
기본 개념
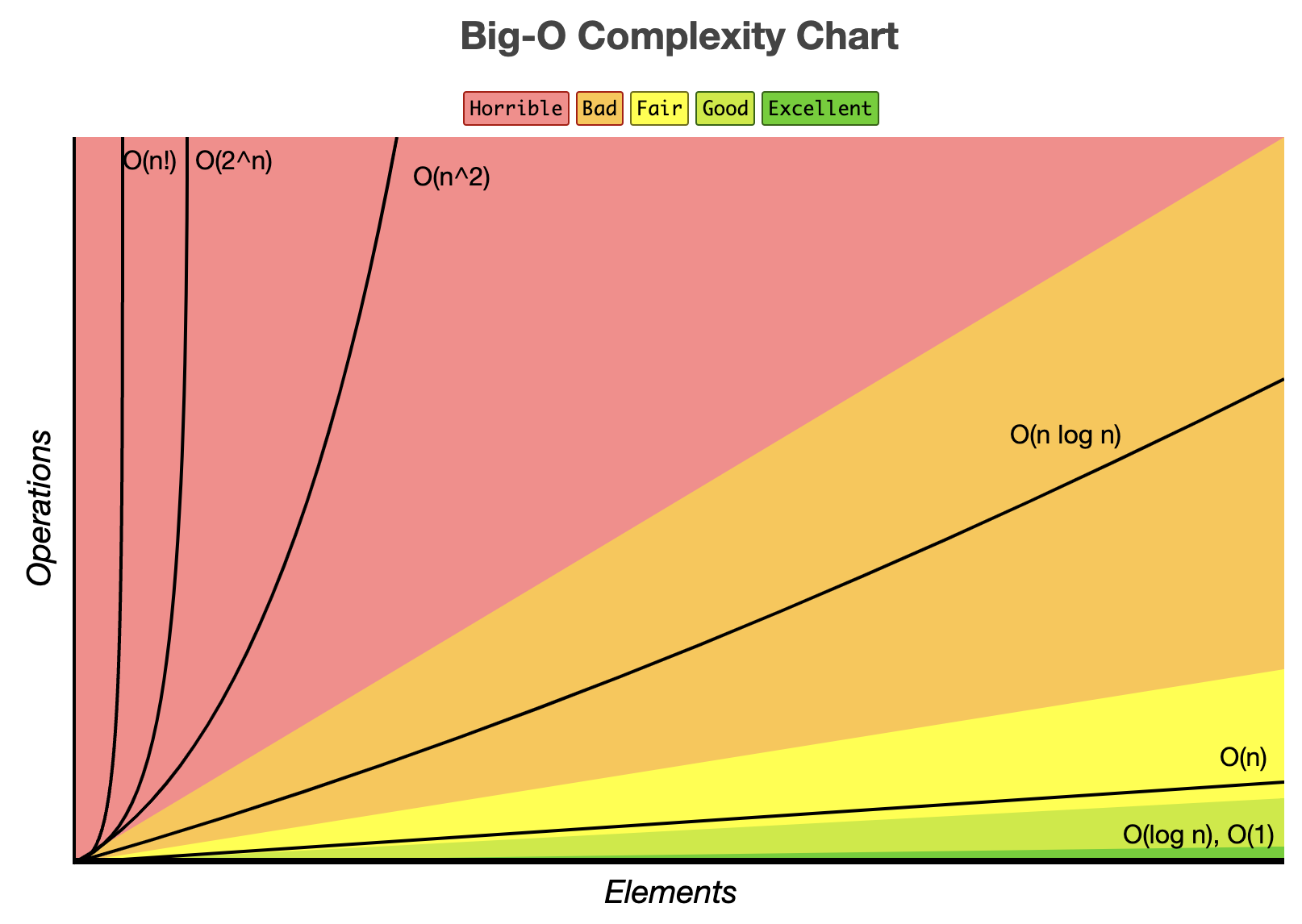
- 시간복잡도 대표 표현식 위일수록 빠르다.
빠른 순서 ↑
상수 시간
로그시간
직선형 시간
2차 시간
지수 시간
느린 순서 ↓
List 자료구조
1. ArrayList

-
ArrayList는 동적 배열을 기반, 연속적인 데이터의 리스트String[] array = new String[10] ; ArrayList<String> list = new ArrayList<> (*initialCapacity:* 10); -
데이터는 연속적으로 리스트에 들어있어야 하며, 중간에 빈공간이 있어선 안된다. → 중간에 삽입/삭제 할때 요소들의 위치를 자동 이동시켜 삽입/삭제 동작이 느리다.
-
배열을 이용하기에 요소의 인덱스를 통해 빠르게 직접 접근 가능
-
크기가 고정되어 있는 배열과 달리 데이터의 적재량에 따라 가변적으로 공간을 늘리거나 줄인다.
-
객체로 데이터를 다루기 때문에 적은양의 데이터만 쓸 경우 배열보다 사용하는 메모리공간이 더 많다.
-
삽입
- 처음: / 중간: / 마지막: (단, 배열이 꽉 차서 크기를 늘려야 하는 경우 )
Object[]배열을 이용해 요소를 저장한다.- 지정된 위치에 요소를 넣을때, 기존의 요소들을 한칸씩 뒤로 미루면서 빈공간을 만들어주어 비효율적
- 배열 공간이 꽉 찰때마다 배열을 copy하는 방식을 사용해 배열을 늘리는데, 배열 복사 동작 자체의 성능이 좋지 않아 오버헤드 발생
ArrayList<Integer> number = new ArrayList<>(); number.add(1); number.add(3); number.add(5); // 배열 복사 // ArrayList는 내부적으로 Object[] 배열로 저장하기 때문에 형변환이 필요함 ArrayList<Integer> cloneNumber = (ArrayList<Integer>) number.clone(); System.out.println("ArrayList: " + number); // [1, 3, 5] System.out.println("Cloned ArrayList: " + cloneNumber); // [1, 3, 5]
-
삭제
- 처음: / 중간: / 마지막:
- 삽입과 마찬가지로, 중간에 위치한 요소를 제거할 경우, 빈공간을 채우려 앞으로 이동하게 되는 비용 발생
-
조회:
-
검색:
2. LinkedList
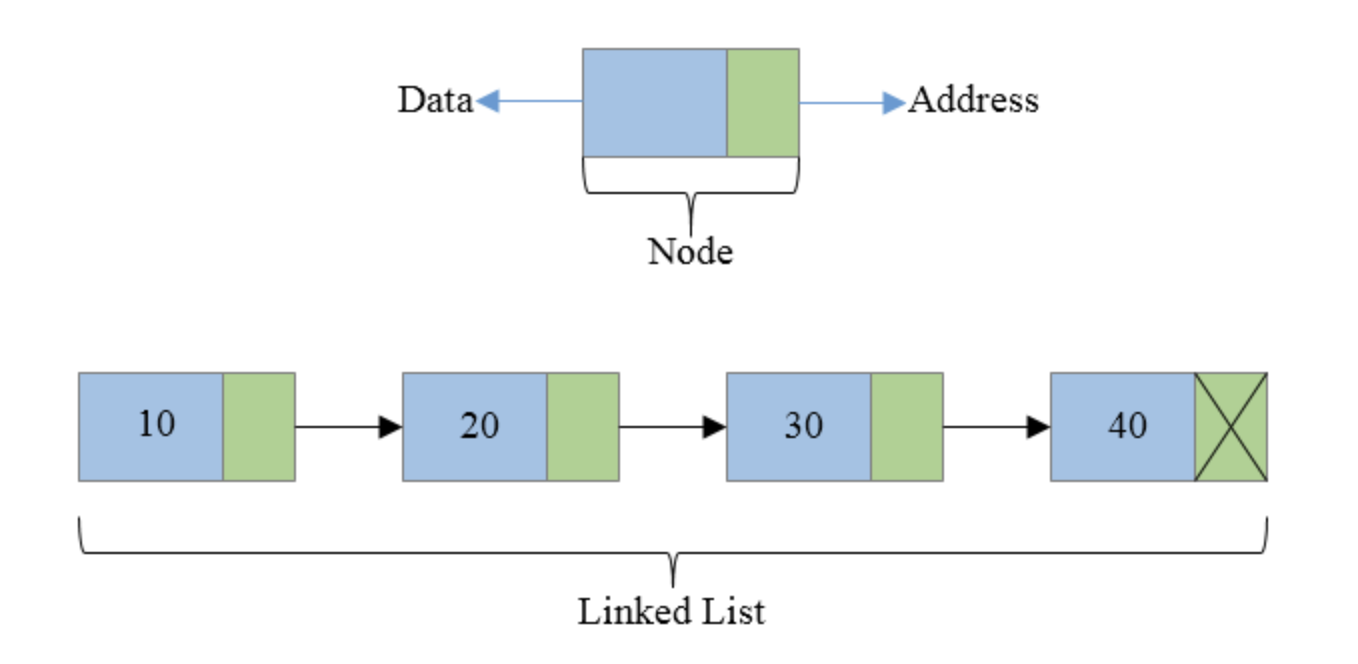
-
LinkedList는 이중 연결 리스트를 기반으로 한, 연속적인 데이터 리스트LinkedList<String> list = new LinkedList<>(); list.add("A"); list.add("B"); list.add("C"); -
배열이 아닌, 노드를 연결해 리스트처럼 만든 컬렉션
-
각 노드는 데이터와 이전 및 다음 노드에 대한 참조를 포함한다.
-
이중 연결 리스트를 기반으로 하여, 양방향 포인터 구조로 이루어져 있다.
-
중간 삽입/삭제 시 요소의 위치를 이동시키지 않아도 되므로 데이터의 중간 삽입, 삭제가 빈번할 경우 빠른 성능 보장한다.
-
임의의 요소에 대한 접근 성능이 좋지 않다.
→ 인덱스를 통한 빠른 직접 접근이 불가능하여, 특정 요소에 접근하기 위해 처음부터 순차적으로 탐색해야 합니다. -
데이터 양에 따라 가변적으로 공간을 늘리거나 줄일 수 있다.
-
삽입
- 처음: O(1) / 중간: O(n) / 마지막: O(1)
- 처음이나 마지막에 삽입하는 경우, address 부분만 수정하면 되므로, O(1)로 빠르다.
- 중간에 삽입하는 경우, 삽입 위치를 찾기 위해 순차적으로 탐색해야 하므로 O(n)이 걸린다.
LinkedList<Integer> number = new LinkedList<>(); number.addFirst(1); number.addLast(3); number.add(1, 2); // 중간 삽입
-
삭제
- 처음: O(1) / 중간: O(n) / 마지막: O(1)
number.removeFirst(); // 처음 요소 삭제 number.removeLast(); // 마지막 요소 삭제 number.remove(0); // 중간 요소 삭제
- 처음: O(1) / 중간: O(n) / 마지막: O(1)
-
조회: O(n)
- 특정 인덱스에 있는 요소에 접근하기 위해 처음부터 해당 위치까지 순차적으로 탐색한다.
-
검색: O(n)
- 특정 요소를 검색하기 위해 처음부터 끝까지 해당 값을 찾을 때까지 순차적으로 탐색한다.
추가
ArrayList와 LinkedList는 데이터 삽입이 동일하게 O(1), 배열의 중간 삭제가 O(n)이 걸리는데, 그렇다면 실제 실행속도는 같을까?
→ ArrayList로 배열 맨뒤에 1억개의 1 삽입 후 , 배열 중간에 1000000번째 인덱스 100개 삭제
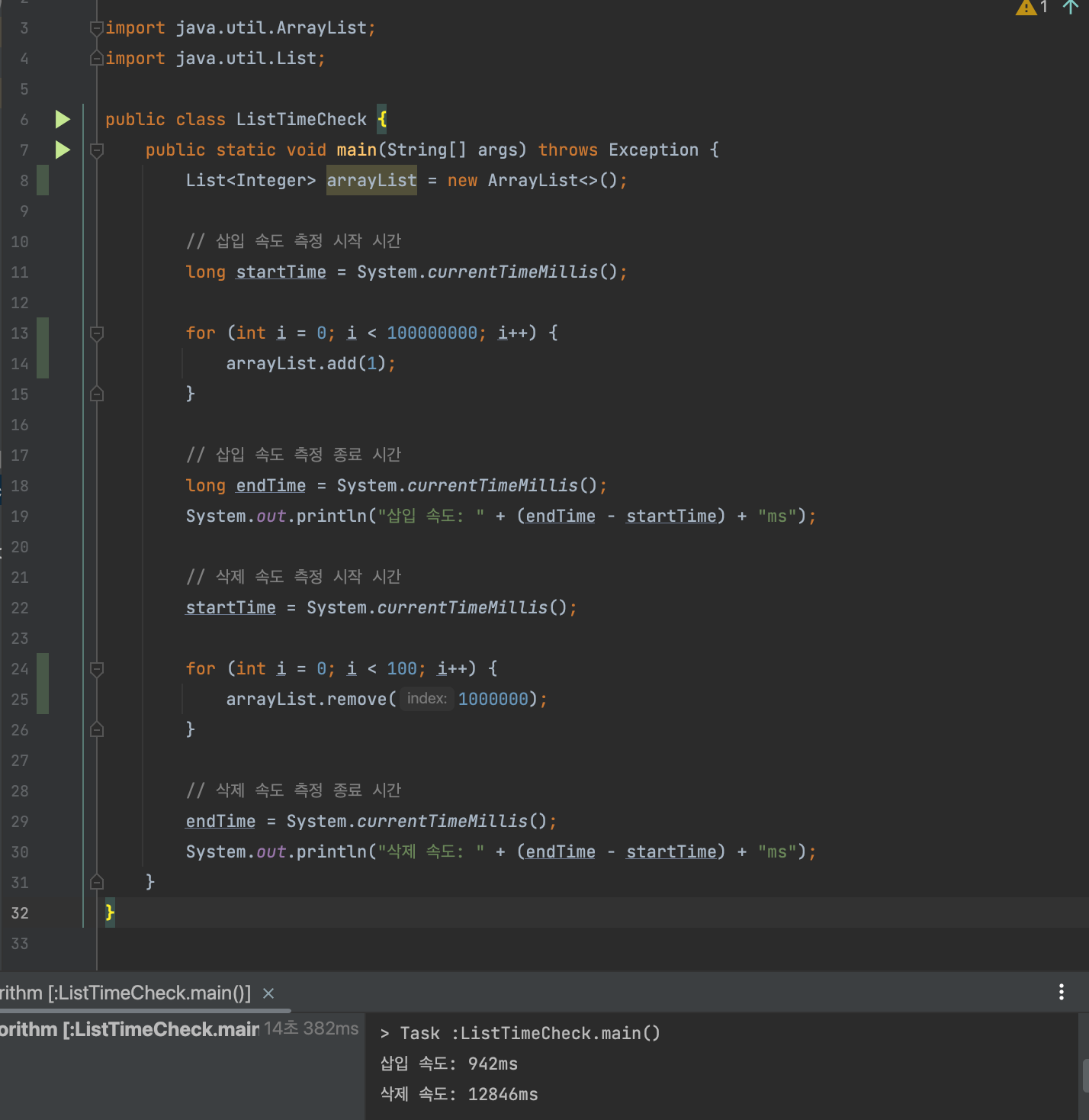
결과 : 삽입 속도: 942ms / 삭제 속도: 12846ms
→ LinkedList로 배열 맨뒤에 1억개의 1 삽입후, 배열 중간에 1000000번째 인덱스 100개 삭제
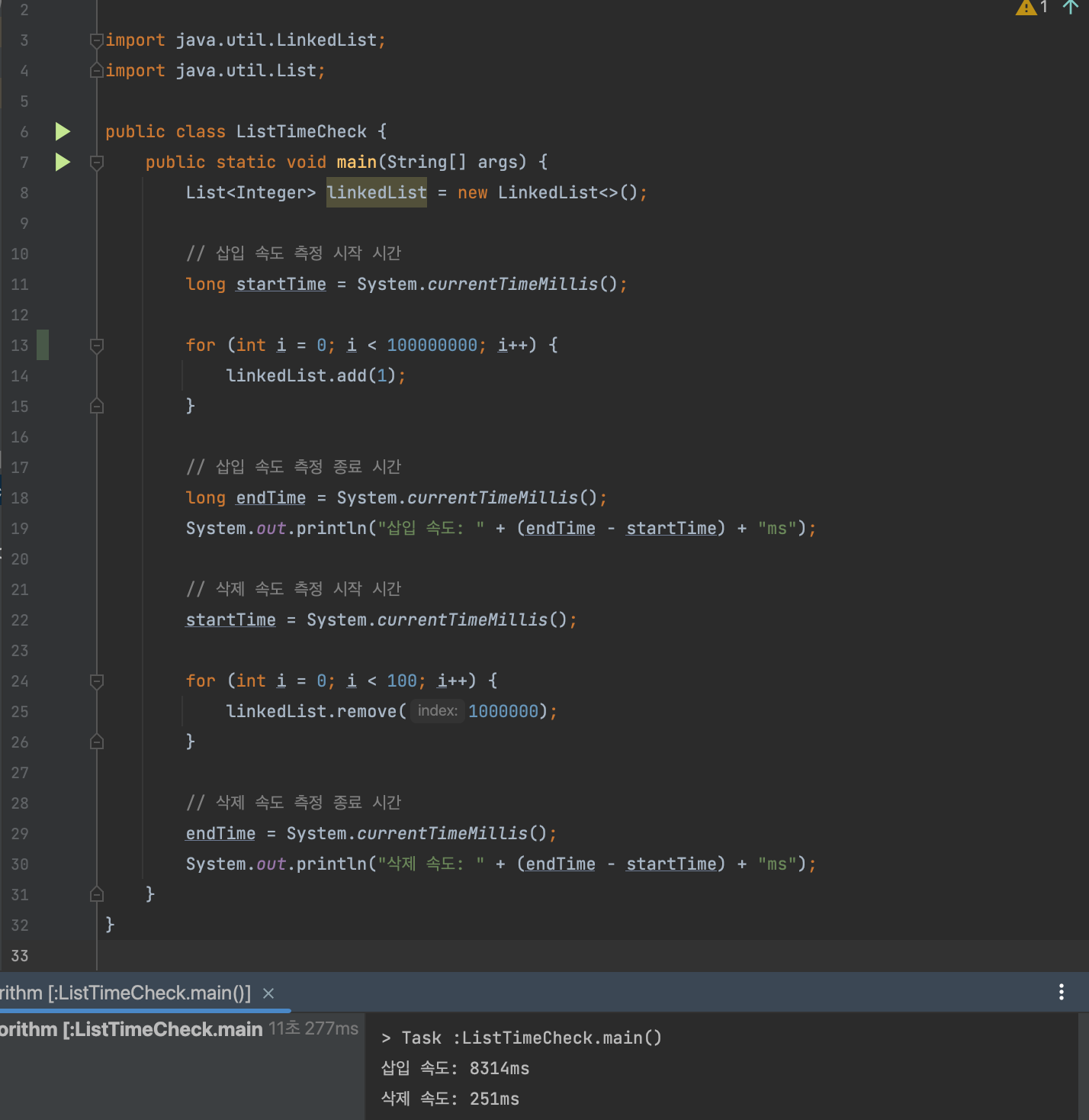
결과 : 삽입 속도: 8314ms / 삭제 속도: 251ms
삽입의 경우
- 942ms vs 8314ms
- 시간복잡도는 O(1)로 둘다 동일하지만 이렇게 눈에 띄게 속도 차이가 발생한다.
- ArrayList의 경우 추가를 할 때 단순히 배열의 크기를 조정하고 값을 쓰면 되므로 시간이 거의 소요되지 않는다.
- LinkedList의 경우 새로운 노드를 선언하고 객체를 생성하고 메모리를 할당해야고 연결하는 등의 비싼 작업이 수행되기 때문에 실제 수행시간에서 차이가 발생하게 된다.
- O(1)에서 생략된 상수항의 매우 크다
삭제의 경우
- 12846ms vs 251ms
- 시간복잡도는 O(n)으로 둘다 동일하다. 하지만, ArrayList 의 경우 중간에서 요소를 삭제할 때, 그 뒤의 모든 요소를 한 칸씩 앞으로 이동해야 한다.이 요소 이동 작업 때문에 삭제에 O(n) 시간이 소요된다.
- LinkedList 의 경우, 노드를 삭제할 때, 삭제할 노드를 찾기 위해 평균적으로 O(n) 시간이 소요되는데, 이는 비교적 비용이 적게드는 탐색에 소요되는 시간이고, 실제 삭제 작업 자체는 연결만 바꿔주면 되기에 O(1) 시간이 소요된다.
Map 자료구조
해시함수란?
- 임의 길이의 입력 값을 고정 길이의 암호화된 출력으로 변환해주는 함수
- 특징
- 어떤 입력 값에도 항상 고정된 길이의 해시값을 출력한다.
- 입력 값의 아주 일부만 변경되어도 전혀 다른 결과 값을 출력한다.
- 출력된 결괏값을 통해 입력값을 유추할 수 없다.
- 해시 충돌(Hash Collision)이란?
- 입력값이 다르더라도 같은 결과값이 나오는 경우, 해시 충돌이 적은 함수가 좋은 함수
- 해결방법 1 ) 개방 주소법 (open addressing) : 해시 테이블 크기는 고정하면서 저장할 위치를 찾는다
- 해결방법 2 ) 분리연결법 (separate chaining) : 해시 테이블의 크기를 유연하게 만든다. 버켓 내에 연결리스트(Linked List)를 할당하여, 버켓에 데이터를 삽입하다가해시 충돌이 발생하면 연결리스트로 데이터들을 연결하는 방
3. HashMap
HashMap은 HashTable 을 기반으로 한 키-값 쌍 저장소 (각 키는 고유하고, 값은 키와 연결된다)HashTable: (Key, Value)로 데이터를 저장하는 자바 초기 버전에 나온 레거시 클래스HashMap은 보조 해시 함수(Additional Hash Function)를 사용하기 때문에 보조 해시 함수를 사용하지 않는 HashTable에 비하여 해시 충돌(hash collision)이 덜 발생할 수 있어 상대으로 성능상 이점이 있다.
HashMap 보다는 느리지만 기본적으로 병렬 프로그래밍을 지원해 동기화가 제공된다.
- 데이터를 해시 함수에 따라 저장하기에 빠른 검색이 가능하다
- 데이터의 순서를 보장하지 않는다.
-
조회 / 삽입 / 삭제 / 검색: O(1)
-
키를 해시 함수를 통해 해시 코드로 변환후 해당 위치 저장, 삭제, 조회, 반환
-
next() : 반복자를 사용해 해시맵의 모든 항목 순회 : O(h/n)
- h = 해시맵의 내부 버킷의 수 , n은 해시맵의 크기
-
해시 충돌이 발생할 경우
- java 7 이전, separate chaining에서 linked list를 고정적으로 사용해 해결
최악의 경우 = 모든 항목이 하나의 버킷에 모이는 경우 → 최대 O(n) - java 8 부터 데이터 개수가 많아지면 트리를 사용하도록 변경 → 최악의 경우에도 O(log N) 하나의 해시 버킷에 8개의 키-값 쌍이 모이면 링크드 리스트를 트리로 변경하고, 해당 버킷에 있는 데이터를 삭제하여 개수가 6개에 이르면 다시 링크드 리스트로 변경한다
(7이 아니라 6인 이유, 1의 차이로 트리와 링크드 리스트로 변경하는 일이 반복되는게 오히려 성능저하)
- java 7 이전, separate chaining에서 linked list를 고정적으로 사용해 해결
예시 코드
HashMap<String, Integer> hashMap = new HashMap<>();
// 삽입
hashMap.put("apple", 10);
hashMap.put("banana", 20);
hashMap.put("orange", 15);
// 중복된 키는 새로운 값으로 대체됨
hashMap.put("apple", 30);
// 삭제
hashMap.remove("banana");
// 조회
for (String key : hashMap.keySet()) {
System.out.println(key + ": " + hashMap.get(key));
}
// 검색
boolean containsApple = hashMap.containsKey("apple");
System.out.println("Contains key 'apple': " + containsApple);위의 코드에서, HashMap은 키-값 쌍을 저장하는 데 사용되며, 키를 통해 값에 접근할 수 있다.
삽입, 삭제, 조회, 검색 모두 상수 시간(O(1))에 이뤄진다.
4. TreeMap
-
TreeMap은 이진 검색 트리를 기반으로 한 키-값 쌍 저장소로, 키를 정렬된 순서로 유지합니다. -
TreeMap은 SortedMap 인터페이스를 구현하고있어 Key값을 기준으로 오름차순 정렬
-
키와 값을 저장함과 동시에 정렬까지 하기에 일반 Map보다 추가, 삭제에 시간이 오래 걸린다.
-
정렬된 순서로 저장되기에 빠른 검색(범위 검색)이 가능하다
-
정렬되는 순서 : 숫자 → 대문자 → 소문자 → 한글
-
사용되는 자료구조 : Red-Black Tree
- 이진 탐색 트리가 데이터가 한쪽으로 치우쳐 들어올 경우 depth 가 커져, 매우 비효율적인 성능을 나타내는데, 이를 보완하기 위해 등장한 트리의 높이가 최소화된, 균형 이진 탐색 트리
- O(log N)의 시간복잡도 보장

- 삽입, 삭제, 조회, 검색 연산은 모두 Red-Black Tree의 특성에 따라 O(log N)의 시간복잡도를 갖는다.
- 트리의 높이에 비례하는 시간이 소요되므로, 트리가 균형적인 상태를 유지할수록 연산의 속도가 빨라진다.
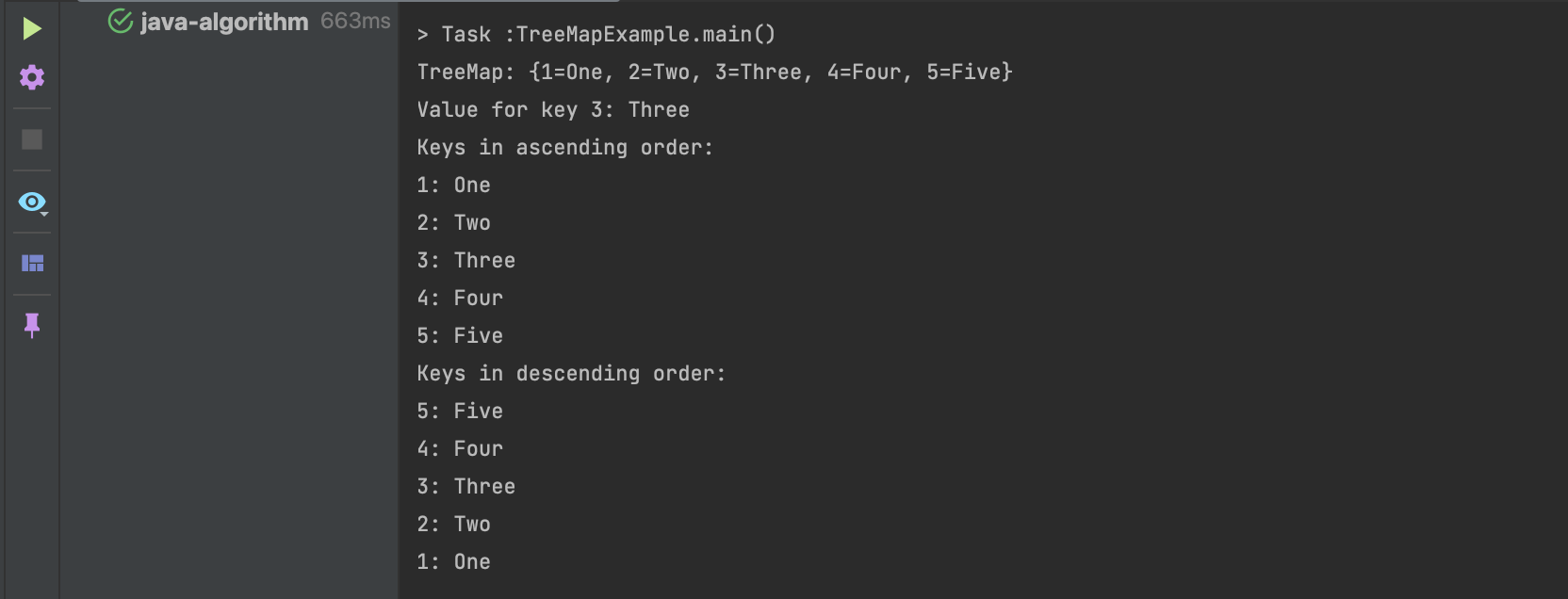
import java.util.*;
public class TreeMapExample {
public static void main(String[] args) {
// TreeMap 객체 생성
TreeMap<Integer, String> treeMap = new TreeMap<>();
// 키-값 쌍 추가
treeMap.put(3, "Three");
treeMap.put(1, "One");
treeMap.put(4, "Four");
treeMap.put(2, "Two");
treeMap.put(5, "Five");
// TreeMap 출력 (정렬된 순서로 출력됨)
System.out.println("TreeMap: " + treeMap);
// 조회
System.out.println("Value for key 3: " + treeMap.get(3));
// 키로 정렬된 순서대로 반복문을 통해 출력
System.out.println("Keys in ascending order:");
for (Map.Entry<Integer, String> entry : treeMap.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
// TreeMap을 역순으로 정렬된 순서대로 출력
NavigableMap<Integer, String> descendingMap = treeMap.descendingMap();
System.out.println("Keys in descending order:");
for (Map.Entry<Integer, String> entry : descendingMap.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
}
}출력
Set 자료구조
데이터의 중복을 허용하지 않고, 순서를 유지하지 않는 데이터 집합 리스트
순서 자체가 없어 인덱스로 객체를 검색해서 가져오는 get() 메서드도 존재하지 않는다.
중복 저장이 불가능하여 null값도 하나만 저장할 수 있다.
5. HashSet - 수정중
-
HashSet은 해시 테이블을 기반으로, 중복 요소를 허용하지 않는다. -
저장한 순서가 보장되지 않는다. (순서를 유지해야한다면 LinkedHashSet을 사용하기)
-
배열과 연결노드를 결합한 자료구조의 형태
-
가장 빠른 임의 검색 접근 속도를 가진다.
-
삽입 / 삭제 / 검색: O(1)
- 이상적인 경우(해시 함수 충돌이 적은 경우)에는 상수 시간(O(1))에 삽입이 이루어집니다.
-
조회: N/A (랜덤 접근이 불가능함)
-
next() : 해시 테이블의 버킷을 순회하면서 요소를 하나씩 반환 : O(h/n)
- HashSet 인스턴스의 크기(요소 수) 와 인스턴스의 용량(버킷 수)의 합계에 비례하는 시간이 필요
-
삽입 : add()
HashSet<String> animals = new HashSet<>() animals.add("tiger"); animals.add("lion"); animals.add("fox"); -
삭제 : remove()
animals.remove("lion"); -
검색 : contains()
boolean containsTiger = animals.contains("tiger"); System.out.println("Contains 'tiger': " + containsTiger);
6. TreeSet
-
TreeSet은 이진 검색 트리를 기반으로 하며, 정렬된 순서로 요소를 저장한다 -
데이터를 정렬하여 저장한다.
-
정렬, 검색, 범위 검색에 높은 성능을 뽐낸다.
-
삽입/ 삭제 / 조회 / 검색: O(log n)
HashSet과 TreeSet은 각각 해시 테이블과 이진 검색 트리를 기반으로 하기 때문에, 연산 복잡도가 각각 O(1)과 O(log n)입니다. 하지만 실제 실행 시간은 해당 자료구조의 내부 동작 및 구현 방식, 그리고 입력 데이터의 속성에 따라 달라질 수 있습니다.
import java.util.TreeSet;
public class TreeSetExample {
public static void main(String[] args) {
TreeSet<Integer> treeSet = new TreeSet<>();
// 삽입
treeSet.add(5);
treeSet.add(3);
treeSet.add(7);
treeSet.add(1);
// 삭제
treeSet.remove(3);
// 조회
for (int num : treeSet) {
System.out.println(num);
}
// 검색
boolean containsFive = treeSet.contains(5);
System.out.println("Contains 5: " + containsFive);
}
}
결론
자바의 컬렉션 프레임워크는 다양한 자료구조를 제공하고, 각 자료구조를 요구되는 상황에 적절하게 사용하는것이 중요하다.
- ArrayList
- 인덱스를 통한 빠른 접근이 필요한 경우
- 순차적인 추가/삭제 제일 빠르고, 요소의 추가/삭제에는 좋지 않음
- Linked List
- 빈번한 삽입과 삭제가 필요한 경우 적합
- 임의의 요소에 대한 접근성이 좋지 않음
- HashMap / HashSet
- 빠른 검색과 중복 요소 제거가 필요한 경우
- 검색에 최고 성능
- TreeMap / TreeSet
- 정렬된 데이터를 유지해야할 때
- 검색( 특히 범위 검색) 에 적합
참고
