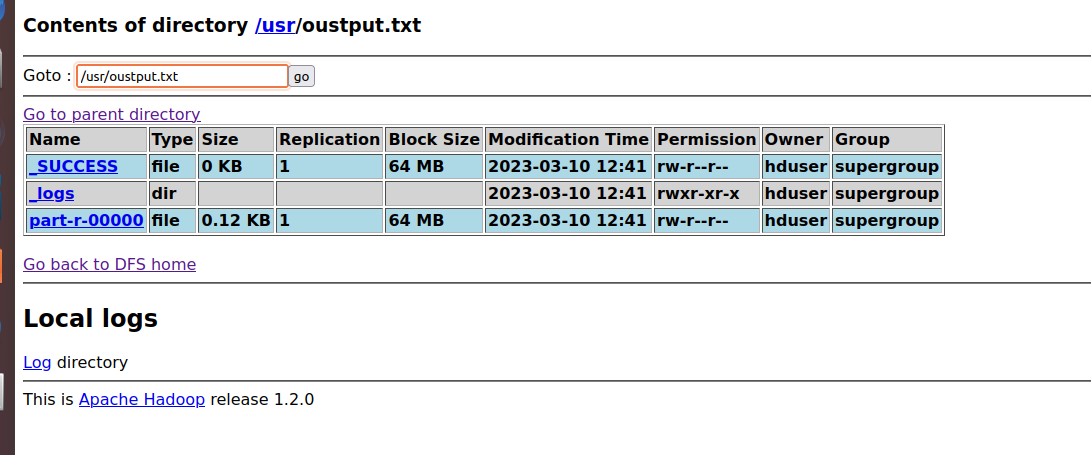
oustput 파일을 열어보면 file의 용량이 작기 때문에 part는 하나가 생성
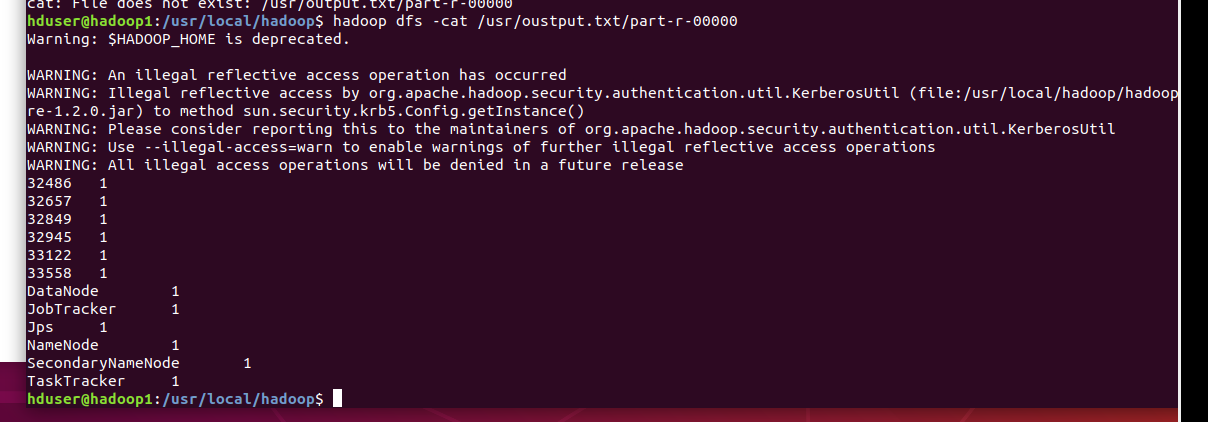
클라우드에서 내용을 다운로드 하지 않고도 cat명령을 이용하여 데이터를 이용할 수 있음
멀티모드 하둡
