
내가 모르는거 위주로 정리함
1과목 - 데이터 이해
-
암묵지, 형식지 간 상호작용
1) 공통화: 암묵지를 다른 사람에게 알려줌
2) 표출화: 암묵지 지식을 메뉴얼/문서로 전환
3) 연결화: 교재, 메뉴얼에 새로운 지식 추가
4) 내면화: 교재, 메뉴얼에서 다른 사람의 암묵지를 터득
-
기업 활용 데이터베이스
- OLTP(Online Transaction Processing): 데이터를 거래단위로 수시로 갱신
- OLAP(Online Analytical Processing): 다차원 데이터를 대화식으로 분석
- CRM(Customer Relationship Management): 고객 관련 자료 분석, 마케팅 활용
- SCM(Supply Chain Management): 공급망 연결 최적화
- ERP(Enterprise Resource Planning): 기업 경영 자원 효율화
- RTE(Real Time Enterprise): 최신 정보로 빠른 의사결정 지원
- BI(Business Intelligence): 기업 보유 데이터 정리/분석하는 리포트 중심 도구 -> 의사결정 도움
- BA(Business Analysis): 통계 기반 비즈니스 통찰력
- KMS(Knowledge Management System): 기업의 모든 지식을 포함
-
빅데이터 3V
- Volume(규모) / Variety(다양성) / Velocity(속도)
- Value(가치) / Veracity(신뢰성) / Validity(정확성) / Volatility(휘발성)
-
주요 분석기법
- 유전자 알고리즘: 최적화 필요한 문제의 해결책
- 소셜 네트워크 분석: 사람간의 고나계
- 감정분석: 텍스트데이터에서 감정(긍/부)을 분석
-
위기 요인과 통제 방안
1) 사생활 침해 -> 제공자에서 사용자 책임으로 전환
2) 책임 원칙 훼손(범죄를 예측해서 체포) -> 결과에 대해서만 책임
3) 데이터의 오용 -> 알고리즈미스트 필요
-
데이터 사이언티스트의 필요 역량
1) 하드 스킬: 이론, 코오딩 등등..
2) 소프트 스킬: 스토리텔링, 리더십, 창의력, 호기심, 논리적 비판, 비주얼라이제이션, 커뮤니케이션 등등..
-
빅데이터 가치 패러다임의 변화
1) Digitalization(디지털화)
2) Connection(연결)
3) Agency(관리)
2과목 - 데이터분석 기획
- 분석 대상과 방법
| 대상 O | 대상 X | |
|---|---|---|
| 방법 O | 최적화 | 통찰 |
| 방법 X | 솔루션 | 발견 |
- CRISP-DM 분석 방법론
- 업무 이해 - 데이터 이해 - 데이터 준비 - 모델링 - 평가 - 전개
- 업무 이해: 목적 파악 -> 상황 파악 -> 데이터마이닝 목표 설정 -> 프로젝트 계획 수립
- 데이터 이해
- 데이터 준비
- 모델링: 모델링 기법, 테스트 계획 설계, 모델 작성 및 평가
- 평가: 분석 결과 / 모델링 과정 / 모델 적용성 평가
- 전개
-
빅데이터 분석 방법론
- 분석 기획(Planning)
- 비즈니스 범위 설정 -> SOW(Statement of Works)
- 프로젝트 위험 계획 수립 -> 회피 / 전이 / 완화 / 수용
- 데이터 준비(Preparing)
- 필요 데이터 정의
- 데이터 스토어 설계
- 데이터 수집 및 정합성 점검
- ETL(Extract, Transform, Load): 데이터 추출, 변환, 적재
- 데이터 분석(Analyzing)
- 분석용 데이터 준비
- 텍스트 분석
- 탐색적 분석
- 모델링
- 모델 평가
- 모델 적용 및 운영방안 수립
- 시스템 구현(Developing)
- 평가 및 전개(Deploying)
- 분석 기획(Planning)
-
하향식 접근 방법
- 문제 탐색
- 비즈니스 모델 캔버스 단순화 측면: 업무 / 제품 / 고객 / 규제와 감사 / 지원인프라
- 관점
- 거시적: STEEP(사회, 기술, 경제, 환경, 정치)
- 경쟁자 확대: 대체자, 경쟁자, 신규 진입자
- 시장의 니즈 탐색: 고객, 채널, 영향자
- 문제 정의
- 해결 방안
- 타당성 검토
- 경제적 타당성: 비용대비 편익(ROI) 분석
- 데이터 타당성: 데이터 존재 여부, 분석 역량
- 기술적 타당성
- 문제 탐색
-
분석 과제에서 고려해야 할 5가지 요소
- 데이터 크기
- 속도
- 데이터 복잡도
- 분석 복잡도
- 정확도 / 정밀도 ( 서로 trade-off 관계)
-> 분석 방법은 고려 x!!!!!
-
데이터 분석 프로젝트의 우선순위 선정 기준
- 시급성 중요시: 현재 쉬움 -> 미래 쉬움 -> 미래 어려움
- 난이도 중요시: 현재 쉬움 -> 현재 어려움 -> 미래 어려움
-
데이터 분석 수준 진단
-
분석 준비도
- 분석적 업무파악
- 인력 및 조직
- 분석 기법
- 분석 데이터
- 분석 문화
- IT 인프라
-
분석 성숙도
단계 도입 활용 확산 최적화 비즈니스 부문 - 실적 분석 및 통계
-정기 보고 수행
- 운영 데이터 기반-미래결과 예측
- 시뮬레이션
- 운영 데이터 기반- 전사성과 실시간 분석
- 프로세스 혁신
- 분석규칙/이벤트 관리- 외부환경 분석 활용
- 최적화 업무 적용
- 실시간 분석
- 비즈니스 모델 진화조직 및 역량 부문 - 일부 부서에서 수행
- 담당자 역량에 의존- 전문담당부서 수행
- 분석 기법 도입
- 관리자가 분석 수행- 전사 모든 부서 수행
- 분석 COE 운영
- 데이터사이언티스트 확보- 데이터 사이언스 그룹
- 경영진 분석 활용
- 전략 연계IT 부문 - 데이터 웨어하우스
- 데이터 마트
- ETL/EAI
- OLAP- 실시간 대시보드
- 통계분석 환경- 빅데이터 관리 환경
- 시뮬레이션/최적화
- 비주얼 분석
- 분석 전용 서버- 분석 협업 환경
- 분석 샌드박스
- 프로세스 내재화
- 빅데이터 분석
-
- 분석조직(DSCoE)
- 집중 구조: 독립적 전담 조직 구성(중복 업무 가능성 존재)
- 기능 구조: 해당 부서에서 직접 분석(DSCoE 없음)
- 분산 구조: 분석 조직 인력을 현업 부소에 배치
3과목 - 데이터분석
-
확률적 표본 추출 방법
- 랜덤 추출: 무작위로 표본 추출
- 계통 추출: 번호 부여, 일정 간격으로 추출
- 집락 추출: 여러 군집으로 나누고 군집 선택(군집 내 이질적, 군집 간 동질적)
- 층화 추출: 모집단을 서로 겹치지 않는 층으로 나누고 각 층에서 표본 추출(군집 내 동질적, 군집 간 이질적)
- 복원/비복원 추출
-
비확률적 표본 추출 방법
- 편의 추출: 연구자가 편한 대로 임의 추출
- 의도적 추출: 연구자가 특정 기준을 정하고 추출
- 할당 추출: 특정 기준으로 나눈 후, 그 그룹에서 할당된 수 만큼 추출
- 눈덩이 추출: 초기 응답자로부터 새로운 응답자를 추천받음
- 자기선택 추출: 응답자가 스스로 조사에 참여할지 결정
-
공분신과 독립성의 관계
- 두 변수가 독립 -> 공분산=0
- 역은 성립 X
-
왜도
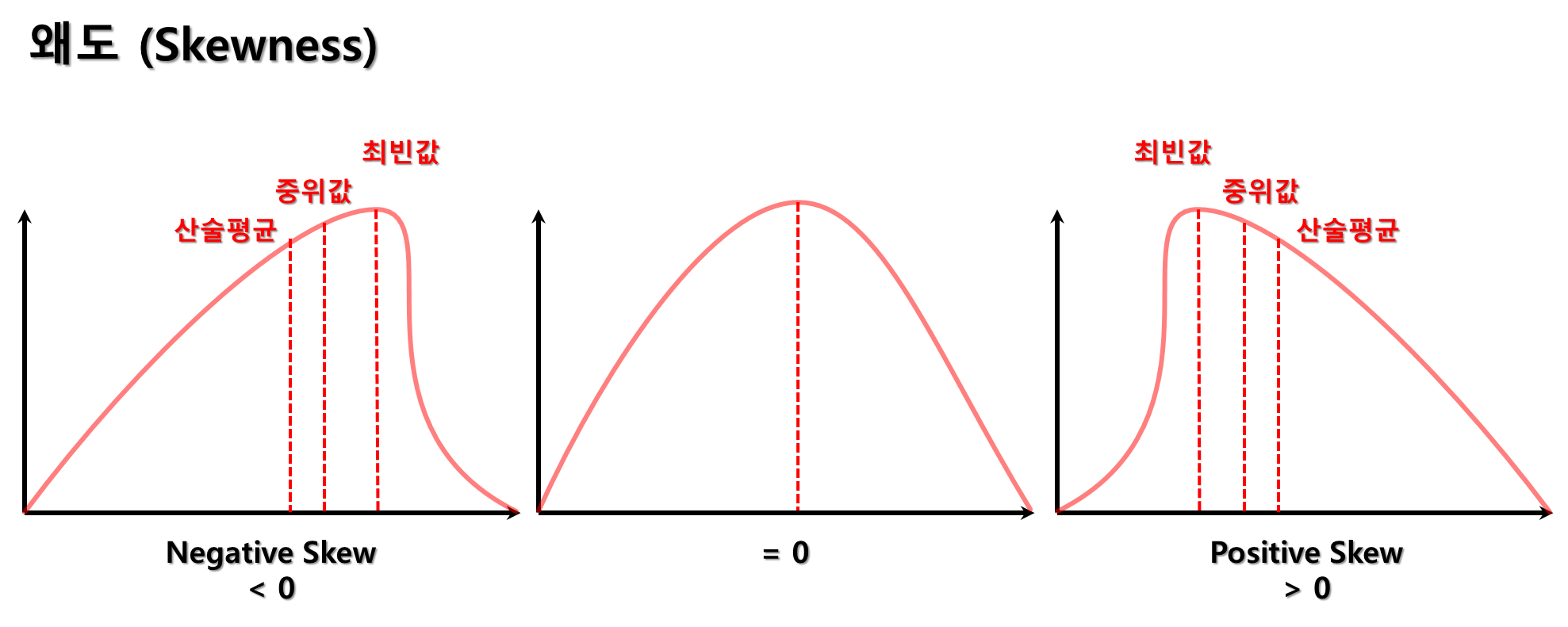
-
가설검정
- 유의수준(): 1종 오류를 범활 확률(p-value)의 허용 한계
- 검정력(): 귀무가설이 거짓일 때 귀무가설을 기각하는 확률 => 1 - 2종오류를 범할 확률
- 1종 오류: 귀무가설이 참일 때 귀무가설을 기각
- 2종 오류: 귀무가설이 거짓일 때 귀무가설을 수용
-
로지스틱 회귀
- 최대우도추정법(MLE)를 통해 모델 탐색
- 독립변수에 대한 가정 불필요
- 로짓변환을 통해 곡선을 직선 형태로 변환
- 회귀계수의 해석을 위해서는 변환(오즈비..?) 필요
-
상관분석
- 피어슨 상관분석
- 양적 척도(등간척도, 비율척도), 연속형 변수
- 선형관계의 크기 측정
- 스피어만 상관분석
- 서열 척도, 순서형 변수
- 선형/비선형적 관계 크기 측정
- 두 변수가 선형관계가 아니더라도 1/-1이 될 수 있다
- 피어슨 상관분석
-
시계열 분석
-
정상성
- 모든 시점에 일정한 평균과 분산을 가져야 함
- 공분산은 시점이 아닌 시차에 의존
- 차분: 현시점의 자료에서 이전 값을 뺌
- 이동평균법: 일정 기간의 평균
- 지수평활법: 최근 데이터에 가중치 부여
-
모형
1) 자기회귀AR(p)- 부분자기상관함수(PACF) 활용
2) 이동평균MA(q) - 자기상관함수(ACF) 활용
3) 자기회귀누적이동평균ARIMA(p,d,q) - d는 정상화 시에 몇 번의 차분을 했는지에 관한 숫자(d=0 이면 ARMA 모델)
- 부분자기상관함수(PACF) 활용
-
분해시계열: 시계열에 영향을 주는 일반적 요인을 시계열에서 분리해 분석하는 방법
- 추세 / 계절 / 순환 / 불규칙 요인
-
- 의사결정나무
- 노드 내 동질적, 노드 간 이질적으로 분리
- 카이제곱 통계량: 분류 문제에서 CHAID 알고리즘 활용 시 사용
- 지니지수(): 분류 문제에서 CART 알고리즘 활용 시 사용
- 엔트로피지수(): 분류 문제에서 C4.5/C5.0 알고리즘 활용 시 사용
- 앙상블
1) 보팅- 다수결 방식으로 최종 모델 선택
- 복원추출 기반으로 붓스트랩 생성, 모델 학습 후 보팅으로 결합
- 잘못된 분류 데이터에 큰 가중치
- AdaBoost, XGBoost(규제 포함)
- GBM, LGBM(leaf-wise / 학습속도 개선)
- 얘만 병렬처리 불가
- 각각의 모델에서 학습한 예측 결과를 다시 학습
- 배깅+의사결정트리
- 성능 좋고 이상치에 강함
- 활성화함수
1) 시그모이드- 0~1 사이의 값
- -1~1 사이의 값
- 시그모이드의 기울기 소실 문제 개선
- 다중 분류 문제에서 사용
- 확률의 총합이 1
-
분류모델 평가지표

-
F-1 score
-
출처
- 유선배 데이터분석 준전문가 ADsP 합격노트 아마 2023버전
- 인터넷 검색해서 나온 사진들....
