
현재 진행 중인 ReSeller Project에 조회 성능 개선을 위하여 캐싱을 적용하였다.
| In-Memory DBMS vs DISK DBMS |
|---|
 |
| 이미지 출처 |
기존 조회 방법은 요청이 들어올 때마다 외부 Disk 기반 DB 서버에 조회 요청을 보내고 응답을 받아야 했다.
그러나 캐시를 이용한다면 상대적으로 더 빠르고 서버에 부담 없이 조회가 가능하다.
속도가 빠른 인 메모리에 조회한 데이터를 임시적으로 저장하고, 요청 시 캐시에서 값을 조회하기 때문이다.
캐싱을 적용할 대상
모든 조회 로직에 캐싱을 적용하는 것은 바람직하지 않다. 해당 조회에 캐싱을 적용하기 전에 적합한 대상인지 고민해 봐야 한다. 프로젝트를 진행하며 아래와 같은 기준으로 대상을 선별했다.
✅ 요청마다 동일한 데이터를 반환하는 조회에만 사용
예를 들어 내 정보 조회와 같이 요청한 사용자마다 다른 값을 반환하는 조회를 캐싱 할 경우,
캐싱 된 회원 정보를 다른 회원까지 조회할 수 있게 되므로 적절한 캐싱 대상으로 볼 수 없다.
✅ 업데이트가 자주 발생하지 않는 데이터에 사용
잦은 업데이트가 발생하는 데이터를 캐싱 한다면 업데이트가 발생할 때마다 DB의 데이터와 캐시 데이터의 정합성을 맞추는 작업을 실시해야 한다. 이 과정이 오히려 성능에 악영향을 줄 수 있다.
✅ 자주 조회되는 데이터에 사용
조회 요청이 거의 없는 데이터를 캐싱 한다면 메모리만 낭비하는 데이터가 될 수 있다.
ReSeller Project에서는 브랜드 전체 조회와 상품 상세 조회에 캐싱을 적용하기로 결정하였다. 자주 조회가 될 것으로 예상되며 업데이트가 자주 발생되지 않을 가능성이 높다고 판단했다.
Local Cache VS Global Cache
캐싱을 저장할 대상을 선택한 다음 또 고려해야 하는 사항이 있다. 바로 적절한 캐싱 전략을 선택하는 것이다.
캐싱 전략에는 Local Cache와 Global Cache가 있다.
Local Cache
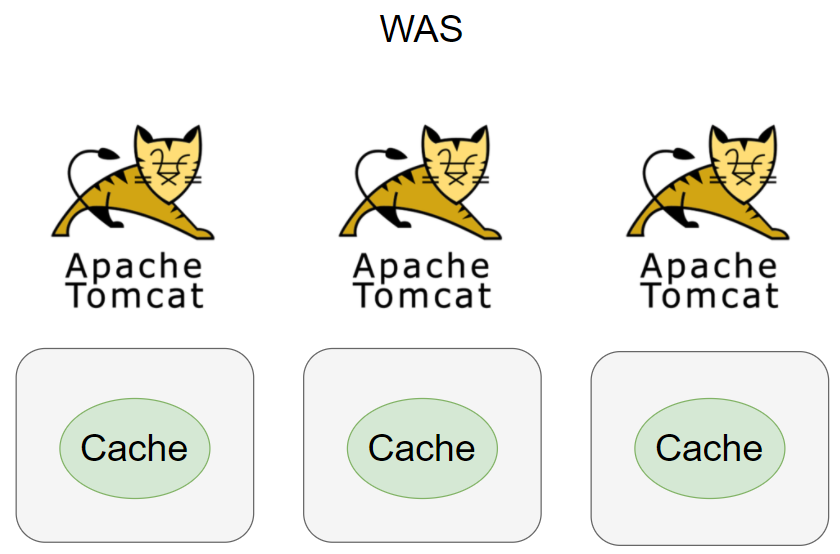
서버마다 각자 캐시를 저장하는 전략이며, 캐시 데이터 조회 시 외부 캐시 서버와 통신할 필요가 없어 빠른 조회가 가능하다.
하지만 서버마다 중복된 데이터를 저장하게 될 수 있으므로 서버의 개수에 비례하여 저장하는 데이터도 늘어나기 쉽다. 각 서버 캐시 간의 정합성을 맞춰야 하는 경우, 캐시 업데이트마다 다른 서버와 통신하는 과정이 필요하다.
Global Cache
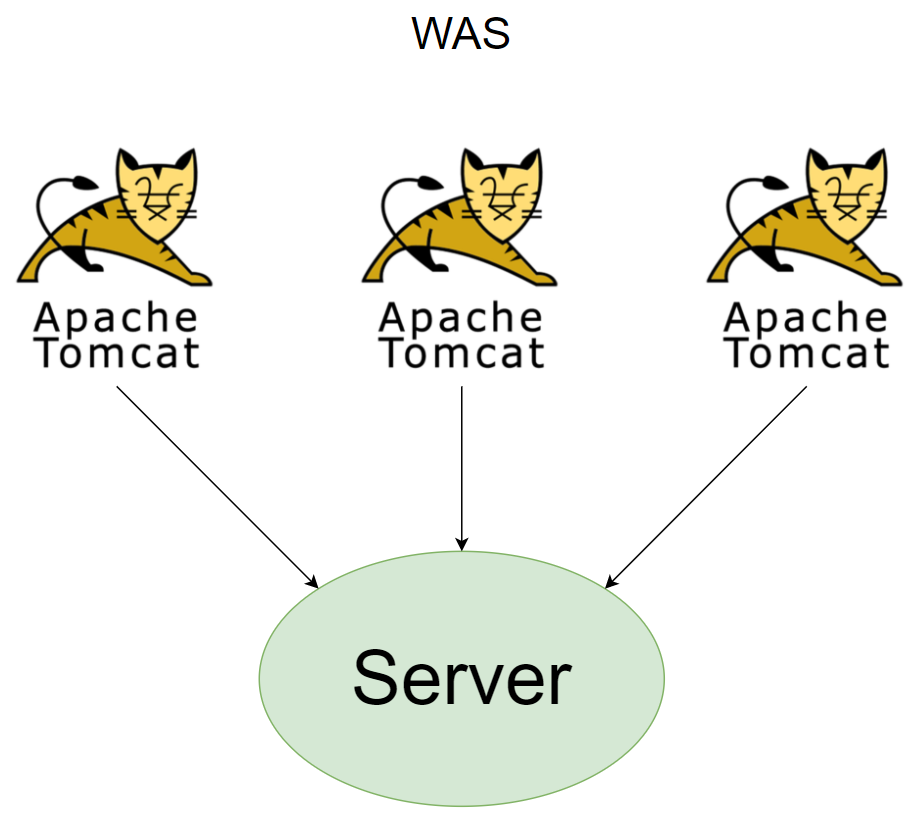
외부에 캐시 서버를 두고 각 서버들이 해당 캐싱 된 값들을 조회하는 전략이며, 동일한 캐시 서버를 참조하기 때문에 캐시 데이터를 서로 맞출 필요가 없다. 또 다른 장점으로 서버의 개수가 증가하더라도 저장되는 캐시 데이터양이 증가하지 않는다.
하지만 외부에서 데이터를 가져오기 위해 캐시 서버와 통신 과정이 필요하다.
본 프로젝트는 지속적인 트래픽 증가에 대처하기 위해 Scale-out 방식의 확장을 고려하여 진행 중이다. 따라서 서버의 개수가 증가할수록 Global Cache가 더 적합하다고 판단했다.
캐시 스토리지로는 Redis를 사용한다. 세션 저장소로 이미 사용 중이며, Spring Data Redis를 이용해 캐시 저장소로 사용하는데 문제가 없다고 판단했다.
Spring boot에서 Cache를 적용해 보자
Redis를 캐시 저장소로 설정
의존성 추가.
implementation 'org.springframework.boot:spring-boot-starter-data-redis'yml에 Redis의 host, port 설정
spring:
redis:
host:localhost
port:6379Configuration 클래스를 만들어서 @EnableCaching을 적용하고, 캐시 매니저를 등록해야 한다.
@EnableCaching은 @Cacheable, @CacheEvict 등의 캐시 어노테이션 활성화를 위한 어노테이션이다. 스프링에서는 AOP를 이용한 캐싱 기능을 추상화 시켜주므로 별도의 캐시 관련 로직 없이 적용할 수 있다.
스프링에서 지원하는 캐시 저장소는 JDK의 ConcurrentHashMap이며, 그 외 캐시 저장소를 사용하기 위해서는 CacheManager Bean으로 등록할 수 있다.
@RequiredArgsConstructor
@EnableCaching
@Configuration
public class CacheConfig {
private final CacheProperties cacheProperties;
@Value("$")
private String redisHost;
@Value("$")
private int redisPort;
@Bean(name = "redisCacheConnectionFactory")
public RedisConnectionFactory redisCacheConnectionFactory() {
LettuceConnectionFactory lettuceConnectionFactory = new LettuceConnectionFactory(redisHost, redisPort);
return lettuceConnectionFactory;
}
/*
* Jackson2는 Java8의 LocalDate의 타입을 알지 못해서 직렬화 X, 역 직렬화 시 에러 발생
* 따라서 ObjectMapper를 Serializer에 전달 -> 직렬화 및 역 직렬화 정상화
*/
private ObjectMapper objectMapper() {
ObjectMapper mapper = new ObjectMapper();
mapper.disable(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS);
mapper.registerModule(new JavaTimeModule());
return mapper;
}
private RedisCacheConfiguration redisCacheDefaultConfiguration() {
RedisCacheConfiguration redisCacheConfiguration = RedisCacheConfiguration
.defaultCacheConfig()
.serializeKeysWith(RedisSerializationContext.SerializationPair
.fromSerializer(new StringRedisSerializer()))
.serializeValuesWith(RedisSerializationContext.SerializationPair
.fromSerializer(new GenericJackson2JsonRedisSerializer(objectMapper())));
return redisCacheConfiguration;
}
/*
* properties에서 가져온 캐시명과 ttl 값으로 RedisCacheConfiguration을 만들고 Map에 넣어 반환
*/
private Map<String, RedisCacheConfiguration> redisCacheConfigurationMap() {
Map<String, RedisCacheConfiguration> cacheConfigurations = new HashMap<>();
for (Entry<String, Long> cacheNameAndTimeout : cacheProperties.getTtl().entrySet()) {
cacheConfigurations
.put(cacheNameAndTimeout.getKey(), redisCacheDefaultConfiguration().entryTtl(
Duration.ofSeconds(cacheNameAndTimeout.getValue())));
}
return cacheConfigurations;
}
@Bean
public CacheManager redisCacheManager(@Qualifier("redisCacheConnectionFactory") RedisConnectionFactory redisConnectionFactory) {
RedisCacheManager redisCacheManager = RedisCacheManager.RedisCacheManagerBuilder
.fromConnectionFactory(redisConnectionFactory)
.cacheDefaults(redisCacheDefaultConfiguration())
.withInitialCacheConfigurations(redisCacheConfigurationMap()).build();
return redisCacheManager;
}
}yml 설정값으로 ConfigurationMap을 만들고 CacheManager에 적용하여 하나의 CacheManager가 key별로 동적으로 timeout을 부여하는 방법으로 CacheManager가 불필요하게 증가하는 단점을 개선했다.
캐시 어노테이션 적용
스프링에서는 캐시 관련 로직을 추상화하여 비즈니스 로직에 영향 없이 어노테이션만 적용하여 쉽게 적용할 수 있다. 해당 과정은 모든 스프링 빈에서 public 메서드에 캐싱 어노테이션이 있는지 검사하는 빈 후처리기를 트리거 한다. 그 후 동적 프록시를 이용하여 어노테이션이 붙은 메서드의 호출을 가로채고 캐싱 관련 동작을 수행한다.
@Cacheable 어노테이션을 캐싱 대상에 적용하면 해당 조회가 일어날 때 캐시 저장소에 해당 key로 저장된 데이터가 존재하는지 확인한다. 존재 시, 해당 값을 바로 반환하며 존재하지 않는다면 원본 데이터가 있는 스토리지에 데이터를 요청하고 캐시 저장소에 데이터를 저장한 후 반환한다.
저장된 캐시에 접근하기 위해서는 적절한 key 값이 필요하다. key 값을 지정하지 않을 경우 아래와 같은 알고리즘으로 구현된 KeyGenerator에 의해서 key 값을 만들어준다.
- 파라미터가 없을 경우,
SimpleKey.EMPTY - 파라미터가 하나일 경우, 인스턴스를 리턴한다.
- 파라미터가 하나 이상일 경우, 모든 파라미터를 포함한
SimpleKey를 리턴한다.
@Transactional(readOnly = true)
@Cacheable(value = "brands")
public List<BrandInfo> getBrandInfos() {
return brandRepository.findAll().stream()
.map(brand -> brand.toBrandInfo()).collect(Collectors.toList());
}@CacheEvict 어노테이션은 캐싱 한 값들을 제거하는 역할을 한다. 캐싱 된 데이터가 업데이트되었을 때 원본 저장소인 DB와 캐시 저장소의 데이터의 일관성을 맞추기 위하여 캐싱 되었던 값을 제거해야 한다. getBrandInfos()에서는 명시적으로 Key 값을 지정하지 않았기 때문에 Side effect를 방지하기 위해 allEntries(value에 해당하는 모든 캐시를 의미)의 값을 true로 설정했다.
@CacheEvict(value = "brands", allEntries = true)
@Transactional
public void updateBrand(Long id, SaveRequest updatedBrand, @Nullable MultipartFile brandImage) {
...
}캐싱 적용 후 동작 방식
캐싱 동작 방식
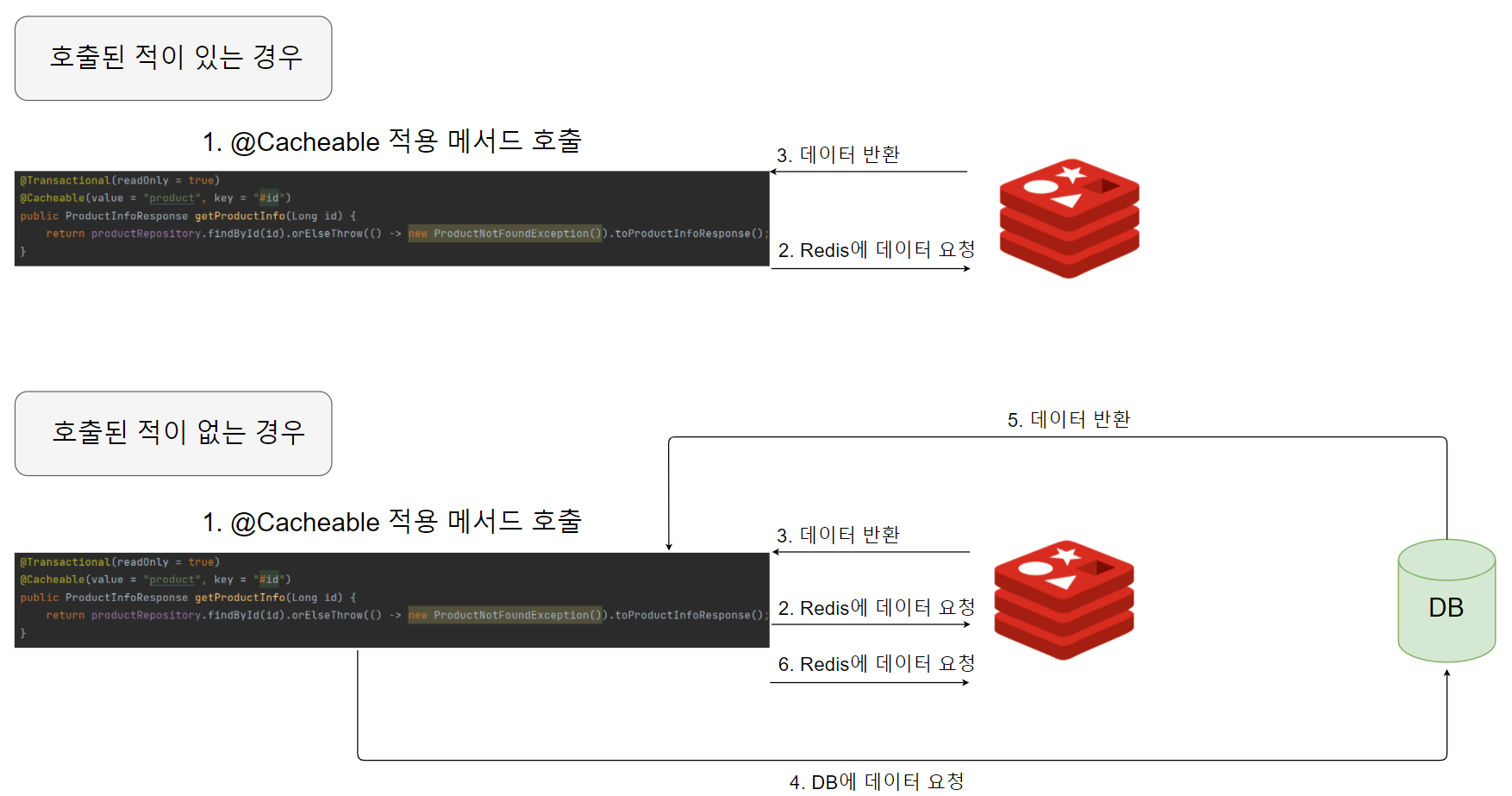
확인
| 캐싱 적용 전 | 캐싱 적용 후 |
|---|---|
 |  |
상품을 생성하고 최초로 조회했을 경우 아래와 같이 방금 조회한 데이터가 레디스에 캐싱 된다.
해당 상품을 업데이트하게 되면 저장된 캐시 데이터가 제거되므로 조회되지 않는다.

