한국어 언어 모델 학습 및 다중 과제 튜닝
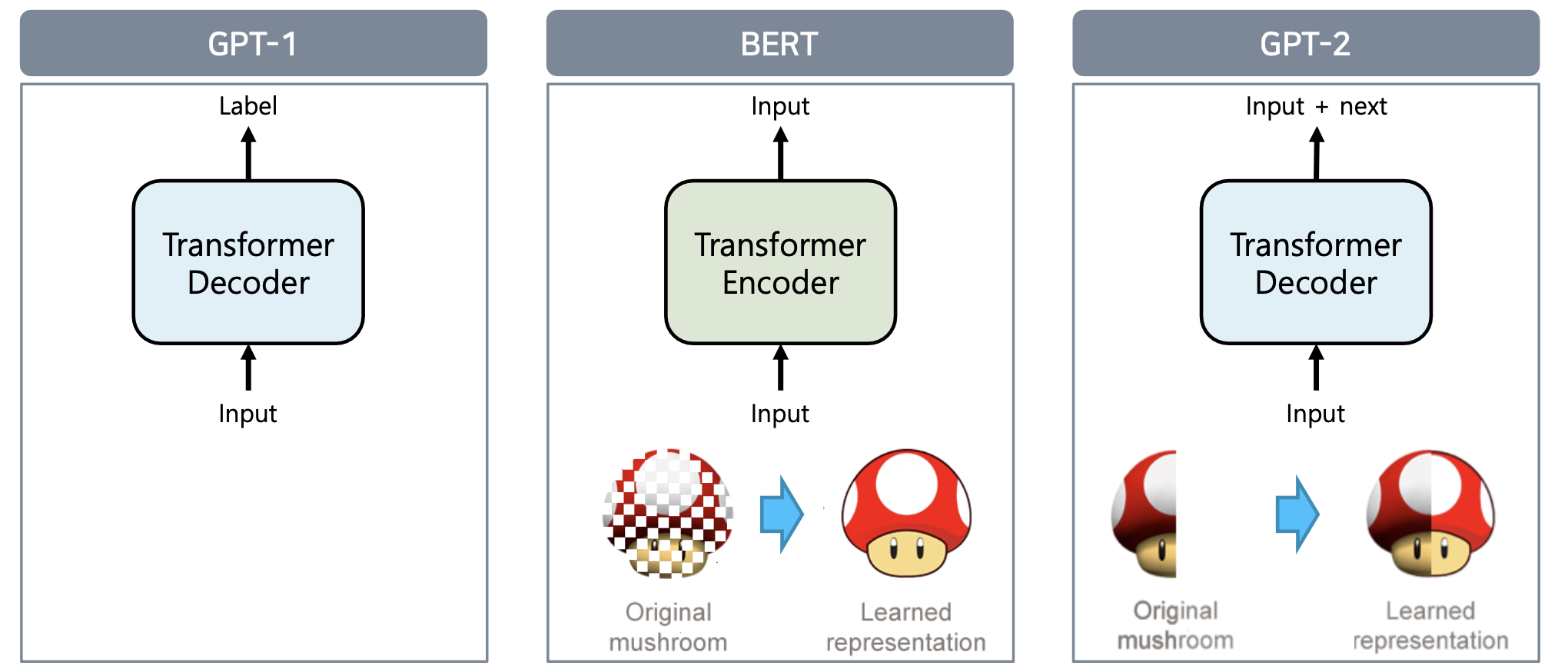
BERT 모델 소개
학습 코퍼스 데이터
• BooksCorpus (800M words)
• English Wikipedia (2,500M words without lists, tables and headers)
• 30,000 token vocabulary
데이터의 tokenizing
• WordPiece tokenizing, 빈도수 기반
• He likes playing à He likes play ##ing
• 입력 문장을 tokenizing하고, 그 token들로 ‘token sequence’를 만들어 학습에 사용
• 2개의 token sequence가 학습에 사용
그 다음, NSC, Masked pre training을 실시한다.
BERT 모델 학습
BERT 학습의 단계
1. Tokenizer 만들기
2. 데이터셋 확보
3. Next sentence prediction (NSP)
4. Masking
이미 있는거 쓰지, 왜 새로 학습해야해요?
"도메인 특화 task의 경우, 도메인 특화 된 학습 데이터만 사용하는 것이 성능이 더 좋다"
학습을 위한 데이터 만들기
- dataset의 형태로 만들어야 한다.
- token embedding, segment Encoding, Position Embedding, Class token
- dataloader 형태로 모델에 입력을 준다.
BERT [MASK] 공격
인공지능을 다루면서 데이터의 개인정보 문제는 항상 중요하다. 특히 NLP Task에는 다양한 경우의 개인정보가 들어갈 수 있다. 아래 예제를 보면 알 수 있다.
버락 오바마는 [MASK]에서 태어났다.
위의 문장을 BERT를 통해 fill-mask task를 수행하는 pipeline을 실행시키면 오바마의 출생지인 하와이를 잘 예측한다. 위와 같이 특정 인물들의 개인정보가 유출되는 문제는 심각한 결과를 초래할 수 있다.
BERT Pretraining
Configuration 설정은 기본적으로 영어로 세팅되어있다.
가장 주요한 차이는 Vocab size로, 약 20000정도가 적당하다.
pipeline 사용해서 내 모델을 불러올 때 device=0 을 추가해줘서 gpu를 맞춰주자.
