
Recent Trends
• Transformer model and its self-attention block has become a general-purpose sequence (or set) encoder and decoder in recent NLP applications as well as in other areas.
• Training deeply stacked Transformer models via a self-supervised learning framework has significantly advanced various NLP tasks through transfer learning, e.g., BERT, GPT-3, XLNet, ALBERT, RoBERTa, Reformer, T5, ELECTRA...
• Other applications are fast adopting the self-attention and Transformer architecture as well as self-supervised learning approach, e.g., recommender systems, drug discovery, computer vision, ...
• As for natural language generation, self-attention models still requires a greedy decoding of words one at a time.
Generative Pre-trained Transformers, GPT-1
Transformer의 Decoder만 사용하여, Special Token을 제안해서 다양한 NLP Task를 해결할 수 있는 통합된 모델을 제안했다는 가장 큰 특징이다.
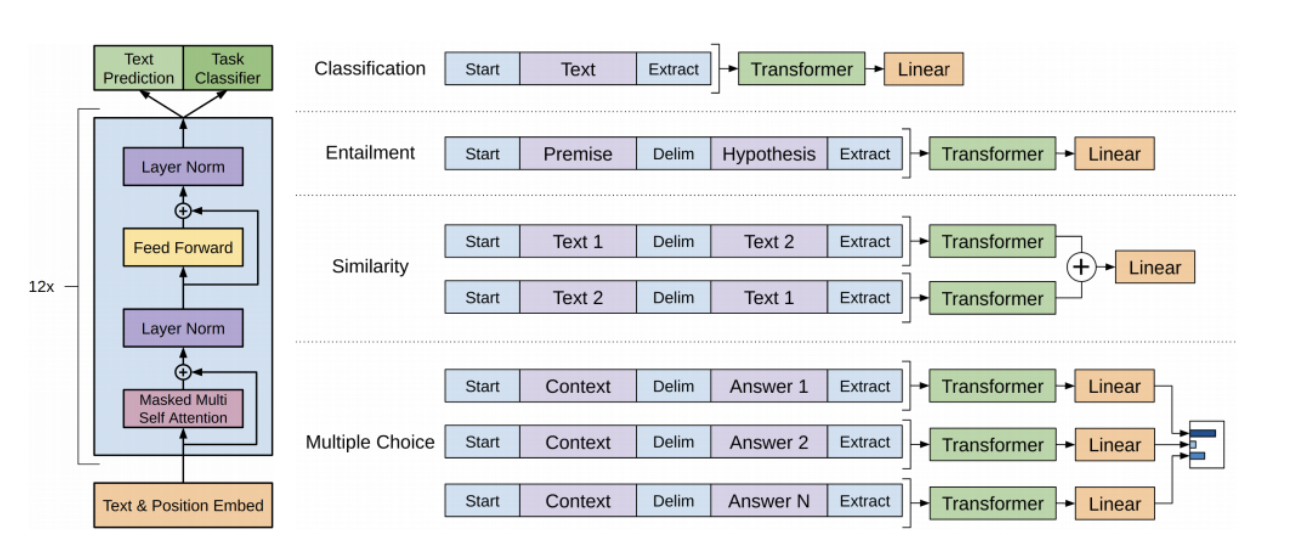
왼쪽 그림은 곧 Text에 Positional Encoding을 취한 후 Self-Attention Block을 12번 지나는 것을 의미한다.
Text Prediction은 첫 단어로 부터 다음 단어를 예측하는 Language Modeling Task를 의미한다.
Task Classifier는 다양한 분류 태스크에 활용할 수 있는 프레임워크를 제안한 것을 의미한다.
GPT는 Start, Extract, Delim 등의 토큰을 사용하여 Pretraining을 하게 되고 이는 다양한 NLP task에서 효과적으로 Fine-tunining을 실시할 수 있게 만든다.
Bidirectional Encoder Representations from Transformers, BERT
BERT Stanford seminar
BERT는 이름에서와 같이 GPT와 달리 Transformer의 Encoder를 Bidirectional하게 사용한 형태이며, 입력값 중간 중간에 Mask 데이터를 넣어서 학습을 한다.
Bert를 요약하자면 다음과 같다.
1. Model Architecture
– BERTBASE: L=12,H=768, A=12
– BERTLARGE: L=24,H=1024, A=16
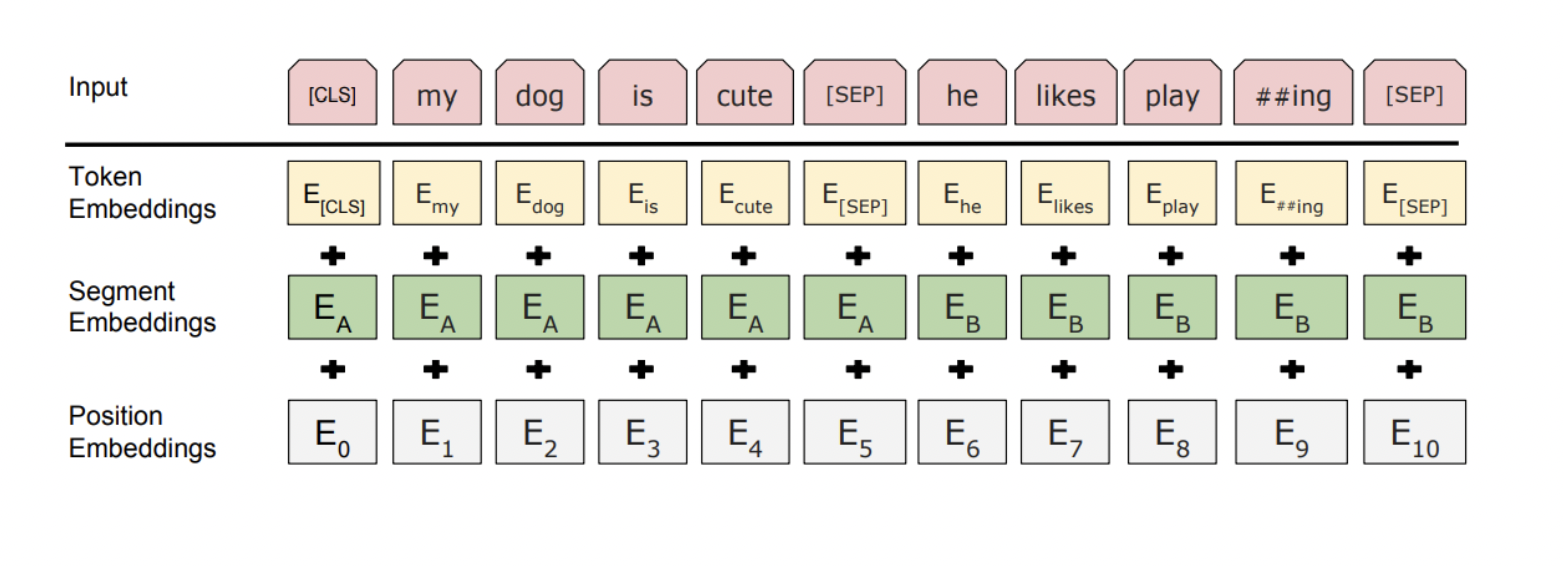
Bert의 특징 중 하나는, 입력 단어 Tokenizing에서 Sub-word Tokenizing 방식을 택해서 Embedding하는 것이다.
2. Input Representation
– WordPiece embeddings (30,000 WordPiece) – Learned positional embedding
– [CLS] – Classification embedding
– Packed sentence embedding [SEP]
– Segment Embedding
- 문장 두 개를 입력값으로 받기 때문에 아래 그림에서 두 번째 문장 첫 번째 단어는 Position 임베딩 상 6번째이지만 앞의 문장과 구별된 어떠한 임베딩이 필요하다고 볼 수 있다. 따라서 기존의 Positional Embedding에 Segment Embedding 벡터를 추가해서 최적화를 진행하는 방식을 Segment Embedding이라고 부른다.
3. Pre-training Tasks
– Masked LM
– Next Sentence Prediction
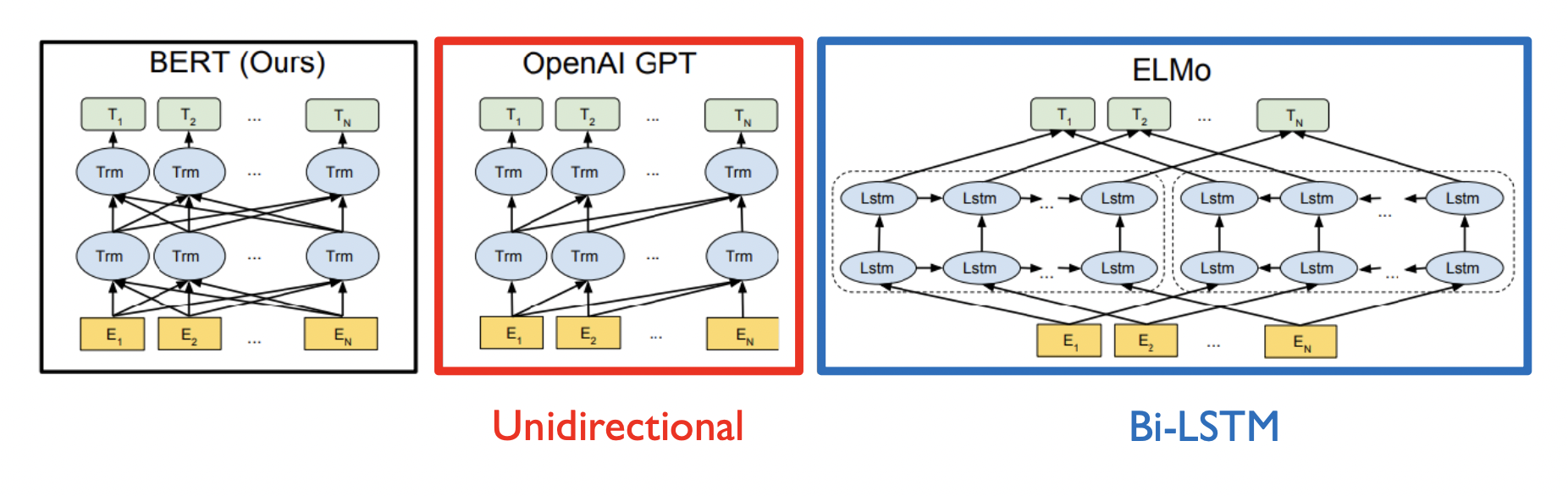
위의 그림처럼 GPT의 경우 한 방향(Unidirectional)의 데이터만 보게 되는데, 현재 시점보다 이후에 일어난 단어 정보는 보지 않는 Masked Self Attention을 사용하기 때문이다. 따라서 우리는 GPT가 Transformer의 Decoder를 사용한다고 말한다.
반면에 BERT는 한 번에 모든 시퀀스 데이터를 모두 볼 수 있는 Bidirectional 방식이다. 따라서 우리는 이를 Transformer의 Encoder를 사용한다고 말할 수 있다.
BERT Fine-tuning
Masked LM, Next Sentence Prediction을 통해 사전학습된 BERT를 사용해서 우리가 원하는 Task에 Fine-tuning하는 방법에 대해 알아보자. 이를 전이 학습, Transfer Learning 이라고 부른다. 이는 일반화 가능한 지식이 최대한 유지될 수 있도록 한다고 볼 수 있다.
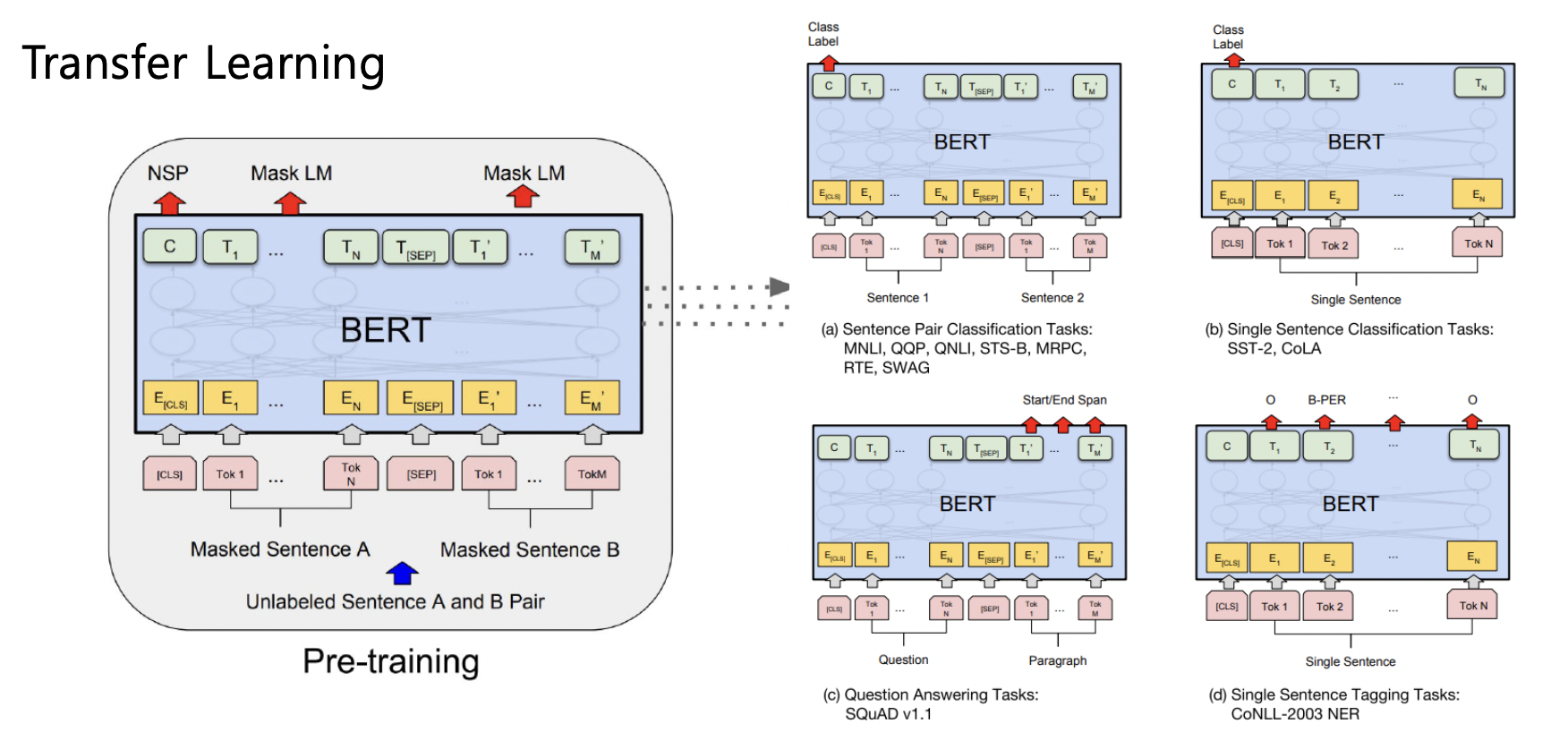
(a) Sentence Pair Classification Task
- 내포, 모순 관계를 예측하는 모델이다.
- 두 개의 문장을 [SEP] 토큰과 함께 한 문장으로 표현한다.
- CLS 토큰에 해당하는 Encoding Vector를 Output의 입력으로 주고 학습을 진행한다.
(b) Single Sentence Classification Task
- 입력으로 한 번에 하나의 문장
- 위와 동일
(c) Question Answering Task
- Context 데이터와 질문에 대한 적절한 대답을 학습하는 모델이다.
- 후술
(d) Single Sentence Tagging Tasks
- 단어의 품사 태깅에 대해서 예측하는 모델이다.
- Encoding Vector를 모두 Output의 입력으로 주고 각 단어의 Classification 진행
Comparison of BERT and GPT-1
- Training-data size
- GPT is trained on BookCorpus(800M words)
- BERT is trained on the BookCorpus and Wikipedia (2,500M words) - Training special tokens during training
- BERT learns [SEP],[CLS], and sentence A/B embedding(Segment Embedding) during pre-training - Batch size(the larger batch size the more stable)
- BERT – 128,000 words
- GPT – 32,000 words
- Task-specific fine-tuning
- GPT uses the same learning rate of 5e-5 for all fine-tuning experiments
- BERT chooses a task-specific fine-tuning learning rate.
Machine Reading Comprehension, Question Answering
주어진 지문을 기계 독해를 통해 정보를 이해하고 이에 대한 질문에 적절한 대답을 도출하는 문제이다. 대표적인 데이터셋은 SQuAD 데이터이고 학습하는 과정은 다음과 같다.
전체 단어의 Encoding vector에 대한 FC를 통해 각 단어에 대한 Scalar 값을 도출하고, Softmax를 취해서 나온 값에 대해 주어진 지문에서 정답에 해당하는 문구가 시작하는 단어 인덱스를 예측하게 학습하게 된다. 또한 끝나는 단어 인덱스를 예측하는 FC를 하나 더 만들어서 학습하게 된다.
SQuAD
SQuAD 데이터셋에서는 대답을 할 수 없는 질문도 존재한다. 따라서 Bert의 제일 앞에 추가된 CLS 토큰을 통해 지문에 대한 질문의 대답이 존재하는지 존재하지 않는지를 먼저 예측하고, 대답이 존재한다면 위의 과정을 따라가게 된다.
SWAG
이 Task는 어떤 문장의 다음 문장으로 적절한 문장을 여러 선택지 중 고르는 문제이다. 기본적으로 CLS 토큰을 사용해서 학습을 진행하지만, 주어진 선택지를 각각 주어진 문장과 이어붙여 CLS토큰의 Encoding Vector가 FC를 거치고 난 값인 Scalar 값을 통해 전체 선택지에 대해 Softmax를 취한 후 정답을 예측하게 된다.
GPT2
GPT1과 그 구조나 원리가 동일하지만 파라미터(레이어 수)나 데이터 수를 증가시켰다.
데이터셋의 퀄리티가 높다.
생성 Task의 zero shot 세팅
GPT2 - Motivation
decaNLP, Multitask learning as QA - 모든 NLP Task를 자연어 생성의 관점에서 해결할 수 있다.
GPT2 - Dataset
Wiki data 뿐만 아니라 Reddit data도 포함하였는데, 외부 링크를 대답으로 내놓았을 때 3개 이상의 좋아요를 받은 그 글을 고품질의 텍스트 데이터일 것이다라고 가정하여 데이터에 포함했다. 또한, BPE를 사용해서 단어사전을 구축했다.
GPT2 - Modification (Comparing to GPT1)
- Layer normalization was moved to the input of each sub-block, similar to a preactivation residual network
- Additional layer normalization was added after the final self-attention block.
- Scaled the weights of residual layer at initialization by a factor of where is the number of residual layer
Zero shot learning
- Question Answering
BERT의 Fint-tuning된 모델보다 훨씬 못 미치는 결과지만 가능성을 보였다. - Summarization
글 마지막에 TL;DR(Too Long, Didn't Read)라는 단어를 주고 이 단어가 들어오면 요약 태스크를 진행할 수 있도록 했다. - Translation
글 마지막에 "In French" 등의 단어를 추가해서 번역하는 모델을 만들었다.
GPT2 Tokenizer Code
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
# 1.
output = tokenizer(sentence)
print(output)
# {'input_ids': [40, 765, 284, 467, 1363, 13], 'attention_mask': [1, 1, 1, 1, 1, 1]}
# 2.
tokenized = tokenizer.tokenize(sentence)
print(tokenized)
# ['I', 'Ġwant', 'Ġto', 'Ġgo', 'Ġhome', '.']
# 3. _convert_token_to_id
token_ids = [tokenizer._convert_token_to_id(token) for token in tokenized]
print(token_ids)
# [40, 765, 284, 467, 1363, 13]
# 4. convert_tokens_to_ids
token_ids = tokenizer.convert_tokens_to_ids(tokenized)
print(token_ids)
# 5. encode
token_ids = tokenizer.encode(sentence)
print(token_ids)GPT 3
GPT2와 비교할 수 없을 정도로 많은 데이터와 많은 Block을 쌓아서 만든 모델이다.
few-shot
번역을 위한 여러개의 예시를 텍스트의 일부로써 제시했을 때 좋은 성능을 보였다. 즉, 별도의 Fine-tuning과정없이 inference 과정에서 패턴을 빠르게 파악한 후 예측하는 놀라운 성능을 보인 것이다.
ALBERT(A Lite BERT)
모델이 너무 비대해진 문제를 줄이고 학습 성능이나 시간 면에서 개선시킬 수 있도록 변형시킨 모델이다.
Factorized Embedding Parameterization
Self attention block의 입력과 출력에서 그 차원을 유지해야한다는 특징에서 단어 Embedding이 가지고 있는 정보는 문맥의 어떤 정보가 담긴 벡터도 아니기 때문에, 상대적으로 적은 정보를 갖고 있고 따라서 word embedding vector의 dimension을 줄여서 계산량 등에서 이득을 보려는 방법이다. 실제 학습 시에는 선형 변환을 거쳐서 Dimension을 맞춰준다.
Cross-layer Parameter Sharing
학습 과정을 생각해보자. 우리에게 중요한 건 4개의 선형 변환 행렬들이다. 따라서, 각 블록마다 행렬들은 연결되지 않는다. 그러나 ALBERT는 그러한 파라미터를 Share하는 모델을 연구했다.
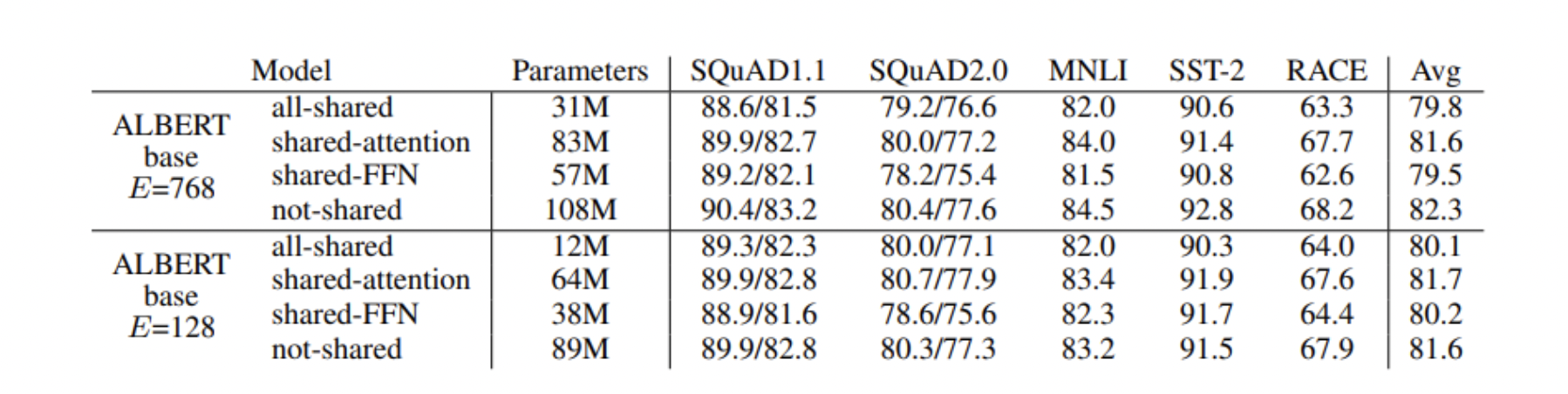
Sentence Order Prediction
BERT의 Task 중 두 개의 문장의 SEP 토큰으로 Concat해서 하나의 시퀀스로 만들어준 후 연속되는 문장인지 아닌지를 판단하는 Next Sentence Prediction Task가 있다. 그러나 이 Task를 빼고 Masked 된 단어 예측 Task로도 충분히 좋은 성능을 보이는 등 Next Sentence Prediction의 실효성이 떨어지는 모습을 보였다.
사실 생각해보면 BERT가 학습할 때, 같은 문서 내 인접한 문장을 놓았을 때 겹치는 단어가 많을 가능성이 높아 단순히 겹치는 단어를 기준으로 두 문장의 연결성을 판단할 수도 있고, 서로 다른 문서에서 임의의 두 문장을 뽑아 연결했을 때는 애초에 겹치는 단어가 매우 적은 상이한 문장들로만 구성되어 두 문장의 다름 자체만을 학습하게 될 수도 있다.
Albert에서는 이 문제를 개선하기 위해서 연속된(consecutive) Sentence 두 개를 가져와서, 두 문장의 순서만 정방향인지, 역방향인지를 이진 분류하는 Task로 변경했다. 이를 Sentence Order Prediction이라 부른다.
GLUE Results는 다음과 같다.
ELECTRA
: Efficiently Learning an Encoder that Classifies Token Replacements Accurately
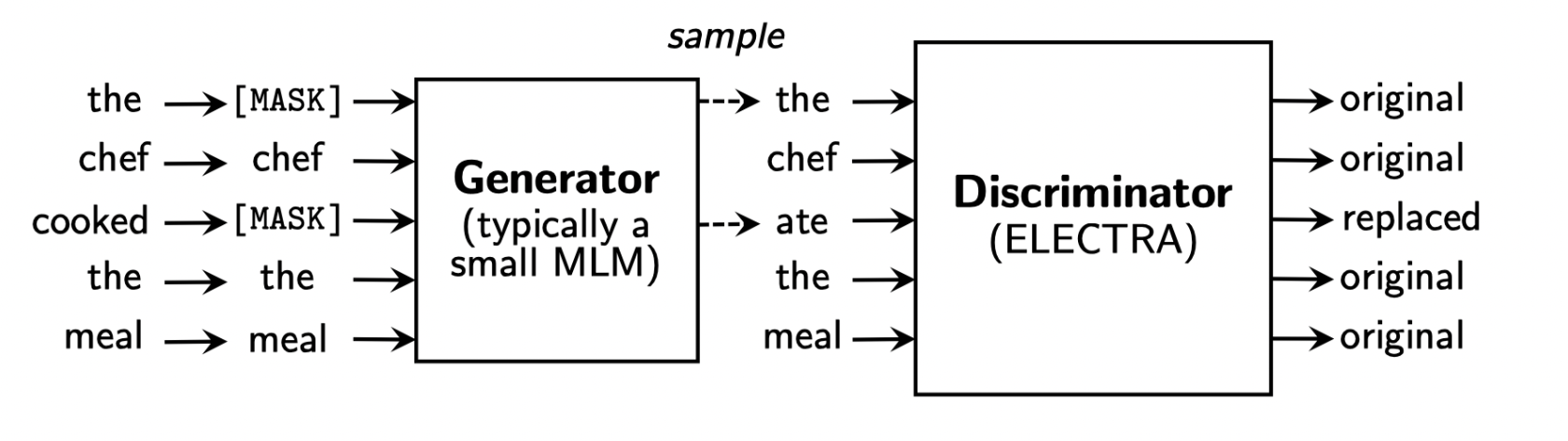
MLM : Masked Language Model
GAN에서 착안한 두 개의 적대적인 모델을 통해 학습을 하는 형식이다. MLM에는 BERT가, ELECTRA에는 Self-Attention Block을 쌓는 형식으로 진행된다. 이 때 Pretrained 되는 부분은 Generator에 해당하는 MLM이 아닌 Discriminator에 해당하는 부분이다.
Light-Weight Models(경량화)
비대해진 모델을 경량화시키는 여러 방법들이 제시되었다.
DistillBERT
Teacher, Student 모델이 존재한다. Student 모델은 Teacher 모델이 주어진 문장에서 MLM을 수행할 때 Softmax를 취하고 나온 최종 Output을 Ground Truth로 받으면서 Teacher 모델을 모사하는 형태로 학습을 진행한다.
TinyBERT
Knowledge-distillation을 사용했으며, Target Distribution을 모사해서 이를 Ground Truth로 받는다. 임베딩 레이어, QKV 가중 행렬, Parameter, Hidden State 중간 결과물까지 담아낼 수 있도록 학습을 진행한다. Hidden State의 경우 FC를 거쳐서 서로 다른 Hidden Dimension 값을 맞춰주는 방식을 가진다.
Fusing Knowledge Graph into Language Model
BERT는 주어진 문장의 의미나 문맥을 잘 이해했지만 외부 지식에 대해서는 좋은 성능을 가지진 못한다. 주어진 문장이 담고 있는 정보 뿐만 아니라 '상식'이라고 하는 외부 지식들이 Knowledge Graph로 표현된다.
ERNIE
KagNET
Further Reading
BERT의 Masked Language Model의 단점은 무엇이 있을까? 사람이 실제로 언어를 배우는 방식과의 차이를 생각해보며 떠올려보자
참고: XLNet: Generalized Auto-regressive Pre-training for Language Understanding
