Redis는 다양한 데이터 구조를 제공하지만, 그 중에서도 Sorted Set은 실시간 순위 시스템 구현에 있어 독보적인 성능을 자랑합니다. 해당 챕터를 읽으면서 Redis의 다양한 기능 중 Sorted Set에 대해 집중적으로 조사해보았습니다.
이 글에서는 Redis Sorted Set의 내부 동작 원리부터 실무에서의 활용 패턴, 그리고 대규모 서비스에서의 확장 전략까지 실전 경험을 바탕으로 공유하겠습니다.
(우와 이 글을 작성하고 얼마 안되어서 사이드 프로젝트에 Redis Sorted Set을 사용해보게 되었습니다. 이에 대해선 글 마지막에 추가하였습니다.)
레디스 Sorted Set
Redis Sorted Set의 정교한 아키텍처와 실무 활용
Redis Sorted Set은 Skip List와 Hash Table의 이중 구조를 통해 O(log N) 성능을 보장하면서도 점수 기반 정렬과 범위 쿼리를 지원하는 고성능 데이터 구조입니다. 2024-2025년 현재, Redis 7.2+에서 30-100% 성능 향상을 달성했으며, 게임 리더보드부터 실시간 분석까지 다양한 분야에서 핵심 기술로 활용되고 있습니다. 특히 대용량 데이터셋에서도 초당 7만 건 이상의 삽입 성능과 마이크로초 단위 지연시간을 제공하여, 실시간 시스템 구축의 필수 요소로 자리잡았습니다.
1. 핵심 개념과 내부 구조
Redis Sorted Set의 혁신적 이중 데이터 구조
Redis Sorted Set은 동일한 데이터를 두 개의 서로 다른 구조에 저장하는 독창적인 접근 방식을 사용합니다. Hash Table은 member → score 매핑을 위한 O(1) 조회를 제공하고, Skip List는 score 기반 정렬 순서를 유지합니다. 이 이중 구조는 빠른 검색과 효율적인 범위 쿼리를 동시에 가능하게 합니다.
Skip List는 확률적 다층 연결 리스트로, 각 레벨에서 span 변수를 통해 건너뛰는 노드 수를 저장합니다. 이를 통해 순위(rank) 계산을 O(log N)으로 최적화하며, 최대 32개 레벨(ZSKIPLIST_MAXLEVEL)까지 지원합니다. 레벨 결정은 0.25 확률의 기하 분포를 사용하여 평균적으로 균형 잡힌 구조를 유지합니다.
메모리 최적화와 임계값 전환
작은 데이터셋(기본값: 128개 요소 미만, 각 64바이트 미만)에서는 Ziplist 인코딩을 사용하여 메모리를 최대 10배 절약합니다. 임계값을 초과하면 자동으로 Skip List 구조로 전환되며, 이때 평균 37바이트의 오버헤드가 발생합니다. Redis 6.2+에서는 ZRANGESTORE 같은 대량 연산 시 예상 크기를 미리 계산하여 처음부터 적절한 구조를 선택하는 최적화가 추가되었습니다.
시간 복잡도 분석
주요 연산의 시간 복잡도는 다음과 같습니다. ZADD와 ZREM은 O(log N), ZSCORE는 Hash Table 덕분에 O(1), ZRANGE는 O(log N + M) (M은 반환 요소 수)입니다. 실제 벤치마크에서는 ZADD가 초당 70,000-100,000회, ZRANGE가 초당 66,000-111,000회의 처리량을 보여줍니다. 이는 단일 스레드 기준이며, 네트워크 오버헤드가 실제 성능에 큰 영향을 미칩니다.
2. 대체 기술과의 심층 비교
Redis vs 관계형 데이터베이스
성능 벤치마크 결과에 따르면, 5,000개 레코드 기준으로 Redis는 쓰기 작업을 1초 미만에 완료하는 반면, MySQL은 400-500개 이후 급격한 성능 저하를 보입니다. PostgreSQL의 경우 업데이트에 10초 이상 소요됩니다. 실제 게임 리더보드를 PostgreSQL에서 Redis로 마이그레이션한 사례에서는 응답시간이 500ms에서 5ms로 100배 개선되었고, 동시 사용자 수용량이 10K에서 100K로 증가했습니다.
관계형 DB는 ACID 트랜잭션과 복잡한 조인 연산이 필요한 경우에 적합하지만, Redis Sorted Set은 실시간 랭킹과 빈번한 점수 업데이트가 필요한 시나리오에서 압도적인 성능 우위를 보입니다.
Redis vs MongoDB
리더보드 성능 비교에서 MongoDB는 p99 레이턴시 350ms, p90 40ms, p50 15ms를 기록한 반면, Redis Sorted Set은 각각 9ms (39배 빠름), 2.5ms (16배 빠름), 1.5ms (10배 빠름)를 달성했습니다. 메모리 사용량 측면에서는 Redis가 MongoDB 대비 약 2배를 사용하지만, 이는 초고속 성능을 위한 트레이드오프입니다.
Redis vs Elasticsearch
RediSearch와 Elasticsearch 벤치마크에서, 5.6M 문서 인덱싱 시 RediSearch가 221초로 Elasticsearch의 349초보다 58% 빠르며, 2단어 검색 쿼리에서 4배 빠른 성능을 보였습니다. 특히 벡터 검색에서는 OpenSearch 대비 최대 52배 높은 QPS와 106배 낮은 지연시간을 기록했습니다.
Redis vs Kafka
Kafka는 수백만 메시지/초의 처리량과 수평 확장이 가능하지만 일반적으로 100ms 미만의 지연시간을 보입니다. 반면 Redis는 제한적 처리량과 메모리 제약이 있지만 마이크로초 단위의 지연시간을 제공합니다. 이벤트 소싱과 대용량 스트림 처리에는 Kafka가, 실시간 상태 관리와 낮은 지연시간이 중요한 경우 Redis가 적합합니다.
3. 성능 특성과 2024-2025 최신 트렌드
메모리와 성능 최적화
Redis Sorted Set은 멤버당 평균 103바이트의 오버헤드 (16바이트 값 기준 6.4배)를 가지며, Skiplist 인코딩 시 엔트리당 37바이트의 추가 오버헤드가 발생합니다. 작은 데이터셋(≤128 elements)에서는 Listpack 인코딩으로 최대 10배 메모리를 절약할 수 있습니다.
대용량 데이터셋 처리 성능은 6백만 요소 기준 초당 70,000회 삽입, 동일 데이터셋에서 초당 40,000회 ZINCRBY, 10개 요소 조회 시 초당 132,718회 요청을 처리합니다. CPU 사용 패턴 분석 결과, 읽기 작업이 쓰기보다 더 많은 CPU를 소모하며, 80% CPU 사용률은 수천 개 키에서 초당 수천 회 읽기와 수백 회 쓰기 시 발생합니다.
Redis 7.2+ 혁신과 Redis 8 전망
Redis 7.2에서는 Sorted Set 성능이 30-100% 향상되었으며, 특히 게임 리더보드 시나리오에서 최적화가 이루어졌습니다. 복제 성능은 최대 18% 빨라졌고, Query Engine 최적화로 최대 16배 향상된 쿼리 처리 성능을 달성했습니다.
2024년 말 출시된 Redis 8 GA는 30개 이상의 성능 개선을 통해 최대 87% 빠른 명령어 실행과 2배의 처리량 증가를 실현했습니다. 특히 AI/ML 워크로드를 위한 Vector Set 데이터 타입이 추가되어, Vector Similarity Search와 Sorted Set의 점수 기반 정렬을 결합한 혁신적인 활용이 가능해졌습니다.
클러스터링과 확장성 도전
Redis Cluster에서 Sorted Set은 단일 키로만 존재하여 자동 샤딩이 불가능한 제약이 있습니다. 16,384개 해시 슬롯을 통한 분산과 해시태그를 활용한 수동 샤딩 전략이 필요하며, 여러 샤드에 걸친 집계 쿼리는 애플리케이션 레벨에서 처리해야 합니다. Read-heavy 워크로드에서는 최대 5개 replica를 활용한 읽기 분산이, Write-heavy 워크로드에서는 파이프라이닝과 Lua 스크립트를 통한 최적화가 권장됩니다.
Serverless Redis의 부상
위와 같은 '클러스터링 & 샤딩'과 같은 제약으로 인해, 이를 자동으로 처리해주는 ElasticCache를 활용해 볼 수 있다.
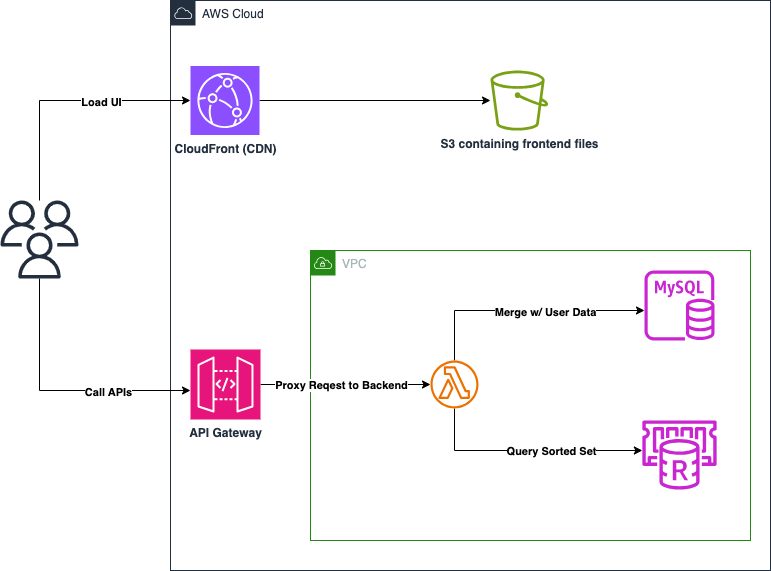
ElastiCache는 Redis OSS에서 직접 처리해야 하는 샤딩, 클러스터링, 페일오버, 백업 같은 복잡한 운영을 AWS가 대신 관리해 줍니다.
Serverless 모드를 사용하면 트래픽에 맞춰 자동으로 규모 확장이 가능해, 게임 순위표나 실시간 랭킹 같은 고트래픽 워크로드에서도 안정적으로 대응할 수 있습니다.
4. 실무 최적화 권장사항
메모리 최적화 전략
설정 최적화를 통해 zset-max-listpack-entries를 128로, zset-max-listpack-value를 64로 설정하여 작은 집합의 메모리 효율을 극대화합니다. 데이터 설계에서는 긴 문자열 대신 ID 참조를 사용하고, ZREMRANGEBYRANK로 정기적으로 오래된 데이터를 제거하며, KEY 레벨 TTL을 활용하여 자동 만료를 구현합니다.
파이프라이닝과 배치 처리
10,000개 명령어 단위의 배치 처리로 5배 성능 향상이 가능하며, 서버 측 응답 버퍼링 부담을 최소화하기 위해 적절한 배치 크기를 유지해야 합니다. Lua 스크립트를 활용한 원자적 연산으로 race condition을 방지하고, Redis Functions를 통해 네트워크 트래픽을 절약할 수 있습니다.
모니터링 핵심 지표
CPU 사용률 80% 초과 시 확장을 고려하고, 메모리 사용률이 물리 메모리 한계에 접근하면 알림을 설정합니다. P99 기준 응답 시간을 지속적으로 모니터링하며, SLOWLOG를 통해 임계값을 초과하는 명령어를 분석합니다. RedisInsight 2024의 메모리 분석기와 실시간 프로파일러를 활용하여 성능 병목을 식별하고 최적화합니다.
5. 결론
Redis Sorted Set은 이중 데이터 구조의 정교한 설계를 통해 실시간 정렬 데이터 처리에서 탁월한 성능을 제공합니다. 2024-2025년 기준으로 Redis 7.2+의 성능 향상과 Redis 8의 혁신적 기능들, 그리고 클라우드 네이티브 Serverless 서비스의 발전으로 더욱 강력해졌습니다.
메모리 사용량과 클러스터 환경에서의 샤딩 제약 같은 한계가 존재하지만, 적절한 최적화 전략과 하이브리드 아키텍처를 통해 이를 극복할 수 있습니다. 특히 게임 리더보드, 실시간 분석, 우선순위 큐, Rate Limiting 등의 시나리오에서 Redis Sorted Set은 여전히 최고의 선택지이며, AI/ML 워크로드와의 통합을 통해 미래 애플리케이션 개발의 핵심 기술로 자리매김하고 있습니다.
- 참고: 리더보드 시스템 설계
추가) 사이드 프로젝트(필사): 명언 데이터 캐싱
최근 진행한 사이드 프로젝트에서는 1년치의 명언 데이터를 DB에 저장하고 날짜별로 조회하는 기능을 제공하고 있습니다. 자주 변경되지 않는 데이터의 특성상, 매번 DB를 조회하는 대신 Redis 캐시를 사용해 응답 속도를 최적화하기로 결정했습니다.
이때, 저는 단순한 Key-Value 구조인 String이나 Hash 대신 Redis Sorted Set을 선택했습니다. 일반적인 캐싱 시나리오에서 사용되는 String이나 Hash는 정렬 기능이 없기 때문에, BETWEEN과 같은 범위 조회를 지원하지 않습니다. 이 구조들을 사용했다면 모든 데이터를 가져와 애플리케션 단에서 날짜별로 필터링해야 하는 비효율이 발생했을 것입니다.
하지만 Sorted Set은 멤버(member)와 함께 정렬 기준이 되는 스코어(score)를 저장하는 구조적 강점을 가지고 있습니다. score는 정수형이면서 시간의 흐름에 따라 증가하는 속성을 가지고 있어, 시간 기반 정렬에 최적화된 스코어 역할을 했습니다.
이러한 구조 덕분에, 저는 ZSetOperations의 rangeByScore와 removeRangeByScore와 같은 Redis 명령어를 활용하여 "오늘부터 일주일치" 같은 특정 기간의 명언을 O(log N + M)의 효율적인 시간 복잡도로 가져올 수 있었습니다. 이는 DB에 의존했을 때 발생할 수 있는 부하를 줄여주면서, 동시에 매우 빠른 응답 속도를 보장했습니다. Sorted Set의 이러한 특성 덕분에, 데이터 정렬이 필요한 조회 시나리오에서 Redis를 효과적으로 활용할 수 있었습니다.
