BERT 이후의 LM
1. XLNet
기존의 BERT는 Masking된 단어를 예측하는 방식으로 학습이 이뤄진다. 즉, Bert는 Mask 토큰을 독립적으로 판단하기 때문에 토큰 사이의 관계 자체는 학습하는 것이 불가능하다. 또, Embedding Length의 한계로 Segment간 관계를 학습하는 것이 불가능했다. 또, GPT는 단일 방향성으로만 학습을 진행하는 것이 큰 문제였다.
XLNet
XLNet은 아래와 같은 특징을 가진다.
1-1. Relative positional encoding 방식 적용(Transformer-XL)
이 블로그에서 Transformer와 Transformer-XL, XLNet까지의 변화 과정을 잘 리뷰해놓았다.
- Positional encoding은 token간 관계성을 표현하기 위함인데, BERT처럼 0,1,2,3...으로 위치를 표현 하는 것이 아니라, 현재 token의 위치 대비 0번째, 1번째 2번째 ... 상대적 거리 표현법을 사용했다.
- 즉, Sequence 길이에 제한이 없어진다.
1-2. Permutation language modeling
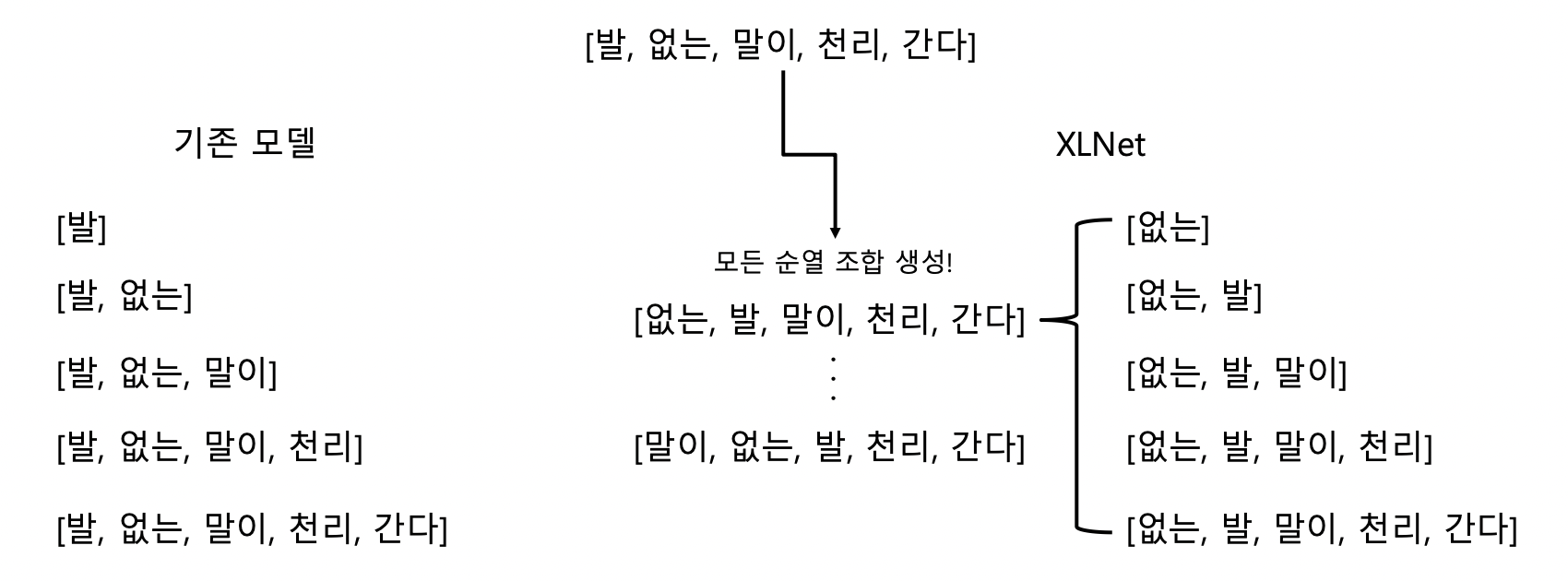
위 방법을 사용하면 한 방향으로만 학습하는 형태를 보완할 수 있게 된다.
2. RoBERTa
RoBERTa는 기존 BERT 구조에서 학습 방법에 변화를 준 형태이다.
- Model 학습 시간 증가
- Batch size 증가
- Train data 증가
- NSP 제거
- Fine tuning과 관계없음
- 너무 쉬운 문제라 오히려 성능 하락
- Dynamic Masking
3. BART
BERT, GPT를 합치면...?
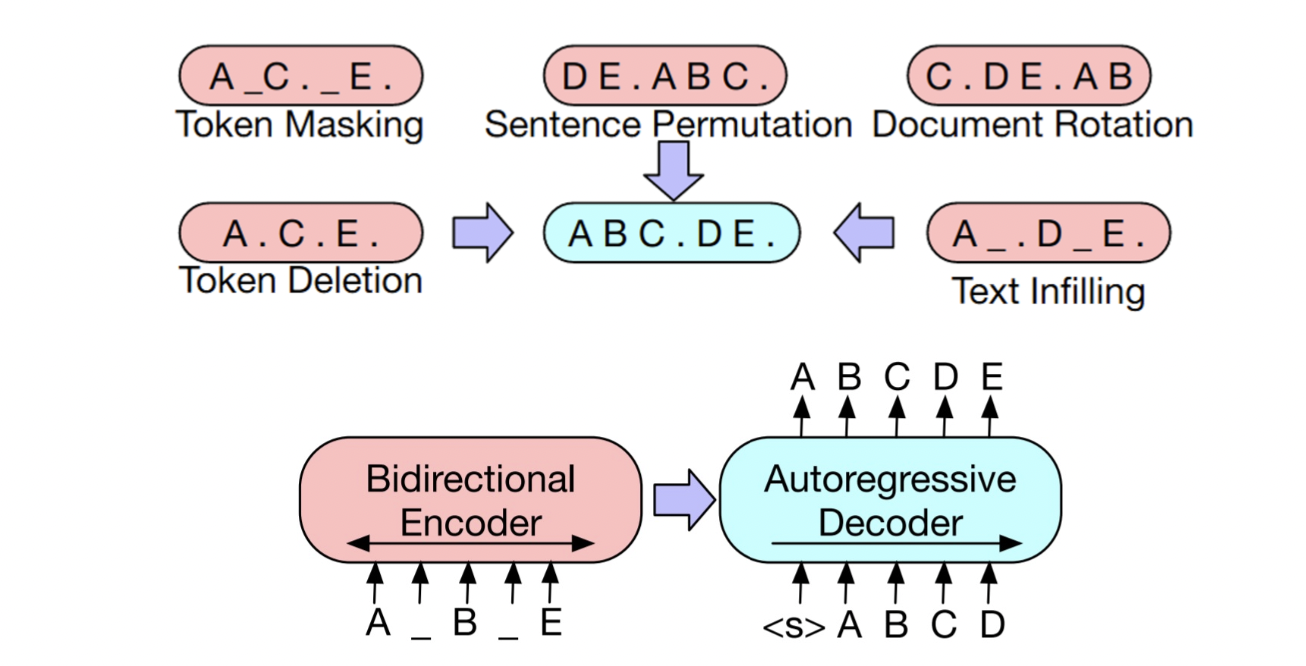
BART 논문 리뷰
BART의 특징
- Token Masking
- Token Deletion
- Sentence Permutation
- Document Rotation
- Text infilling
4. T-5
현재 강의를 촬영하는 시점 자연어 Task의 끝판왕이라고 한다.ㄷ
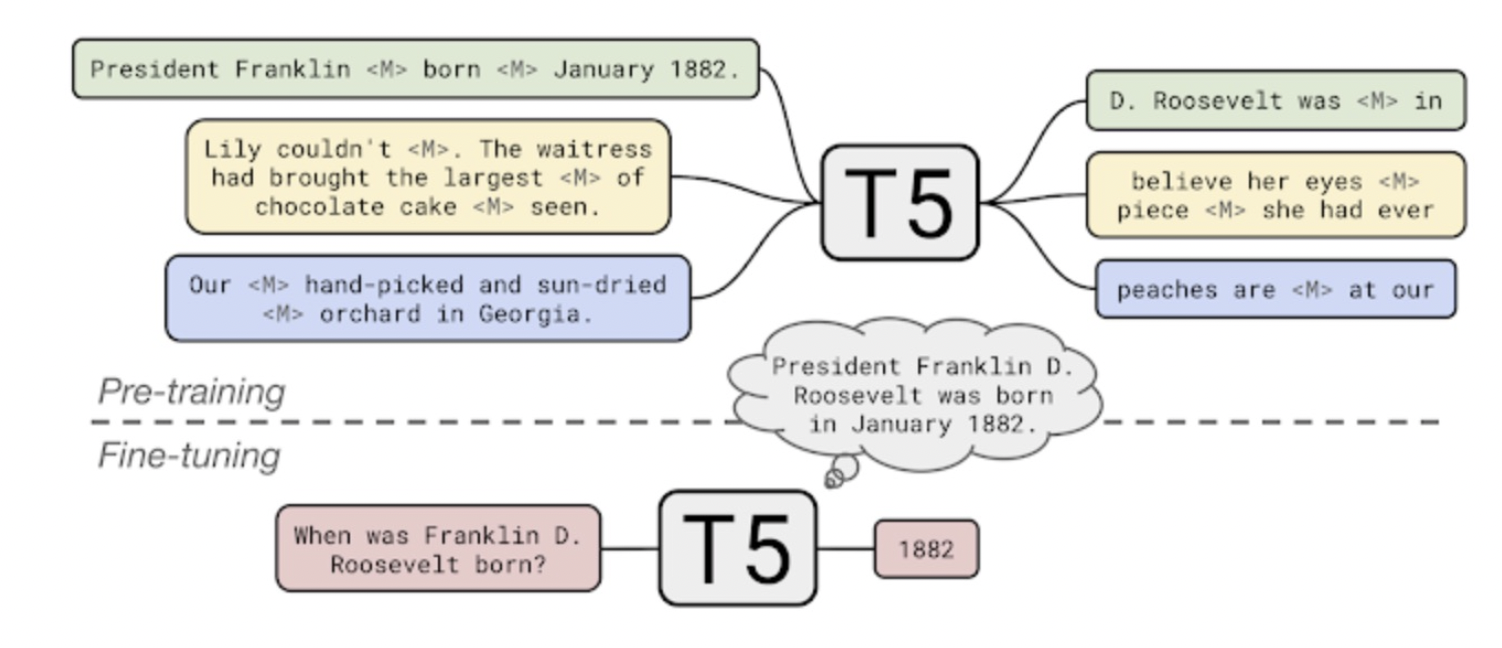
T5의 원리
T5는 마스킹 모델링을 진행하는 형태이지만 한 단어가 아니라 여러 단어를 포함하여 하나의 마스킹으로 처리한다.
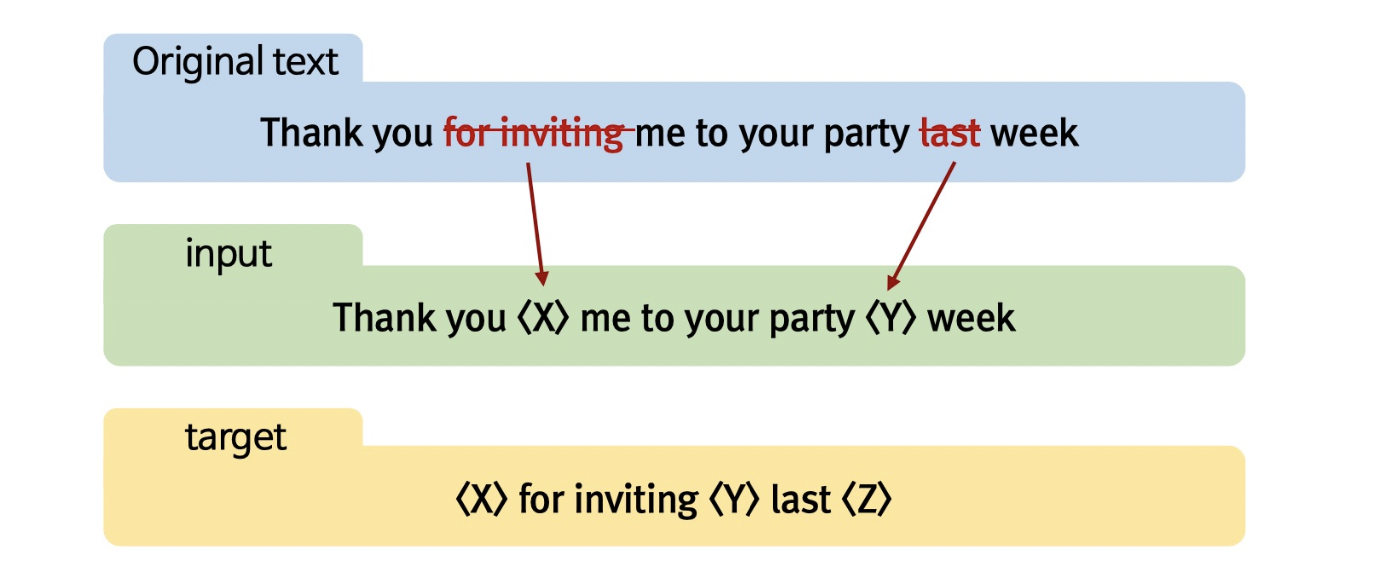
현재 한국어는 mT5로 활용할 수 있다.
5. Meena
대화 모델을 위한 Language Model으로, Transformer Encoder 한 블록과 Decoder 여러 블록을 가지고 만든 모델이다.
-
소셜 미디어의 데이터(341GB, 400억개의 단어) 를 이용하여 26억개의 파라미터를 가진 신경망 모 델을 이용한 end-to-end multi-turn 챗봇
-
챗봇의 평가를 위한 새로운 Metric인 SSA(Sensibleness and Specificity Average) 를 제시
- Sensibleness : 현재까지 진행중인 대화에 가장 적절한 답변을 했는가?
- Specificity : 얼마나 구체적으로 답변할 수 있는가?
하지만 Generation에 있어서 말을 잘 생성해낸다고 좋은 모델이라고 볼 수 있을까? 그렇지 않다. 대표적인 예로, 윤리적인 문제(성별, 인종 등)가 있다. 이런 점들을 완전히 컨트롤 할 수 없고 오직 확률론적인 관점에서 문장을 생성하는 것은 좋은 모델이라고 보기 어려울 수도 있다. 그래서 나온 것이 다음에 나온 Controllable LM이다.
6. Controllable LM
Plug and Play Language Model (PPLM)
기존의 LM들은 다음에 등장할 단어를 확률 분포를 통해서 선택했다.
그러나 PPLM의 경우 내가 원하는 단어들의 확률이 최대가 되도록 이전 상태의 vector를 수정하고, 수정된 vector를 통해 다음 단어 예측
- 확률분포를사용하는것이기때문에,중첩도가능(기쁨+놀람+게임)
- 특정 카테고리에 대한 감정을 컨트롤해서 생성 가능
- 정치적, 종교적, 성적, 인종적 키워드에 대해서는 중성적인 단어를 선택해서 생성
- 범죄 사건에 대해서는 부정적인 단어를 선택해서 생성
- 확률분포 조절을 통해 분노 정도를 조절 가능
그런데,
과연 자연어 to 자연어로 충분할까?
인간이 언어를 배울 때 글이 빼곡히 적혀있는 책만으로 학습하지 않는다. 인간은 무언가를 학습할 때 시각, 청각, 후각, 촉각 등의 다양한 감각으로 세상을 학습한다. 그렇다면 인공지능을 구현할 때 오직 자연어로 만 구성된 모델로 충분할까?
Multi-modal Language Model
1. 할머니세포(Grandmother Cell)
본 article에서 필요한 정보만 요약하자면 다음과 같다. 결국 인간은 특정 정보에 대해서만 반응하는 뉴런 세포가 존재할 수 있다는 것이며, 이 과정에서 단순히 그 사람의 얼굴 사진 뿐만 아니라 그 사람의 이름, 그 사람의 모습을 그린 그림에서도 똑같이 반응하게 된다. 즉 인간은 구조적으로 Multi-modality를 가지고 세상을 학습하고 있는 것이다. 이를 인공지능에 적용해본다면 더욱 세상을 잘 이해하고 나타낼 수 있는 인공지능을 탄생시킬 수 있을 것이다.
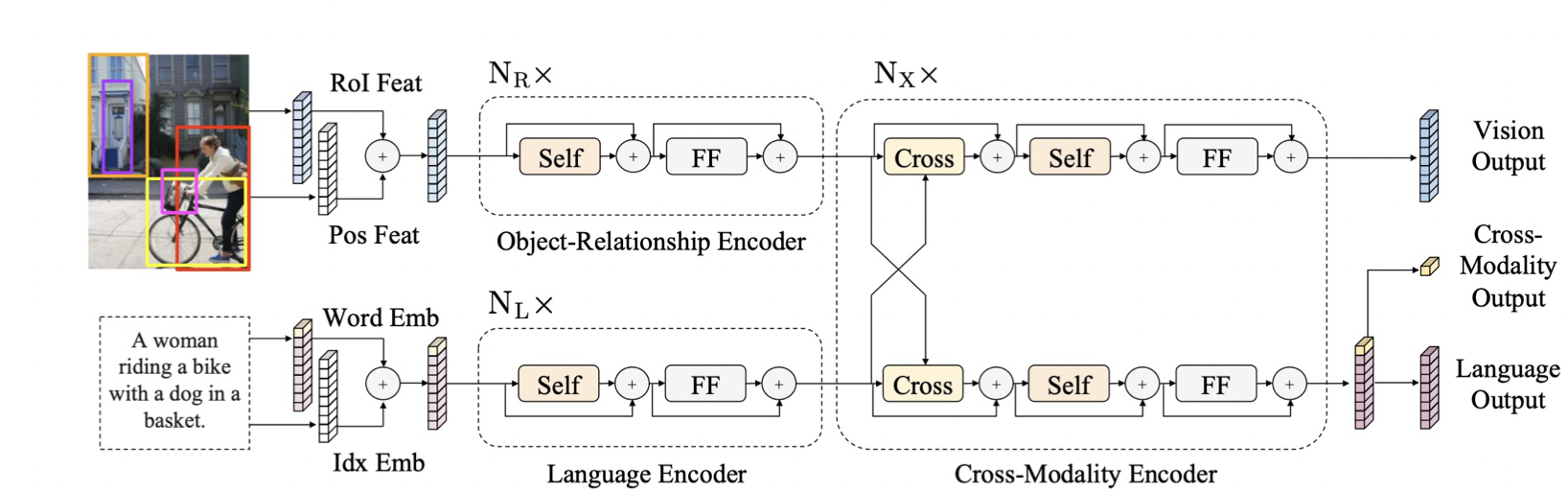
2. LXMERT
이미지와 자연어를 한 번에 같이 학습하고 예측하는 모델이다.
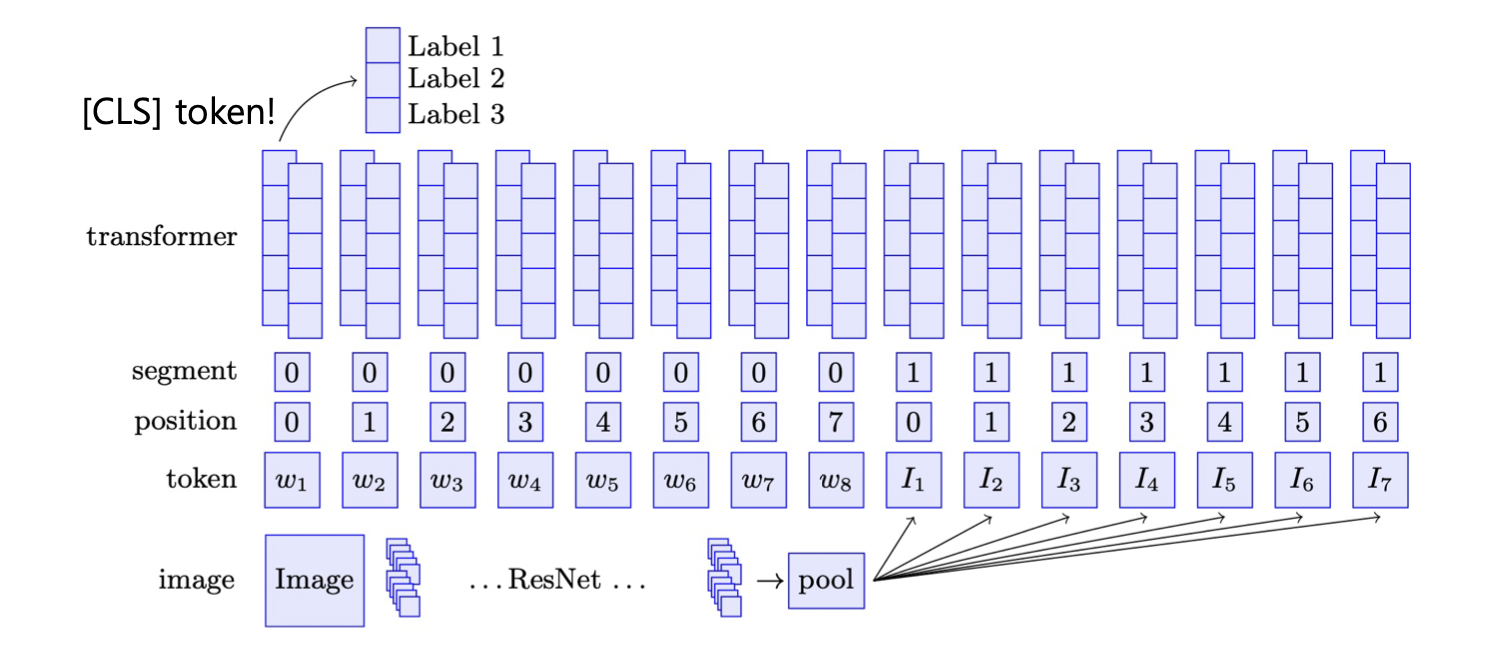
3. ViLBERT
4. Dall-e

1. VQ-VAE를 통해 이미지의 차원 축소 학습
2. Autoregressive 형태로 다음 토큰 예측 학습
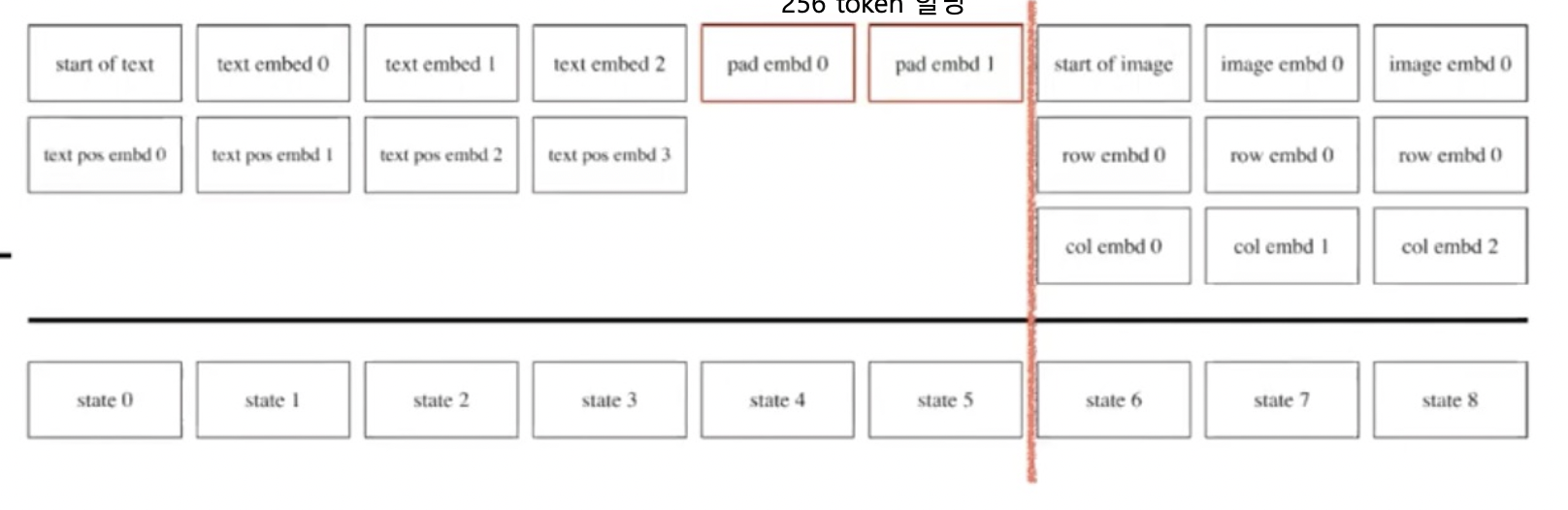
한국어 Dall-e

